以前は、"プロセスが何ナノか、コアが何個か"が半導体の性能の大部分を説明するように感じられました。
最近では、Chiplet、2.5D、3D IC、UCIeなどの単語が最初に目に飛び込んできます。
これは単なる流行語だからではありません。
今はダイの内部ではなく、ダイとダイの間をつなぐインターコネクトがチップ全体の性能と電力、コストを左右するレベルまで上がったからです。
あるスタートアップがNvidiaに勝ったらしいですが...NVIDIAのチップの性能+電力+汎用性+量産歩留まりなど、広い部分で市場性を勝る半導体はない。
下の資料はriselabのAmirがまとめたグラフである。
X軸は年、Y軸は性能と見ればよい。
黒色はシステム半導体の性能改善勾配>メモリ半導体の性能改善勾配>インターコネクトの性能改善勾配
figure class="kg-card kg-image-card kg-card-hascaption">
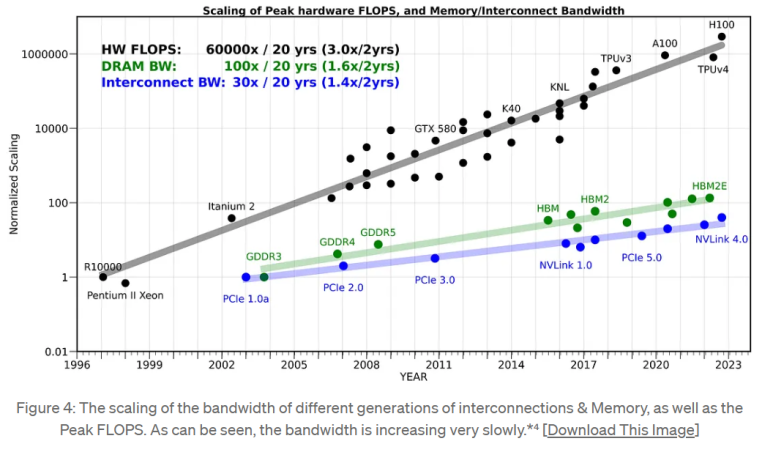
https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
ボードレベルでは、最終的にこの3つすべてを使用することになりますが、
GPUの性能がいくら速くても、他の半導体の帯域幅が小さいため、他の半導体でボトルネックが発生します。
そのため、企業は現在、メモリで最も大きな帯域幅を持つHBMをできるだけ多く持って行くことが人工知能半導体会社の大きな宿題となり、
HBMのおかげでSKハイニックス(世界最高技術力)、サムスン電子(世界最高生産力)、ミクロン(米国最高メモリ会社)の株価が最近、ものすごく上がっている。
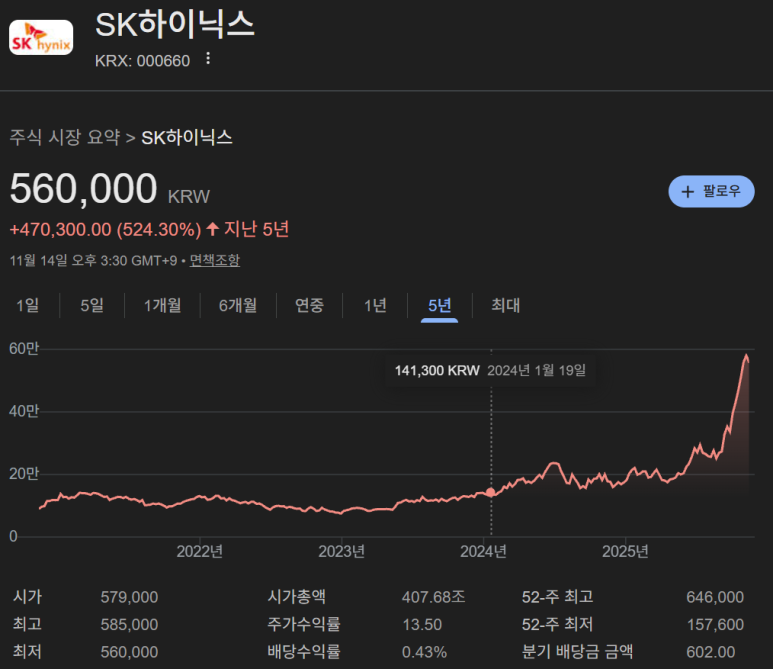
ところで...メモリより遅いのはインターコネクトである.
私も以前は「Chiplet = 大きなチップを分割して貼り付けるんだろう」程度にしか考えていなかったが、見れば見るほど、次の半導体ゲームの勝敗を分けるのはインターコネクトだと思う。
プロセスはより良くなったのに、なぜあえてチップを分割するのか
Chipletの話をするためには、まず「なぜモノリシックSoCを放棄したのか」から指摘しなければなりません。
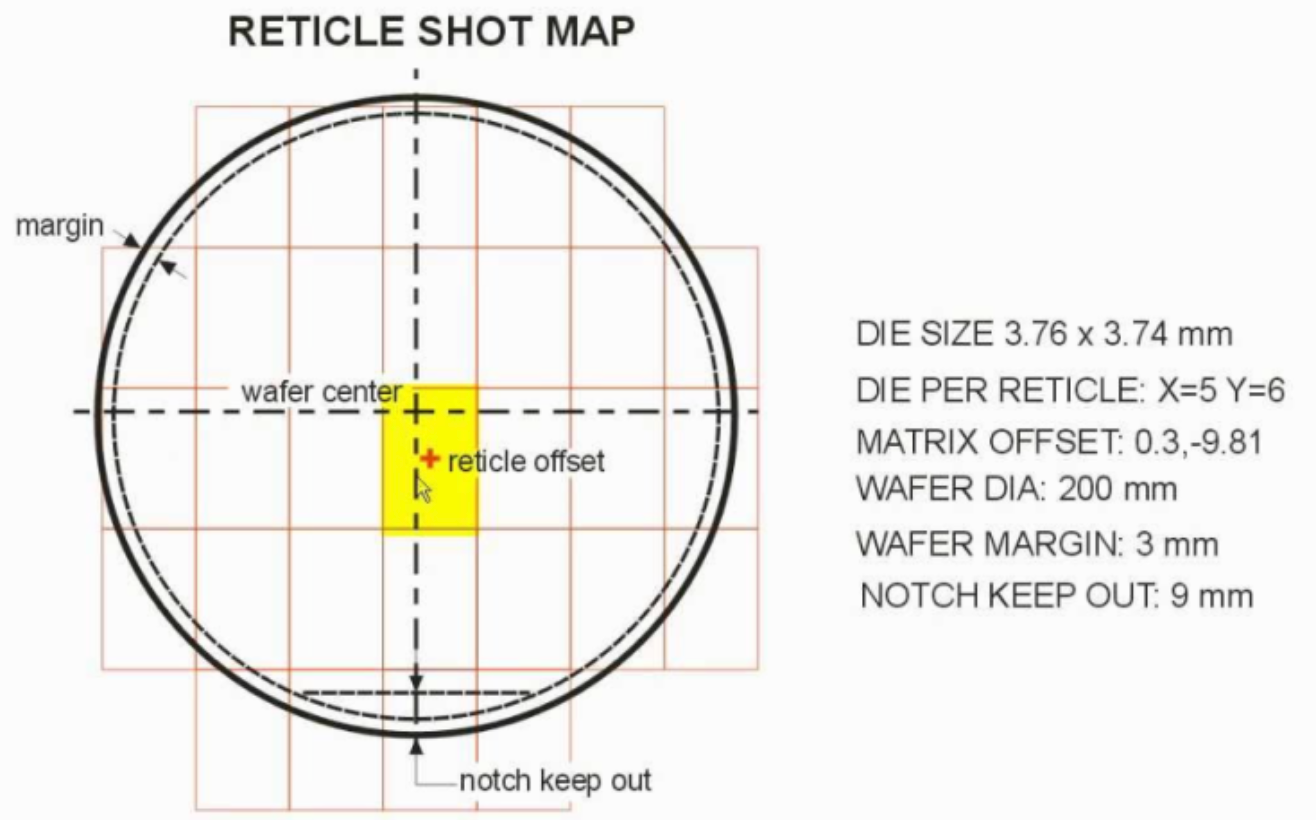
まず、Reticle Sizeの限界.
露光装置(ASML)で回路図マスクを描くが、
この装置が回路を描くことができる最大面積がある。高性能CPU、GPU、AI Acceleratorを一つの巨大なダイで設計すると、この限界近くまで行くことになります。この点を超えると、設計自体が複雑になり、収率も急激に低下します。
figure class="kg-card kg-image-card">
第二に、歩留まりとコスト構造.
面積が大きくなればなるほど、「1つの不良」がもたらす損失は大きくなります。800 mm²のダイに1つのダストが詰まった場合、結局、このチップ全体が不良であり、そのまま廃棄しなければなりませんが、200 mm²の4つに分割された場合、1つが不良であっても、残りの3つは他の組み合わせに使用することができます。統計的に見れば、チップレット構造の方がはるかに有利になる。プロセスが微細化すればするほど、1つのダイの価格が上昇するため、この差はより大きく感じられます。
https://semiengineering.com/designs-beyond-the-reticle-limit/
Third, Heterogeneous Integration.
最近のSoCには、CPU、NPU、GPU、High-Speed SerDes、DDR/LPDDR/PHY、アナログ、RF、電源管理などのものがすべて入っています。すべてのブロックを最新のFinFET/GAAプロセスで実装することが常にベストとは限りません。デジタルロジックは先端プロセスが有利ですが、アナログやI/Oはむしろ成熟したプロセスの方が安定的で安価です。
結局、「各ブロックを最適なプロセスで作り、パッケージで組み合わせよう」という方向に進むしかありません。このときのキーワードが2.5D、3D IC、そしてChipletである。
要約すると、Chipletは「プロセスの限界を迂回し、歩留まりとコストを抑え、異なるプロセスを一つのパッケージで混ぜるための構造」である。問題は、このように分割してしまうと、その間をどのようにつなげるかがさらに難しくなることです。
しかし...
。歩留まりとコスト構造のためにChipletが無条件に良く見えることもありますが、
2.5D IC、3D ICの製造工程自体が複雑なので、この過程で歩留まりが落ちることもあり、これを補うためにかなり多くのお金がかかるので、腹より腹が大きくなる状況が来るかもしれません。
On-Die WireからDie-to-Die Linkへ
モノリシックSoCでは、ほとんどのデータがOn-Die Metal Layerの上で流れます。Global Wireと言っても、結局はシリコン上の配線であり、数百ps~数nsレベルの遅延、比較的低いエネルギーで信号を送受信します。
NoC(Network-on-Chip)設計は重要ですが、Physical Routing自体は"チップ内で何とか解決できる"問題に近いものでした。
Chiplet構造に移行した瞬間、重要なデータはDieの外に出て、Dieに戻ってくる構造になります。つまり、経路が次のように変わります。
Core → On-Die NoC → Die Edge → Micro Bump → InterposerまたはRDL → 他のDieのMicro Bump → On-Die NoC → Core
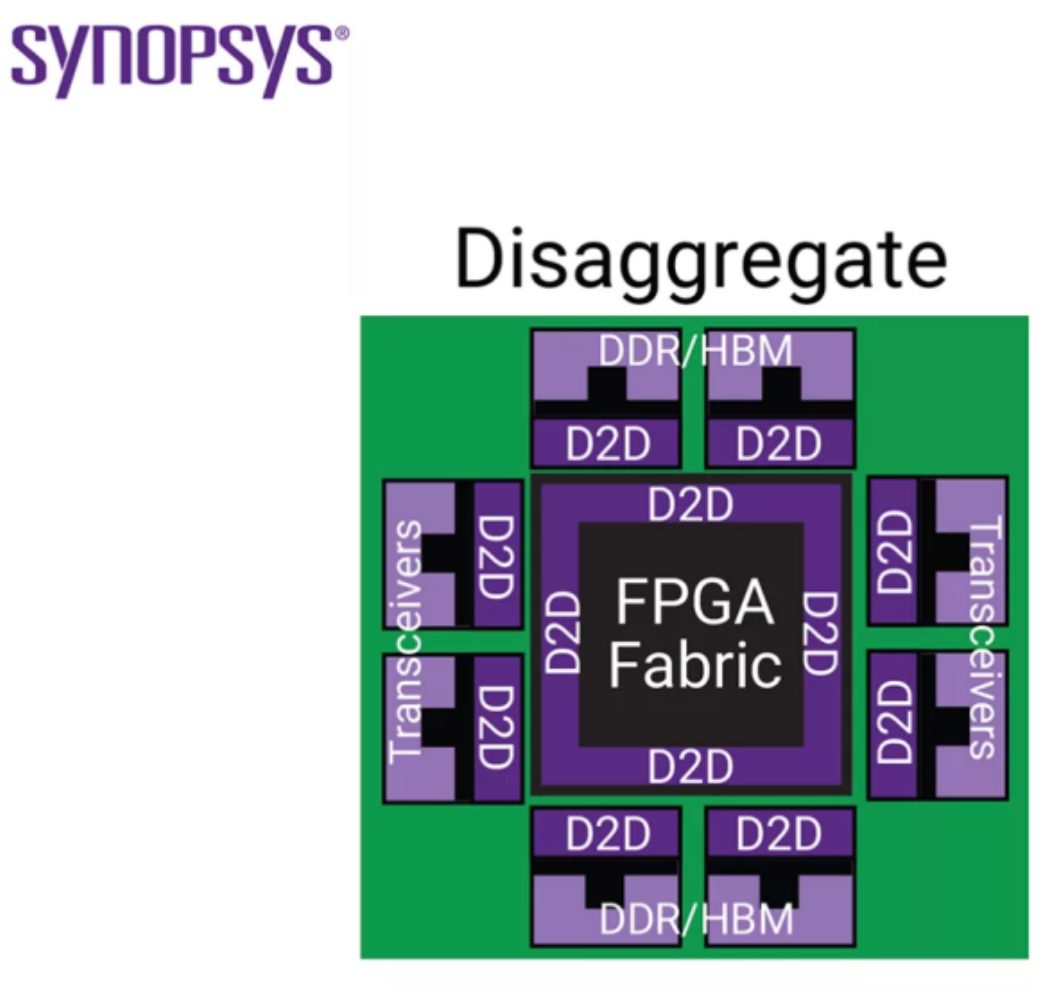
물리적인 관점에서 보면 몇 가지 변화가 생긴다.
配線の媒体が変わる
今はシリコン上のMetal Layerだけでなく、Micro Bump、TSV、Silicon Interposer、Fan-Out RDL、有機基板など様々な媒体を通過します。
各区間ごとに抵抗、寄生、損失、反射特性が異なり、チャネル全体を一つのシステムとしてモデル化しなければなりません。
blockquote>長さと環境が変わる
On-Die Wireよりはるかに長く、インピーダンスも複雑になります。Signal Integrityの問題が本格的に登場する。従来のPackage SerDesとOn-Die Wireの間にあった"壁"が崩れ、かなり高度なSerDes設計レベルの悩みがパッケージの中に入ってくる
blockquote>
On-Die Wireを一つ多く敷設するときのコストと、Die-to-Die Linkを一つ多くするときのコストは次元が違います。Die Edgeの長さは限られており、Bump Pitchも限られています。リンク数を増やすと、Die周辺部Area, PHY Cell Area,
Routing,Routing,
以前は"Wireをもう少し使えばいい"で終わっていた設計が、今は"このリンクが本当にその帯域幅を受ける価値があるか"という質問に変わります。
この瞬間から、Interconnectは単純な物理配線ではなく、Chiplet System全体のアーキテクチャを決定する重要なリソースになります。
PPAの観点から見たChiplet Interconnect
結局、すべての設計はPPA(Power, Performance, Area)とCostに帰着します。Chiplet Interconnectはこの4つの軸すべてに深く関わっています。
Performance: 帯域幅と遅延
AI Accelerator、GPU、High-Performance CPU、そしてHBMのような高帯域幅メモリ間では、膨大な量のデータがやり取りされます。このデータがOn-Dieではなく、Die-to-Die Linkを介して流れるようになったため、リンクの帯域幅密度と往復遅延がシステムパフォーマンスの上限を決定します。
帯域幅が不足していると、コアをいくら増やしても「メモリーウォール」で詰まってしまいます。そして、遅延が大きすぎると、Fine-Grainなコラボレーションが難しくなり、アーキテクチャ自体をCoarse-Grainに設計する必要があります。例えば、L3 CacheをChipletで分離した場合、Latencyが大きすぎると、事実上Off-Chip Memoryに近い存在になってしまいます。
Power: pJ/bitの戦い
On-Die Wireは数十 fJ/bitレベルまで電力を圧縮することができますが、Package-Based SerDesは数pJ/bitの場合が多いです。Chiplet用Short-Reach, Ultra-Low-Power PHYも目標はpJ/bit以下ですが、それでもOn-Dieに比べると高価です。
結局、System Architectの立場では
"このデータを本当にDieを越えて送るべきか、それともこのDieの中でもう一度計算して圧縮して送るべきか?"
と悩むことになります。インターコネクトの電力価格表が変われば、Compute vs Communication Trade-Offも変わります。
h2 id="area-die-edge%EC%99%80-phy-area">Area: Die Edge and PHY Area
Chiplet Interconnectは「Edge-Centric」です。Die Perimeterに沿ってBumpとPHYが配置されます。Dieサイズを大きくするとCore Areaだけでなく、Edgeの長さも長くなりますが、Edgeをどれだけ効率的にInterconnectに割り当てるかがPPAに直接影響します。
特に、UCIeのようにStandardized Die-to-Die Interfaceを使う場合、PHY、Controller、Protocol Stackが占めるAreaも無視できません。ここに入る面積と電力を減らすことがChiplet Designの競争力になります。
Cost:プロセスの組み合わせとパッケージの複雑度
Chiplet構造を使えば、Logicは先端工程、I/Oは成熟工程に分けることで、Die単位コストを減らすことができます。問題はパッケージコストである。Silicon Interposer、高密度RDL、Fine-Pitch Bumpは非常に高価です。
インターコネクトの要件が過剰になると、パッケージ構造が複雑になり、最終的に全体のコストが上がります。
したがって、インターコネクトは「このチップレットアーキテクチャが経済的に意味のあるものかどうか」を決定するバロメーターとなります。
UCIe, そして Die-to-Die Interfaceの標準化
最近最も多く言及されるキーワードの一つがUCIe(Universal Chiplet Interconnect Express)です。名前だけ見るとPCIeの感じがしますが、実際にはPCIe/CXLのような既存のプロトコルとの互換性、そしてDie-to-Die環境に特化したPHYを提供することを目指しています。
figure class="kg-card kg-image-card">
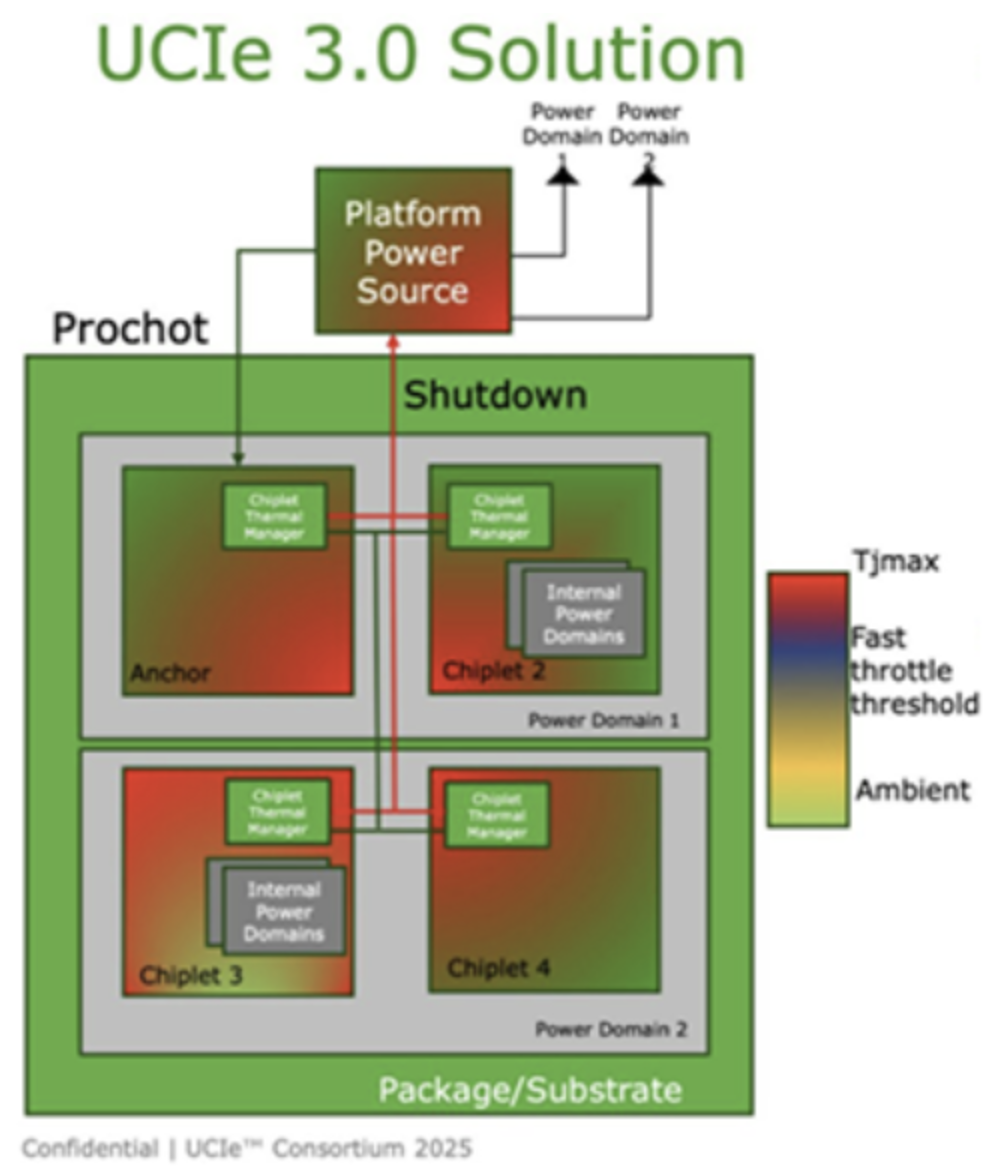
UCIe が登場した理由は明らかです。異なる会社のChipletを組み合わせることができる
各企業が自分たちだけが使うProprietary Die-to-Die Interfaceだけを主張すれば、Chiplet Ecosystemは決して大きくなることはできません。"誰でも組み合わせて使える標準インターフェース"があることで、SoCレベルでの"アセンブル"設計が可能になります
例えば、ある会社はCPUチップレット、別の会社はNPUチップレット、別の会社はSerDes/IOチップレットを作り、System Companyがそれらを組み合わせて一つのパッケージにすることができます。もちろん、現実的には、IP、検証、責任所在の問題があり、そう簡単ではない。
EDAとデザインフローが整理される
毎回新しいProprietary PHY、Protocolをモデル化する必要がなく、UCIeベースのチャネルとリンクモデルを共通ベースにすることができます。STA、SI、PD、Package Co-Design Flowに共通分母が生まれます。
逆に、標準が生まれるということは、「インターコネクト自体が一つの競争ポイントになる」ということでもあります。電力/帯域幅/遅延/面積をより良くすることができるPHY IP、Package構造、Co-Optimization技術を持つ会社が市場で優位になります。
パッケージとチップ設計の境界が曖昧になる時代
Chiplet Interconnect が重要なもう一つの理由は、"設計境界"を破壊することです。
以前は、大まかに次のように分けることができました。
Die内部:Logic Design、Physical Design、STA、On-Die SI
パッケージ:PCB/Package Teamが別々に、はるかに低い速度基準で設計
Chiplet構造では、この2つを完全に分けることはできません。Die-to-Die Linkのチャンネルは、パッケージとDie Edge構造を同時に見ます。Die配置、Bump Mapping、Interposer Routing、Package Stack-Up、そしてDie内部PHY Placementを一度に考えなければなりません。
結局、このような質問を一つのチームが一緒に扱うことになります。
A ChipletとB Chipletをどれくらい離して置くか
Interposer上のチャンネル長はどれくらい許容できるのか
Die Edgeにどのような順番でBumpを配置するか
On-Die NoCとDie-to-Die LinkのBoundaryをどこにするか
この過程でPackage Engineer, PD Engineer, SI Engineer, System Architect, EDA Tool Vendorが一つのテーブルに座ることになります。
Chipletが本格的に普及すると、設計者に要求される視点も変わるに違いありません。
単に「プロセス数ナノの理解」で終わるのではなく、
Interconnectの物理、論理、プロトコル層を一緒に理解する能力
On-Die NoCとOff-Die Fabricを統合して見るSystem-Levelの視点
Power/Area/Costまで含めたEnd-to-End Trade-Off分析能力
この3つがますます重要になるでしょう。
"まだTransistor、Logic、PD、STAだけでもやることが多いのに、そこにInterconnect、Packageまで付くのか"と思うかもしれません。それでも、少なくとも「チップの性能とコストを決定する本当のボトルネックがどこにあるのか」くらいは知って設計に入る方が良いです。最近では、そのボトルネックは非常に頻繁にInterconnectに押し寄せます。
私自身、チップレット時代のInterconnectは避けて通れないテーマではなく、キャリアの幅を広げる絶好のチャンスに近いです。Dieの中のTiming、SIだけを見ていた人がDie-to-Die、Packageまで理解した瞬間に「チップ全体を見る人」になる。仕事の幅もぐっと広がります。