Antes, "cuántos nanos de proceso, cuántos núcleos" parecía describir la mayor parte del rendimiento de los semiconductores.
Ahora, palabras como chiplet, 2,5D, 3D IC y UCIe son las primeras que nos vienen a la cabeza.
No es solo porque sean palabras de moda.
Es porque las interconexiones entre la matriz y la matriz son ahora las que determinan el rendimiento, la potencia y el coste de todo el chip, no solo del interior de la matriz.
Una startup ha ganado la partida a Nvidia, pero... Ningún otro semiconductor puede superar el rendimiento + potencia + ubicuidad + producción en masa de Nvidia en el mercado general.
El siguiente gráfico fue compilado por Amir de riselab.
El eje x es el año y el eje y es el rendimiento.
El negro es la pendiente de mejora del rendimiento de los semiconductores de sistema > Semiconductores de memoria > Interconexiones > Pendiente de mejora del rendimiento
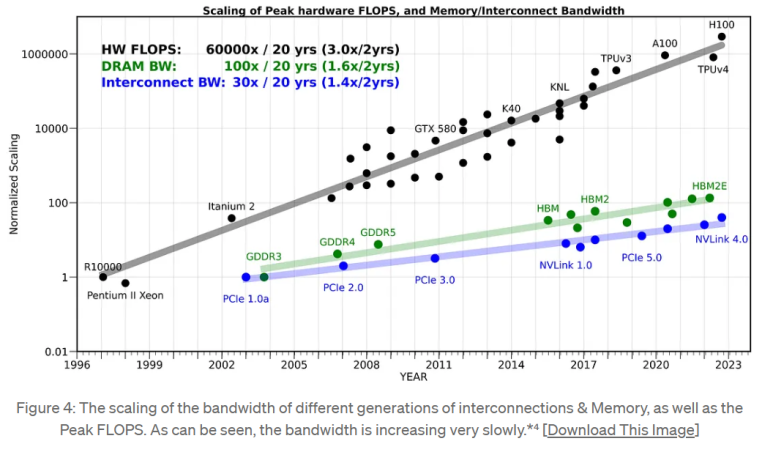
A nivel de placa, acabarás utilizando las tres, pero por muy rápidas que sean las GPU, son el cuello de botella de otros semiconductores debido a su escaso ancho de banda.
Por eso, se ha convertido en un gran reto para las empresas de semiconductores de IA adquirir el mayor número posible de HBM con el mayor ancho de banda en memoria"
Los HBM han hecho subir los precios de las acciones de SK Hynix (la empresa tecnológica más importante del mundo), Samsung Electronics (la empresa de producción más importante del mundo) y Micron (la empresa de memoria más importante de EE.UU.).
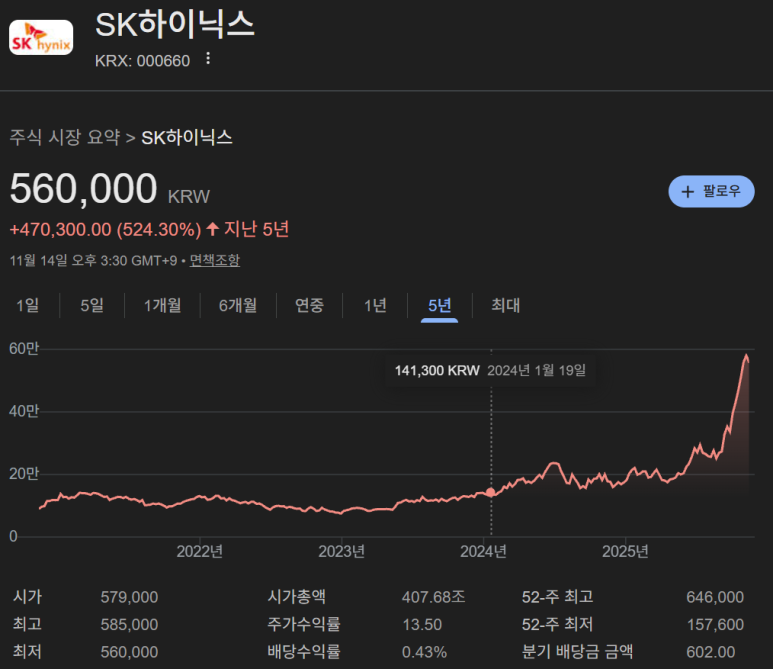
Pero... Más lenta que la memoria es la interconexión.
Antes pensaba que "Chiplet = chip grande partido y pegado", pero cuanto más lo investigo, más creo que la próxima partida de los semiconductores la ganará o la perderá la interconexión.
El proceso es mejor, así que ¿por qué dividir el chip
Para hablar de Chiplet, tenemos que empezar por "¿por qué abandonamos los SoC monolíticos?".
Primero, la limitación del tamaño de la retícula.
Dibujamos una máscara esquemática con una máquina de exposición (ASML), y hay un área máxima que esta máquina puede dibujar un circuito. Si diseñas una CPU de alto rendimiento, una GPU y un acelerador de IA en un troquel gigante, estarás cerca de este límite. Más allá de este punto, el propio diseño se vuelve más complejo y el rendimiento disminuye drásticamente.
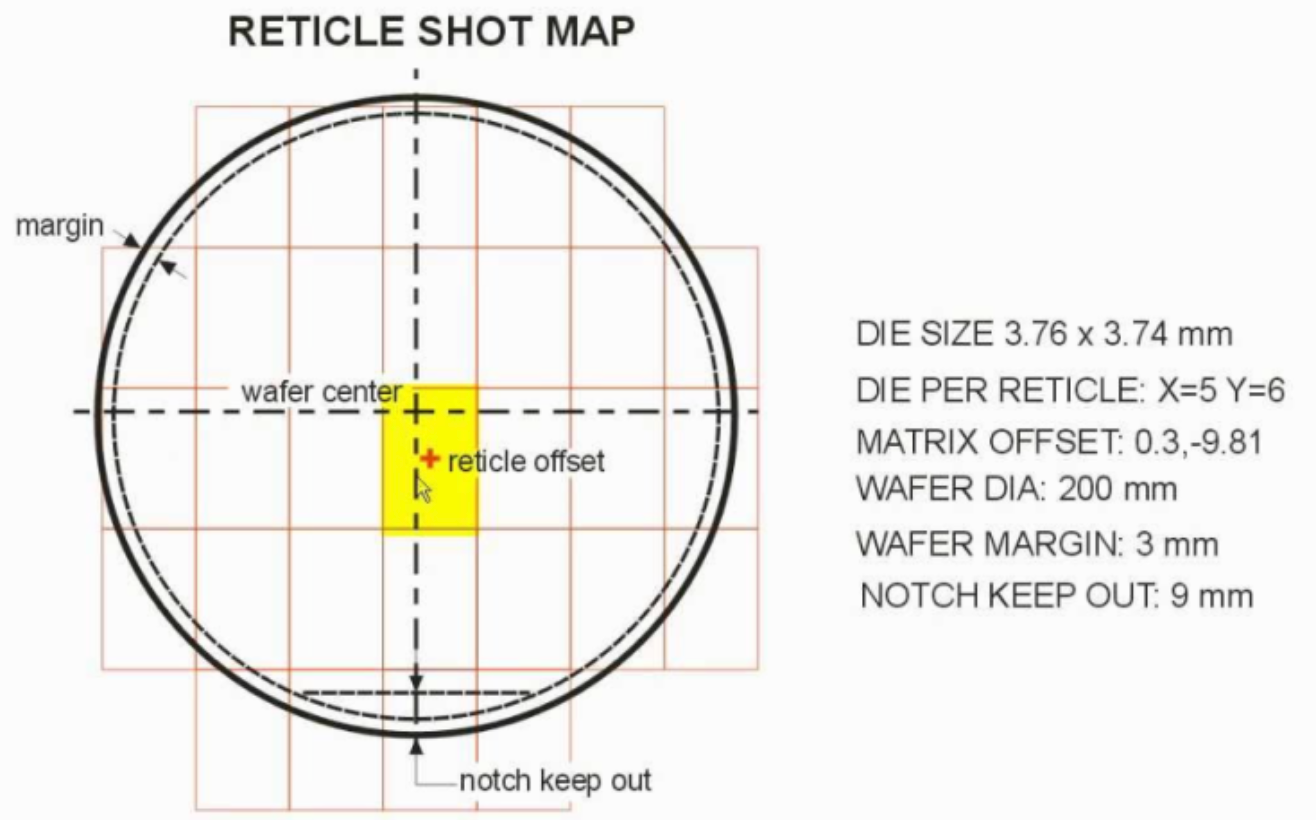
Segundo, rendimiento y estructura de costes. Si tienes un troquel de 800 mm² y se atasca un trozo de polvo, todo el chip es malo y tienes que tirarlo, mientras que si tienes cuatro trozos de 200 mm², si uno es malo, los otros tres se pueden utilizar para otras combinaciones. Estadísticamente, la estructura de las virutas es mucho más favorable. Cuanto más fino es el proceso, mayor es el precio de una matriz, por lo que la diferencia se nota más.
https://semiengineering.com/designs-beyond-the-reticle-limit/
Tercera, integración heterogénea.
Los SoC actuales tienen CPU, NPU, GPU, SerDes de alta velocidad, DDR/LPDDR/PHY, analógicos, RF, gestión de energía y mucho más. No siempre es mejor implementar todos los bloques en el último proceso FinFET/GAA. La lógica digital se beneficia de los procesos punteros, pero la analógica y la E/S son más fiables y baratas en procesos maduros"
El resultado final es "hacer cada bloque en el mejor proceso y luego combinarlos en un paquete". Las palabras clave aquí son 2,5D, circuitos integrados en 3D y chiplets.
En resumen, los chiplets son "una estructura para eludir las limitaciones del proceso, controlar el rendimiento y el coste, y mezclar diferentes procesos en un paquete". El problema es que, una vez desglosado, es mucho más difícil averiguar cómo conectar los puntos.
Pero... Chiplet tiene buena pinta por el rendimiento y la estructura de costes,
pero el proceso de fabricación de CIs 2,5D y CIs 3D es complicado, por lo que el rendimiento puede ser bajo, y hay que gastar mucho dinero para compensarlo, por lo que puedes acabar con más barriga que estómago.
Por eso aún no vemos mucha producción en masa.
Enlace entre cables on-die y entre chips
En un SoC monolítico, la mayoría de los datos fluyen por encima de la capa metálica on-die. Incluso los cables globales siguen siendo cables de silicio, que envían y reciben señales con un retardo de cientos de ps a unos pocos ns y una energía relativamente baja.
A pesar de la importancia del diseño de red en chip (NoC), el enrutamiento físico en sí es más un problema "en el chip".
En cuanto se llega a la estructura de chiplets, hay datos críticos que salen del chip y vuelven a entrar. En otras palabras, la ruta cambia así:
Core → On-Die NoC → Die Edge → Micro Bump → Interposer o RDL → Micro Bump en otro die → On-Die NoC → Core
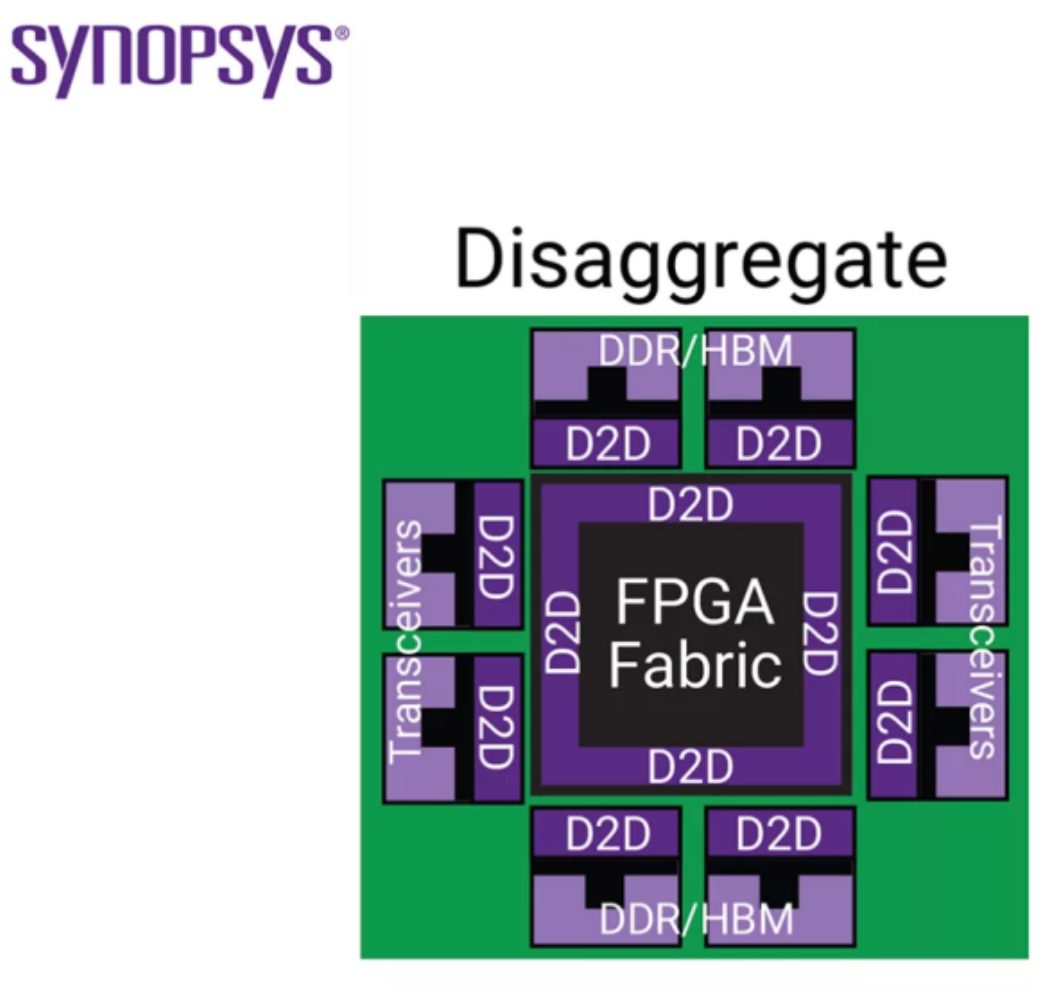
Desde el punto de vista de la física, cambian algunas cosas.
El medio del cableado cambia
Ahora ya no se trata sólo de una capa metálica sobre silicio, sino que atravesamos diversos medios, como microbaches, TSV, intercaladores de silicio, RDL en abanico y sustratos orgánicos.
La longitud y el entorno cambian
Es mucho más largo que el cable en el chip y la impedancia es más compleja. Los problemas de integridad de la señal entran en juego. El "muro" entre los SerDes de paquete tradicional y el cable en la matriz se rompe, y entran en juego problemas de diseño de SerDes muy avanzados.
El precio de la energía y el área cambia
El coste de añadir un cable en la matriz más no es el mismo que el de añadir un enlace matriz a matriz más. La longitud del borde de la matriz es limitada y el paso de la protuberancia es limitado. A medida que aumenta el número de enlaces, el área del perímetro de la matriz, el área de la célula PHY, el enrutamiento y la potencia se ven afectados.
Enrutamiento y potencia
Lo que solía ser un diseño de "podemos utilizar un poco más de cable" es ahora un diseño de "¿merece realmente la pena este enlace por el ancho de banda?".
A partir de este punto, la interconexión ya no es sólo cableado físico, sino un recurso clave que determina la arquitectura de todo el Sistema Chiplet.
La Interconexión Chiplet desde una perspectiva PPA
Al final del día, cada diseño se reduce a PPA (Potencia, Rendimiento, Área) y Coste. Chiplet Interconnect está profundamente involucrado en los cuatro pilares.
Rendimiento: ancho de banda y latencia
Hay una enorme cantidad de datos que fluyen entre aceleradores de IA, GPU, CPU de alto rendimiento y memorias de gran ancho de banda como las HBM. Cuando estos datos fluyen a través de un enlace de chip a chip, en lugar de dentro del chip, la densidad del ancho de banda y la latencia de ida y vuelta del enlace determinan el límite superior del rendimiento del sistema.
Si no hay suficiente ancho de banda, no importa cuántos núcleos añadas, te encontrarás con un "muro de memoria". Y si la latencia es demasiado alta, la colaboración de grano fino se hace difícil y la arquitectura debe diseñarse con grano grueso. Por ejemplo, si la caché L3 se separa en chiplets y la latencia es demasiado grande, se convierte casi en una memoria fuera del chip.
Potencia: lucha por pJ/bit
El cableado en el chip puede reducir la potencia a decenas de fJ/bit, pero los SerDes basados en paquetes suelen costar varios pJ/bit. Las PHY de corto alcance y muy bajo consumo para chiplets también aspiran a conseguir menos de pJ/bit, pero siguen siendo más caras que las on-die."
Al final del día, como arquitecto de sistemas, tienes que preguntarte: "¿Realmente quiero enviar estos datos a través de la matriz, o quiero computarlos una vez más en la matriz y comprimirlos?"
Y la etiqueta de precio energético de la interconexión no es la misma. A medida que cambia el precio de la potencia de la interconexión, también cambia el equilibrio entre computación y comunicación.
Área: Borde de la matriz y área PHY
La interconexión de chips está "centrada en el borde". El bump y la PHY se colocan a lo largo del perímetro de la matriz. Aumentar el tamaño de la matriz no solo aumenta el área del núcleo, sino también la longitud del borde, pero la eficiencia con la que se asigna el borde a la interconexión afecta directamente al PPA.
Particularmente cuando se utiliza una interfaz estandarizada de matriz a matriz como UCIe, no se puede ignorar el área ocupada por el PHY, el controlador y la pila de protocolos. Reducir el área y la potencia requeridas aquí es la ventaja competitiva del diseño de chiplets.
Cost: Mezcla de procesos y complejidad del encapsulado
Con una estructura de chiplet, se puede reducir el coste unitario de la matriz dividiendo la lógica en procesos punteros y las E/S en procesos maduros. El problema es el coste del encapsulado. Los intercaladores de silicio, los RDL de alta densidad y los bumps de paso fino son muy caros. Los excesivos requisitos de interconexión complican la estructura del encapsulado y elevan el coste total"
Así pues, la interconexión se convierte en el barómetro que determina "¿tiene sentido económico esta arquitectura de chiplet?".
UCIe y la estandarización de las interfaces de chip a chip
Una de las palabras clave de las que más se habla estos días es UCIe (Universal Chiplet Interconnect Express). Aunque el nombre tiene un aire a PCIe, en realidad su objetivo es proporcionar compatibilidad con protocolos existentes como PCIe/CXL, así como PHYs especializados para entornos die-to-die.
La razón de ser de UCIe es clara. Los chiplets de diferentes empresas pueden combinarse
El ecosistema de chiplets nunca crecería si cada empresa se atuviera a su propia interfaz propietaria de chip a chip. Sólo cuando exista una "interfaz estándar que cualquiera pueda combinar" se podrán tener realmente diseños "prefabricados" a nivel de SoC.
Las ventajas de la estandarización son obvias: por ejemplo, una empresa puede fabricar un chip para CPU, otra un chip para NPU, otra un chip para SerDes/IO, y una empresa de sistemas puede combinarlos en un paquete. En realidad, por supuesto, no es tan sencillo por cuestiones de propiedad intelectual, validación y responsabilidad. Pero el hecho de que sea un "escenario posible" es un gran cambio.
EDA y Design Flow se limpian
En lugar de tener que modelar nuevos PHY y protocolos propietarios cada vez, los modelos de canal y enlace basados en UCIe pueden utilizarse como base común. Existe un denominador común para STA, SI, PD y el flujo de codiseño de paquetes.
Por otro lado, tener un estándar también significa que "la interconexión en sí se convierte en un punto de competencia". La empresa con la IP PHY, la estructura de paquete y la tecnología de cooptimización que pueda ofrecer mejor potencia/ancho de banda/latencia/área ganará el mercado.
La difuminación del diseño de paquetes y chips
Otro motivo por el que la interconexión de chiplets es tan importante es que rompe las "fronteras del diseño".
En el pasado, la división era más o menos la siguiente:
En el chip: diseño lógico, diseño físico, STA, SI en el chip
Paquete: diseñado por el equipo de PCB/paquete por separado y a velocidades mucho más bajas
En una estructura de chiplet, los dos son completamente indivisibles. Los canales del enlace troquel a troquel examinan simultáneamente las estructuras de los bordes del paquete y del troquel. La colocación de la matriz, el mapeado de bump, el enrutamiento del intercalador, el apilamiento del encapsulado y la colocación del PHY dentro de la matriz deben abordarse todos a la vez."
Al final del día, estas cuestiones se resuelven en equipo.
A qué distancia deben colocarse los chiplets A y B
Cuánta longitud de canal puede permitirse en el intercalador
En qué orden deben colocarse las protuberancias en el borde de la matriz
Dónde debe delimitarse el enlace NoC en la matriz y de matriz a matriz
Aquí es donde el ingeniero de paquetes, el ingeniero de PD, el ingeniero de SI, el arquitecto de sistemas y el proveedor de herramientas EDA se sientan a la misma mesa.
A medida que se generalicen los chiplets, cambiarán las perspectivas que se exigen a los diseñadores:
No sólo "comprender unos pocos nanos del proceso"
La capacidad de comprender las capas físicas, lógicas y de protocolo de la interconexión juntas
La visión a nivel de sistema de la NoC on-die y el tejido off-die como un todo integrado
La capacidad de analizar las compensaciones de extremo a extremo, incluyendo potencia/área/coste
Estas tres cosas serán cada vez más importantes.
Puede que piense: "Todavía queda mucho por hacer con los transistores, la lógica, las PD y las STA, y luego están la interconexión y el encapsulado". Pero es mejor entrar en el diseño sabiendo al menos "dónde están los verdaderos cuellos de botella que determinan el rendimiento y el coste del chip". Desde mi punto de vista, la interconexión en la era de los chips no es un tema que deba evitarse, sino una gran oportunidad para ampliar la carrera profesional. En cuanto entiendes la interconexión entre chips y paquetes, te conviertes en un experto en "chips completos", en lugar de fijarte sólo en la temporización y la IS en el chip. El alcance de lo que puedes hacer es mucho más amplio"