
![[VLSI CAD] BDD vs SAT: EDA에서 Boolean function을 “표현”할 것인가, “풀” 것인가](https://images.unsplash.com/photo-1635372722656-389f87a941b7?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fG1hdGh8ZW58MHx8fHwxNzc3NDYyMDY3fDA&ixlib=rb-4.1.0&q=80&w=1200)
TL;DR
- BDD(특히 ROBDD) = Boolean function의 canonical representation(variable ordering이 고정되면 “딱 하나의 그래프”)을 만든다. 그래서 equivalence checking이 “root pointer 비교”로 끝나는 장점이 있다.
- SAT = Boolean function을 다 표현하지 않고, “SAT/UNSAT만” 빠르게 판정하고 한 개 satisfying assignment(counterexample)을 뽑는 쪽에 최적화되어 있다. 실무에서 “그냥 풀기(just solve it)”는 SAT가 BDD를 많이 밀어냈다.
- 현실 트레이드오프는 깔끔하다:
- BDD는 SPACE(메모리) 가 터질 수 있고
- SAT는 TIME(탐색 시간) 이 터질 수 있다
1) BDD의 출발점: “decision”을 그래프로 들고 다니기
BDD는 결국 “변수 하나 고르고(분기), 0/1로 내려가며 답(leaf)에 도달”하는 decision graph다. 핵심 제약은 Ordered: 모든 path에서 변수가 정해진 순서로만 등장하고, 한 path에서 같은 변수를 두 번 보지 않는다. (중간 변수를 skip 하는 건 가능)
이 한 줄이 엄청 중요하다. “ordered”가 있어야, 그 다음에 나오는 reduction으로 canonical form까지 간다.
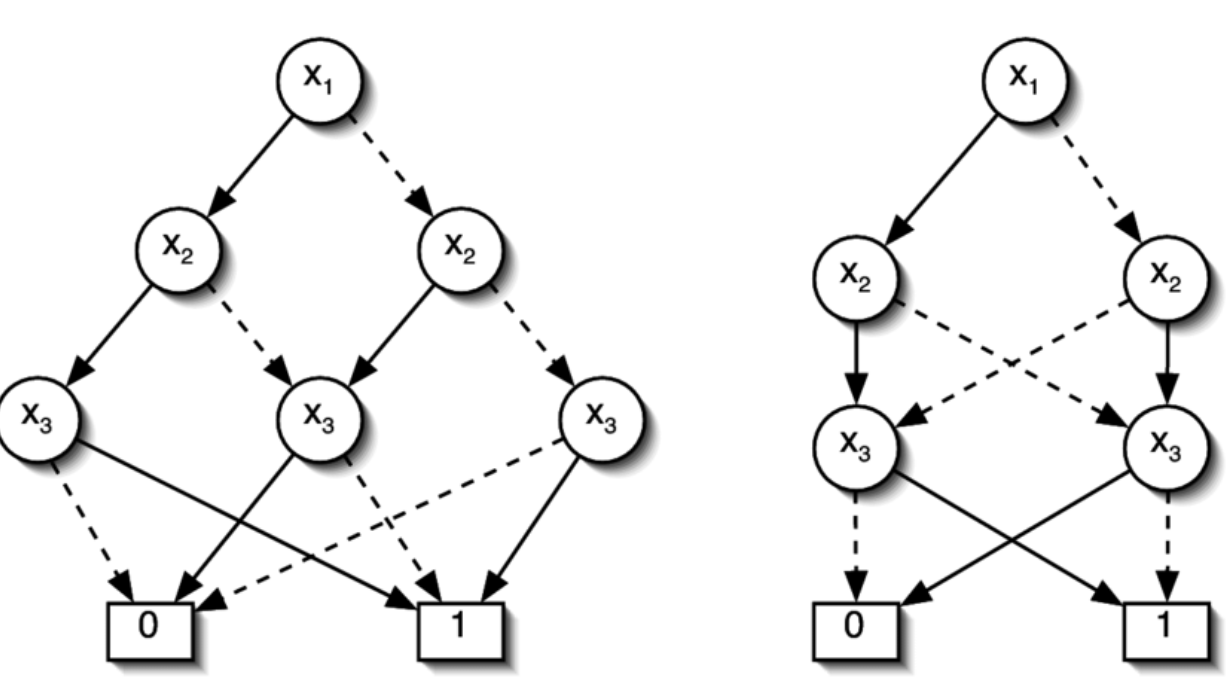
2) ROBDD로 만드는 3개의 Reduction Rule (이게 본체)
BDD를 “Reduced Ordered BDD(ROBDD)”로 만들기 위해 그래프 중복을 제거한다. 목표는 두 가지:
- graph size를 줄이고
- 같은 function이면(같은 variable order일 때) 그래프가 유일하도록 만드는 것
Rule 1) Merge equivalent leaves
0 leaf는 하나, 1 leaf도 하나만 남긴다. 나머지 leaf로 들어오던 edge는 전부 그 하나로 redirect.
Rule 2) Merge isomorphic nodes
같은 variable을 테스트하고, child가 “물리적으로 동일한 노드”(same pointers)인 두 노드는 구분 불가능이다 → 하나로 합친다.
Rule 3) Eliminate redundant tests
어떤 variable node에서 low child == high child면, 그 variable을 테스트할 이유가 없다 → 그 node를 제거하고 child로 bypass.
이 3개를 적용하면 결론:
- 같은 function은 같은 ROBDD 그래프가 된다(같은 ordering 가정).
- 그래서 Boolean function은 “그래프”가 아니라 사실상 root node pointer 하나로 표현된다.
3) BDD가 verification에서 좋은 이유: equivalence가 O(1)
ROBDD에서는 “function equality”가 보통 생각하는 것처럼 진리표 비교가 아니다.
- F에 대한 ROBDD 만들고
- G에 대한 ROBDD 만들고
- root pointer가 같으면 F==G
이게 canonical representation의 힘이다.
그리고 “어떤 input에서 다르냐?”도 쉽게 간다:
- H = F ⊕ G 를 만들고
- H가 satisfiable이면 그 path가 곧 counterexample
4) 실무 구현 관점: “netlist를 걸어가며 operator를 누적”
BDD는 보통 gate-level network를 따라가며 쌓는다. input var부터 만들고, gate마다 AND/OR 같은 BDD operator로 새로운 BDD를 만든다.
예: T1 = And(A,B), Out = Or(T1,T2) 같은 스크립트 방식
중요한 구현 포인트는 딱 하나:
- 각 operator가 입력 BDD가 shared + reduced + ordered이면 출력도 그렇게 되게 만들어야 한다
(이게 보통 unique table / computed table 같은 엔지니어링으로 구현된다)
5) Multi-rooted BDD sharing: “한 개만 하지 말고 여러 개를 같이 줄여라”
BDD는 “여러 function”을 따로 만들면 손해다. 같은 subgraph를 공유할 수 있는데, root를 여러 개 두고 하나의 큰 DAG로 공유하면 size가 확 줄어든다.
Adder 예시에서 separate vs shared node count 차이가 크게 난다(64-bit에서 특히).
6) BDD로 쉬워지는 것들
- Satisfiability: “root에서 1 leaf로 가는 path가 하나라도 있으면 SAT, 그 path가 assignment”
- Tautology checking: BDD 만들고 “graph == 1”이면 끝
BDD는 “표현을 만들어놨기 때문에” 이런 질의들이 깔끔하다.
7) BDD의 단점: variable ordering 하나로 linear ↔ exponential
BDD가 “너무 좋아 보이는” 이유는, 잘 되는 케이스만 보면 그렇다. 문제는 ordering이다.
같은 function이라도 ordering이 나쁘면 node 수가 exponential growth로 터진다.
그래서 BDD 세계의 본질은 사실 “좋은 ordering 찾기” 싸움이다.
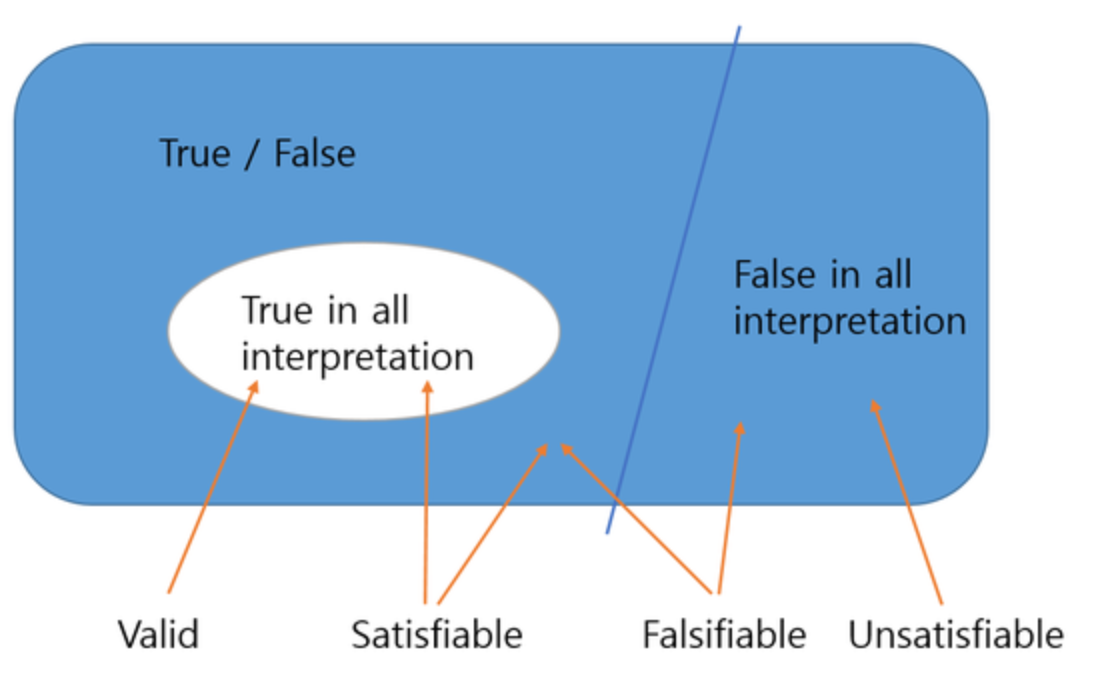
8) SAT: “표현”보다 “판정 + 한 방 해”에 집중
SAT 정의는 단순하다:
- 변수들에 값을 넣어서 F()=1이 되게 하는 assignment를 찾거나
- 그런 assignment가 없음을 증명(UNSAT)
그리고 SAT solver가 먹기 좋은 표준 입력이 CNF(Conjunctive Normal Form) 다.
9) DPLL의 뼈대: DECISION + DEDUCTION (그리고 recurse)
SAT solving의 큰 흐름은 이것뿐이다:
- DECISION: 어떤 variable을 골라 값을 찍고, formula를 단순화
- DEDUCTION: 단순화된 clause 구조를 보고 더 강제되는 assignment를 계속 유도
- 더 이상 진전 없으면 다시 DECISION으로 recursion
DEDUCTION을 현실적으로 굴리는 핵심이 BCP(Boolean Constraint Propagation), 그중 가장 유명한 규칙이 Unit Clause Rule이다:
- clause에 unassigned literal이 딱 하나만 남으면, 그 literal은 강제로 정해진다(implication).
10) Gate-level → CNF: “gate마다 local constraint를 붙여라” (Tseitin 스타일)
많은 사람이 “CNF 만들려면 Boolean algebra로 POS 변환해야 하나?”를 먼저 떠올린다. 실무는 다르게 간다:
- netlist의 각 gate 출력에 내부 변수(z 같은 것)를 두고
- gate마다 gate consistency function을 CNF clause로 추가한다
- 전체 CNF는 그냥 이 clause들을 AND로 묶은 것
예를 들어 NAND는 이런 형태로 쓴다(슬라이드 규칙 그대로).
왜 XOR / MUX가 SAT에서 골칫덩이냐
XOR는 gate consistency가 clause 수가 늘어나고 구조가 “either-or”라 탐색이 까다롭다.
2-input XOR만 해도 CNF가 4개 clause로 늘어난다.
(MUX도 비슷하게 “선택에 따라 달라지는” 구조라 solver 입장에서 branching을 유도한다)
11) SAT 실전 대표 예시: equivalence checking (miter)
“두 회로가 같은가?”는 SAT의 전형적인 먹이다:
- F와 G를 비교하려면, 새로운 네트워크를 만들어서 SAT를 건다
- SAT면 “다르게 만드는 input pattern”을 준다
- UNSAT면 “동일”
BDD로도 가능(앞에서 말한 F⊕G BDD 후 satisfiable)
실무에선 큰 문제에서 SAT가 더 자주 이긴다.
12) BDD vs SAT: 언제 뭐 쓰냐
BDD
- function ϕ의 full representation을 만든다
- 그 위에서 AND/OR/NOT, 심지어 quantification 같은 다양한 operator를 할 수 있다
- 대신 어떤 문제는 BDD를 만들다가 SPACE(메모리) 가 먼저 끝난다
SAT
- ϕ를 “다 표현”하지 않고, SAT/UNSAT 판정과 하나의 assignment에 집중
- 대신 어떤 문제는 탐색이 길어져서 TIME 이 먼저 끝난다
- 그래서 “just solve it”류 앱에서 SAT가 BDD를 많이 대체했다(스케일).


