

TL;DR
- Shannon expansion은 Boolean function을 MUX 한 개로 분해하는 공식이다.
- cofactor는 “변수 하나를 0/1로 고정한 새 function”이며, 그래서 해당 변수는 cofactor 안에서 사라진다.
- Boolean difference는 “입력 x를 뒤집었을 때 출력이 바뀌는가?”를 계산하는 sensitivity function이다.
- ∃(existential) quantification은 “아무 해 하나만 존재하면 됨”을 수식으로 만든 연산이고, 이게 SAT의 핵심이다.
- Optimization이 어려운 이유: SAT는 하나만 찾으면 끝, Optimization은 모든 후보를 비교해야 한다.
1. 문제의식: Karnaugh map이 깨지는 순간
1.1 40 variables면 Karnaugh map은 끝
- 2^40 규모 → “그릴 수는 있어도 쓸 수 없다”
- 결론: Boolean function을 손으로가 아니라 data structure + operator로 다뤄야 한다.
1.2 이 글이 노리는 3가지
- decomposition (쪼개기)
- computation (프로그램이 다룰 수 있는 표현)
- application (EDA에서 바로 쓰는 연산)
2. Shannon cofactor: “변수 고정”이 만들어내는 새 function
2.1 정의: cofactor는 substitution이다
- f의 입력 변수 x에 대해
- positive cofactor: ( f_{x} = f(x=1) )
- negative cofactor: ( f_{~{x}} = f(x=0) )
2.2 핵심 포인트: “새 function이며, x가 사라진다”
- x를 0/1로 고정했으니, 결과에는 더 이상 x가 등장할 수 없음.
- 이걸 놓치면 이후 Boolean difference / quantification이 다 무너짐.
2.3 (짧은 예시)
- 예: ( f(x,y,z) = xy+x~z+~xyz )
- ( f(x=1) = y + \bar{z} ) (단순화 가능)
- ( f(x=0) = yz )
3. Shannon expansion: “Boolean function = MUX”로 보는 순간 끝난다
3.1 정리 (Shannon expansion theorem)
어떤 f와 어떤 변수 x에 대해서도:
f=x⋅f(x=1)+~x⋅f(x=0)
3.2 하드웨어 관점: Shannon expansion = 2:1 MUX
- select = x
- data1 = f(x=1)
- data0 = f(x=0)
- output이 곧 f
📌 여기서 “브랜치(branch)” 감각이 생김:
- x=0 브랜치로 내려가면 f(x=0)만 보면 됨
- x=1 브랜치로 내려가면 f(x=1)만 보면 됨
3.3 MUX tree = recursive decomposition
- 변수 하나 → 2개 브랜치
- 변수 두 개 → 4개 브랜치
- k개 변수 → 2^k 브랜치
- 이게 “열거”처럼 보이지만, EDA는 여기서 pruning을 한다. (뒤에서 설명)
[Figure 1] Shannon expansion을 2:1 MUX로 그린 그림
[Figure 2] 2-variable expansion이 4개의 leaf를 만드는 MUX tree 그림
4. cofactor는 “연산이 교환된다”: 계산이 쉬워지는 이유
4.1 아주 중요한 성질
- complement:
- (~f)x=~(𝑓𝑥)
- AND/OR/XOR도 동일하게 “cofactor 먼저 → 연산 나중” 가능
- (𝑓∧𝑔)𝑥=𝑓𝑥∧𝑔𝑥
즉, 큰 식을 만들고 cofactor 하는 게 아니라
cofactor를 먼저 해서 식을 작게 만든 뒤 계산한다.
5. Boolean difference: “민감도(sensitivity)”를 수식으로 만든 것
5.1 정의
∂f/∂x=f(x=1)⊕f(x=0)
5.2 의미: “x를 flip했을 때 출력이 바뀌는 조건”
- XOR는 “다르면 1”
- 따라서 Boolean difference가 1인 입력 패턴에서는:
- x를 0→1 또는 1→0 바꾸면 f가 반드시 바뀜
5.3 예시로 감 잡기
- inverter: f=~x
- 𝑓(1)=0,𝑓(0)=1⇒∂𝑓/∂𝑥=1
- 항상 민감
- AND: ( f=xy )
- 𝑓(1)=𝑦,𝑓(0)=0⇒∂𝑓/∂𝑥=𝑦
- y=1일 때만 x 변화가 출력에 영향
- OR: ( f=x+y )
- 𝑓(1)=1, 𝑓(0)=𝑦 ⇒ ∂𝑓/∂𝑥=~𝑦
- y=0일 때만 영향
5.4 “x가 F에 논리적 영향 없다?”의 정확한 해석
- “항상 영향 없다”는 뜻이 아님.
- 특정 입력 조건에서 영향이 없을 수 있다는 뜻.
- 그 조건을 딱 뽑아주는 게 Boolean difference.
[Figure 3] AND/OR에서 Boolean difference가 왜 y / ȳ가 되는지 게이트 그림
6. Quantification: “변수 제거”를 목적 함수로 만든 연산
6.1 existential quantification (∃): “아무 해 하나만 있으면 됨”
∃xf=f(x=0)∨f(x=1)
- 의미: 다른 입력이 고정됐을 때, x를 잘 고르면 f=1이 되는가?
6.2 universal quantification (∀): “모든 경우에 성립해야 함”
∀xf=f(x=0)∧f(x=1)
- 의미: x가 뭐든 상관없이 항상 f=1인가?
6.3 네가 말한 문장과 1:1 대응
“모두 열거할 필요 없이, 아무 해 하나만 찾으면 되니깐”
이게 정확히:
∃ quantification
- 그리고 SAT의 핵심 형태:∃X:F(X)=1
7. SAT vs Optimization: 왜 “최적화”가 더 빡센가
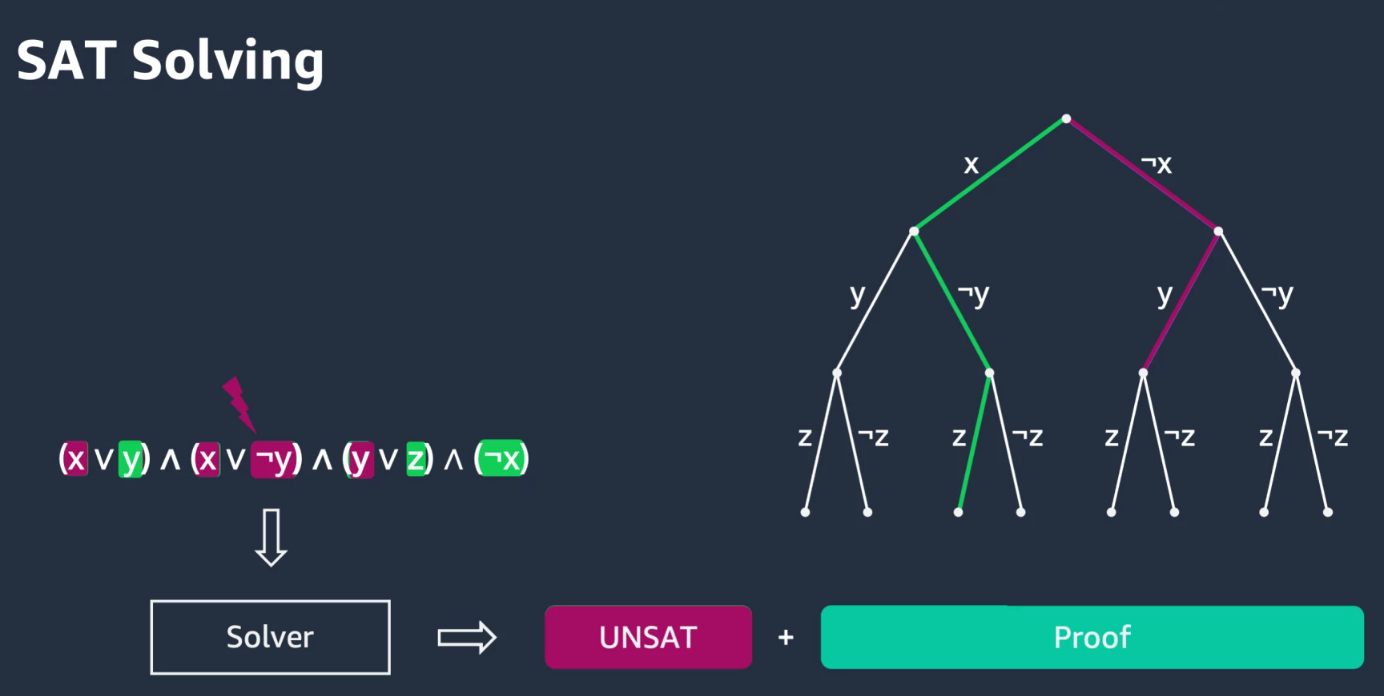
7.1 SAT는 “하나만 찾으면 끝”
- 조건 만족 해가 존재하면 끝
- 브랜치 탐색 중에 하나라도 만족하면 종료 가능 (pruning)
7.2 Optimization은 “비교가 본질”
- 더 좋은 해가 있는지 증명하려면
- 다른 브랜치들도 계속 봐야 함
- 그래서 EDA 최적화가 구조적으로 어렵다 (NP-hard 얘기로 연결 가능)
[Figure 4] SAT는 첫 만족에서 stop, Optimization은 계속 탐색하는 트리 그림
다음 강의로 자연스럽게 연결: Tautology와 URP
8.1 tautology는 “항상 1인가?”
- f≡1?
- 핵심 아이디어: f가 tautology ⇔ f(x=0)와 f(x=1)도 둘 다 tautology
8.2 URP의 직감
- Shannon cofactor로 분해(브랜치)
- unate 같은 조건이면 중간에서 바로 종료(강한 pruning)
- 결국 “열거”가 아니라 “버릴 건 빨리 버리는 알고리즘”이 됨
이 글에서 반드시 가져가야 하는 5개
- cofactor는 substitution이며, 결과 function에서 해당 변수는 사라진다
- Shannon expansion은 수식이면서 동시에 2:1 MUX 모델이다
- Boolean difference는 “x 변화가 출력에 영향 주는 조건”을 주는 function이다
- ∃ quantification은 “하나만 있으면 됨”을 OR로 구현한다
- SAT는 하나면 끝, Optimization은 비교 때문에 더 오래걸린다


