- Parasitic Extraction 및 Metal Layer Stack Rc Extrac
- Vlsi Cad Rents Rule이란
- 싱가포르 여행기 뉴턴 맥스웰 호커 푸드 센터
- 내가 보려고 만든 반도체 자료 모음집 반도체 검색 꿀팁
- 2025 신년사 반도체로 빛나는 대한민국의 새 아침
- 과학기술정책 Bio Tech 곧 Gdp 대비 의료비 20 비율의 시대가 옵니다
- 과학기술조직론 과학기술 스타트업 창업 후 운영 방안
- 제 2차 세계대전과 미국의 과학기술 발전 Mit Rad Lab 오펜하이머 Los Alamo
- 과학기술조직론 Team Building
- 부자와 Stem 엘리트들 한국 탈출 이유
- 메리크리스마스 이웃 여러분 모두 감사합니다 100도 인사
- 미국 과학기술 정책 Ffrdc 모델과 Pipeline 모델
- Darpa Defense Advanced Research Projects Agency 미국
- 과학기술 이념 정리 미국은 어떻게 과학기술 강대국이 되었는가
- 과학기술정책 현대 경제성장은 어디에서 올까
- 과학기술정책 과학 기술 차이 발명 혁신 차이
- Vlsi 설계 가이드 Global Routing이란 Detailed Routing이란
- Vlsi Physical Design에서 Routing이란 Global Routing De
- 반도체 설계 검증 Routing Congestion의 Estimation과 Optimiza
- 반도체 산업 서적 추천 현재를 이해하고 미래를 예측하기 위한 반도체 교양필수
- 반도체 엔지니어 커리어 관리 반도체 슈퍼 사이클을 따라서
- 반도체 설계 검증 취업 하는법 조언
- 개발자 엔지니어 선물 추천 Whats On My Desk 내가 엔지니어로써 느끼는 사무실의
- Vlsi Physical Design에서 Power Ring이란 Power Stripe란
- 2024 마이 블로그 리포트 데이터로 찾아보는 내 블로그 마을
- 디지털 반도체 설계 엔지니어들은 회사에서 무엇을 할까
- Vlsi Physical Design에서 Bound란
- Stem Consulting Semiconductor 반도체 취업이직고민 상담 받습니다
- Autodesk 오토캐드 싸게 사용하는법 1999 공유계정
- Auto Pr Placement Blockage란 Vlsi Physical Design
AI Accelerator란? 인공지능 가속기란? NPU란?
AI Accelerlator란?
AI 가속기는 신경망과 같은 AI 작업의 효율적인 처리를 위해 전용 반도체로 설계된 고성능 병렬 컴퓨팅 머신입니다.
전통적으로는 반도체 설계 비용이나 공정 비용이 너무 높았기 때문에 범용 반도체로 게이밍 PC에도 쓰고, 코인 채굴도 하고, 인공지능 학습도 하였습니다.
AI라는것에 A를 보면 Artificial입니다. 인공적으로.. 그러니까 사람이 뭔가 만든건데요.
Artificial Neural Network입니다. 뇌 속의 뉴런 신경망을 소프트웨어 레벨에 모방해서 만든겁니다.

그래서 인공지능을 학습시키고.. 모델 만들어서 추론시켜서 결론 만들고.. 이런 작업을 합니다.
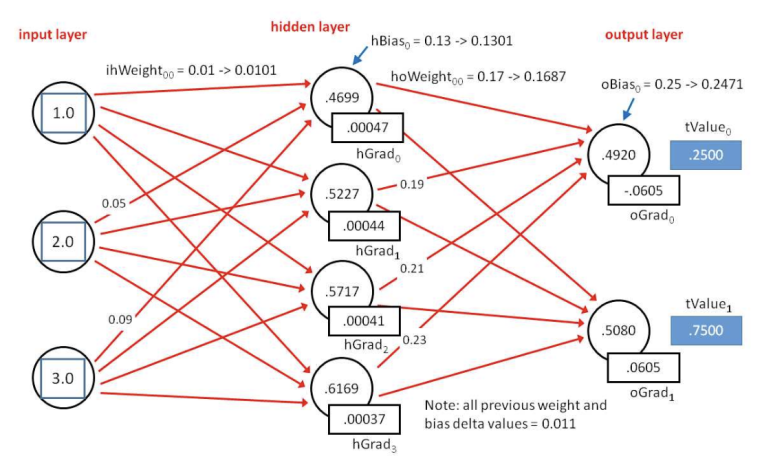
소프트웨어 업계에서는 훨씬 높은 성능과 낮은 전력을 갖고 경쟁합니다.
그리고 범용 반도체는 맥가이버칼처럼 모든 곳에 쓸 수 있지만, 전기톱보다는 나무 자르는 속도가 늦죠.
현재는 인공지능 Inference Chip이 대세가 되고 있습니다.
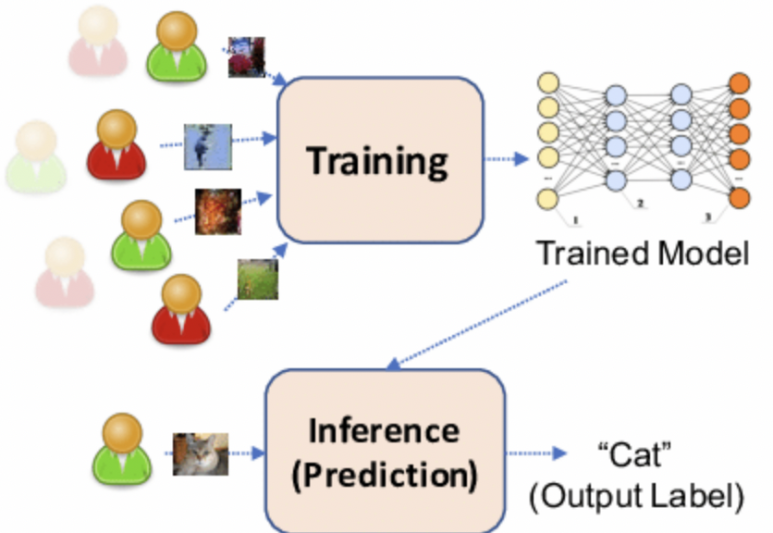
AI Accelerator는 인공지능 작업을 위해 설계된 반도체라고 보시면 됩니다
-
Google은 자사 Cloud에 맞춤화한 “Tensor Processor Unit”
-
Amazon도 자사 Cloud에 맞춤화한 “Graviton4” 를 설계합니다.
-
NVIDIA는 LLM 및 Data center에 특화된 H100, B200 등을 설계합니다.
좀 더 기술적인 이야기를 해보면, 소프트웨어 설계에서 컴퓨터 과학자들은 특정 문제에 맞는 알고리즘 접근법을 개발하고 이를 높은 수준의 절차적 언어로 구현하는 데 집중했습니다.
2020년까지는 그래서 SW엔지니어들이 잘 나간 것 같습니다.
“암달의 법칙” 아래에서 알고리즘을 멀티스레딩을 치고, 소프트웨어에서 여러가지 기교를 부려도 대규모 병렬 처리를 달성하기는 어려웠습니다.
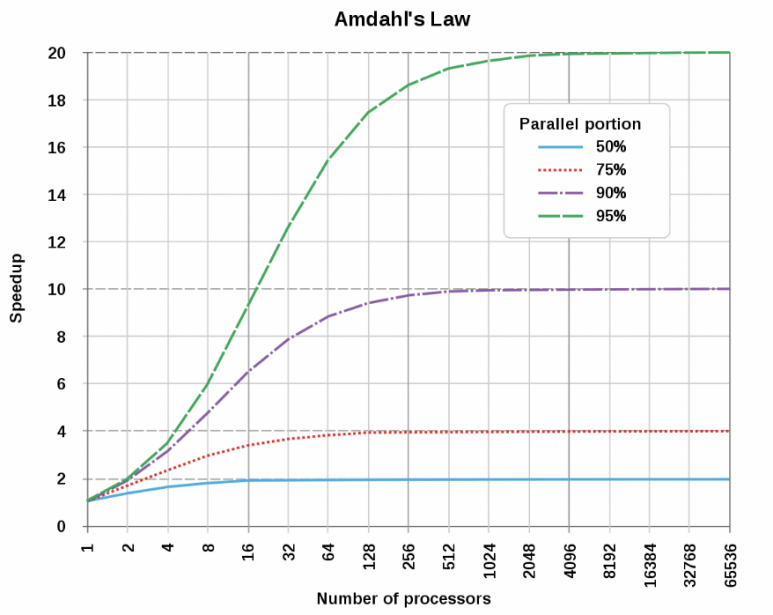
소프트웨어 엔지니어들은 “맥가이버 칼로 어떻게 나무를 빨리 벨 수 있을까??” 이런 것을 연구했고, 하드웨어 엔지니어들은 “전기톱을 만들었어요.”
감이 안 잡힐 수 있을테니, 인공지능 반도체의 극단적인 사례인 “Cerebras”의 인공지능 반도체를 보겠습니다.
웨이퍼만한 Chip 하나가 인공지능 반도체입니다. 8inch * 9inch 사이즈.
써있는 것처럼, 1.2조개의 트랜지스터 + 40만개의 AI Core (WSE-3 모델의 경우 90만개임.)

DFT 엔지니어들 퇴근 못 했겠다….ㅜㅜ참고로 Cerebras의 칩은 AI Chip의 극단적 예시를 보여준 것이고, NVIDIA의 칩은 아래 정도 크기입니다.
Cerebras는 극단적으로 병렬화에 집중했습니다. 그리고 DRAM 대신 SRAM을 메인으로 채택했습니다.
그러다보니 칩 수율 높이기 매우 까다롭고, 단위 칩이 너무 비싸고,칩간 인터커넥트가 까다롭죠.
병렬작업을 아무리 잘한다해도, “소프트웨어 엔지니어들이 이정도의 병렬 작업을 원하진 않을 수 있습니다.”

NVIDIA는 HBM을 메인으로 채택했기에 훨씬 더 큰 용량의 작업을 할 수 있고, 인터커넥트 장인 기업 답게, Cerebras보다 훨씬 빠른 칩 간 인터커넥트 속도를 갖고 있습니다.
칩 설계에서 가장 중요한 것 중 하나가 “스펙 선정”인데, NVIDIA는 이런 것들을 참 잘하는 것 같습니다.
시장의 수요와 물리학적인 기술력을 잘 고려해서 Chip 스펙을 선정하고.. RTL 설계하고… Constraint 작성하고.. Floorplan하고.. 이런 것들 하나 하나 최고의 회사답게 “모든 설계 파라미터를 최적으로 설계합니다.”
이게 정말 어려워요. 반도체를 아무리 빠르게 양산하려고 해도 2년정도 기간이 소요됩니다. 그런데 소프트웨어 시장은 매달 대세 알고리즘이 바뀝니다. 2년 후에 잘나갈 소프트웨어 알고리즘을 겨냥해서 반도체를 설계한다는게… 정말 어렵습니다.
2년 후 미래를 보고 올 수 있다면, 로또번호를 외우고 오지말고… 잘 나갈 알고리즘을 하나 외워오십쇼.ㅎㅎ
덕분에 어지간한 “전용 반도체” 만드는 회사보다 더 좋은 반도체를 설계합니다.
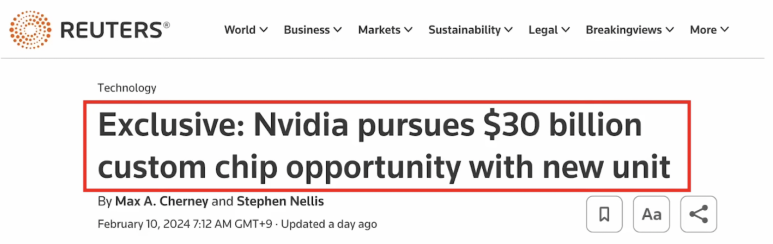
이런 엔비디아가 앞으로는.. “전용 반도체” 팀을 준비한다는 소문이 있습니다.
AI Accelelator는 어쨌든 TensorFlow, PyTorch 같은 와 같은 High-level language Framework로 돌아갈테니, 다양한 AI 가속기 간의 연결을 용이하게 하기 위해 호환성을 지원하는 머신 러닝 컴파일러가 등장하고 있습니다. 대표적인 예로 Facebook Glow 컴파일러가 있습니다.
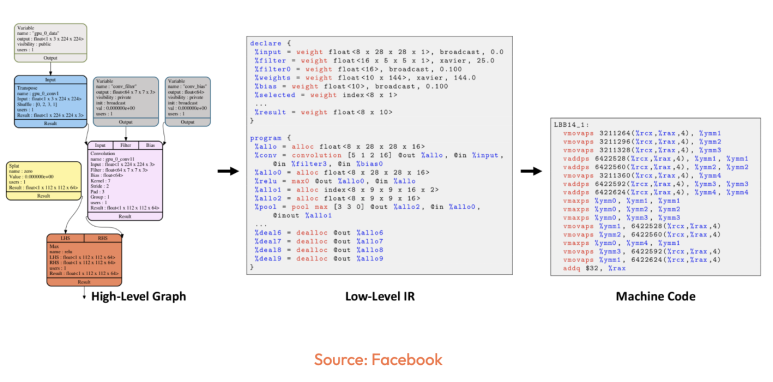
아, 그리고 인공지능 반도체라는게 꼭 데이터센터향은 아닙니다.
앞으로는 “온디바이스” 혹은 “엣지”라고 불리는 반도체의 세상이 올 것이라고 믿습니다.
그런데 인공지능 작업이라는게 엄청난 메모리 할당 + 병렬작업이 필요하기 때문에… 칩을 작게 만들기가 쉽지 않습니다.
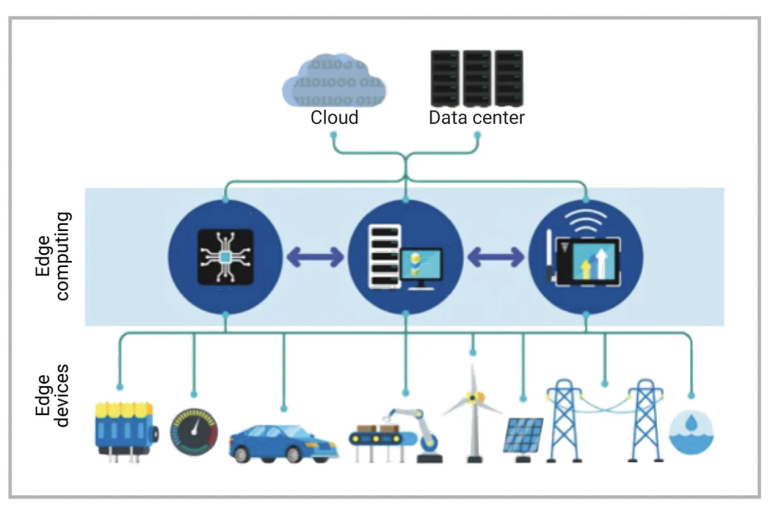
ref: Semiconductor engineering그래서 무거운 AI 작업들은 데이터센터에서 처리하고, SW업계에서 “Tiny model”들을 발전시킨 시점에야 온디바이스 칩들이 비로소 활약을 할 것 같습니다. 현재도 “통번역” 수준에서는 온디바이스 칩들이 잘 나가고 있지만, Chat GPT LLM처럼 매우 큰 작업의 인공지능 작업을 작은 칩에서 하려면… 전력소모도 매우 크고 레이턴시도 클겁니다.
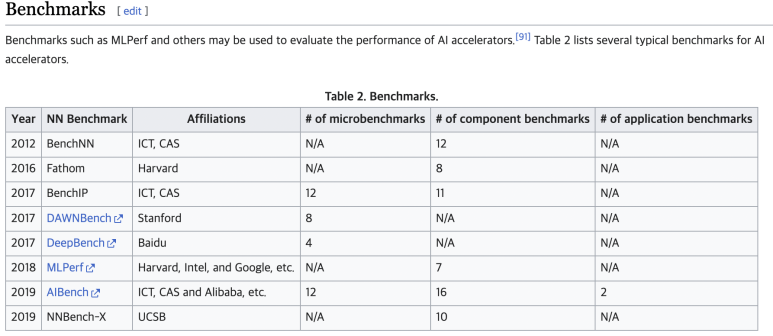
MLPerf란?
현대 가장 공신력 있는 AI accelerlator benchmark 기관입니다.
학계, 연구소 및 업계의 AI 리더 컨소시엄인 MLPerf™ 벤치마크는 하드웨어, 소프트웨어 및 서비스에 대한 교육 및 추론 성능에 대한 벤치마크를 만듭니다.
해시태그 :