現代の半導体産業は、ムーアの法則が予測したトランジスタ集積度の限界を絶えず突破しながら進んでいます。 数十億個のトランジスタが爪ほどの大きさのシリコンダイ上に集積されるVLSI時代です。
RTLコードを実際に製造可能な物理レイアウトであるGDSファイルに変換するPhysical Design、通称P&R(Place and Route) プロセスは、単純な RTL コードを入力して GDS コードを受け取る Code2Code 自動化を超えた、極限の多変数最適化問題へと進化しました。
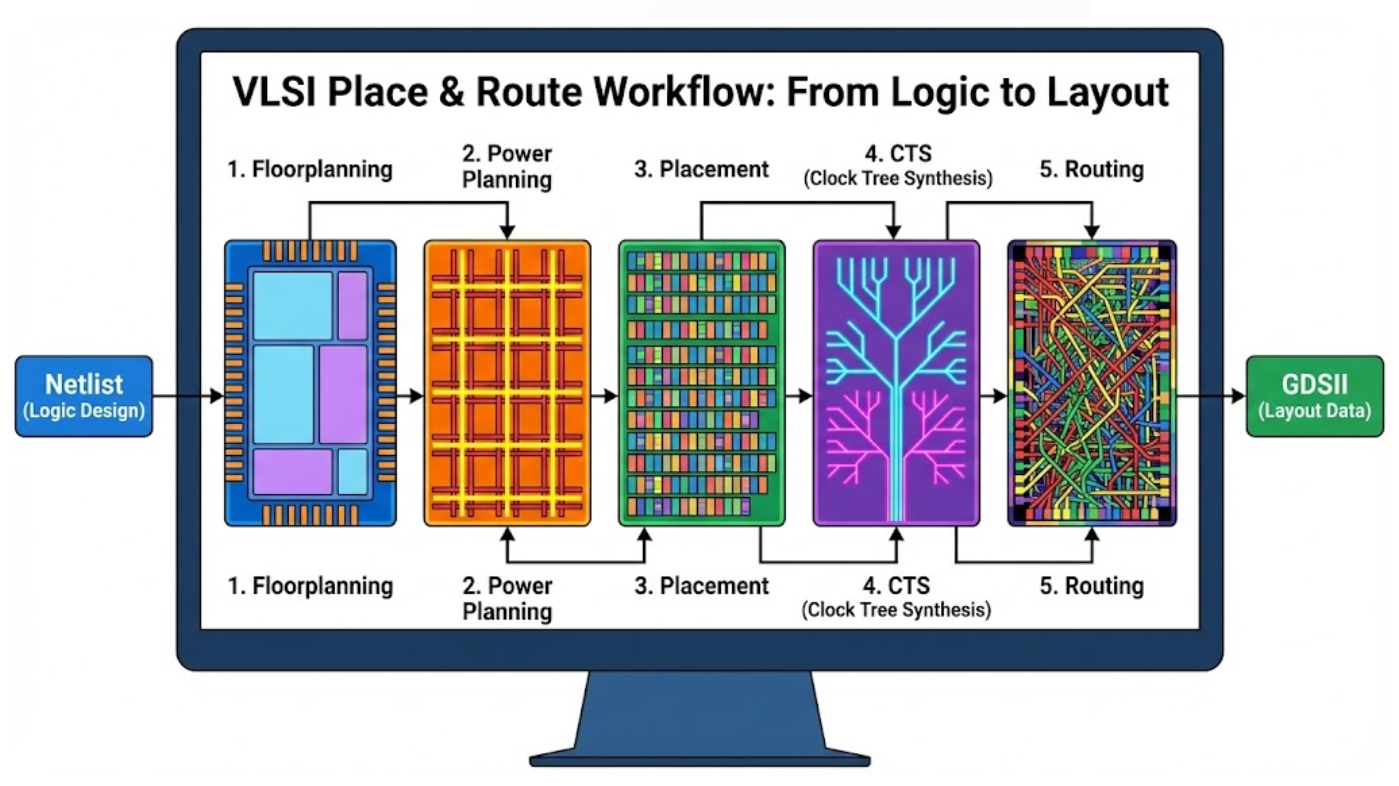
過去、µm単位のプロセスでは、P&Rは単に素子を配置し、線を接続する幾何学的パズルであったが、7nm、 5nm、そして3nm以下のFinFETおよびGate-All-AroundプロセスにおけるP&Rは、量子力学的効果、電磁的相互作用、そして製造プロセスの物理的限界まで考慮しなければならない複合物理学的エンジニアリングの頂点と言えるでしょう。
P&Rは、ケースの数があまりにも多いNP問題です。
1. 設計分割(Design Partitioning)
現代のSoC設計は、単一のエンジニアや単一のCADツールセッションが処理できる範囲を超えています。フラット設計で処理しようとすると、メモリ不足現象や数週間に及ぶランタイム、そして収束不可能なタイミング問題に直面することになります。
したがって、パーティショニングは物理設計の第一歩であり、プロジェクト全体の成否を左右する戦略的アーキテクチャリング段階です。
パーティショニングの単位は、ほとんどの場合ランタイムを基準に設定します。例えば、「タイミングECOを1日1回は実行できるランタイムを確保しよう」といった基準です。
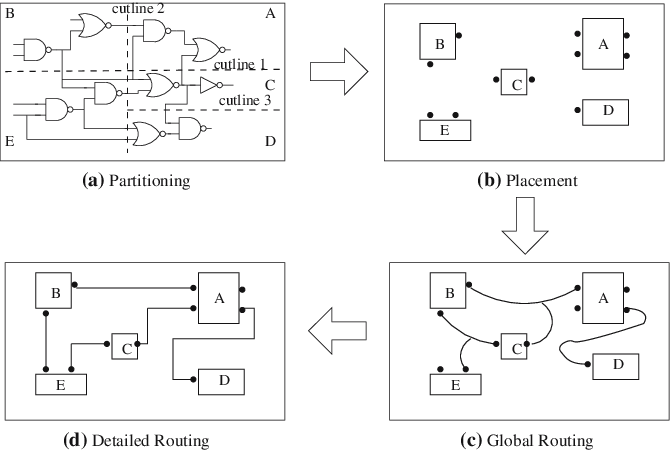
1.1 階層的設計
パーティショニングは「分割統治」の原則をシステム設計に適用したものです。設計方法論は大きくトップダウン方式とボトムアップ方式に区別されます。
- トップダウン分割
- トップダウン方式は、チップ全体をシステムレベルで大きな機能ブロックに分割し、これを繰り返しより小さなモジュールに細分化しながら、 チップトップで各サブシステムを分割し、各サブシステムが使用するPPSAを割り当てます。
- System on Chipレベルで多く使用されます。
- Bottom-Up Partitioning
- Bottom-up方式は、小さなリーフセルやモジュールから始め、これをサブシステムとして構築し、最後にトップレベルへ組み立てます。
- 再利用可能なIP設計で多く使用されます。
2. 高度なパーティショニング手法
最近では、階層的方式とフラット方式の長所を組み合わせた'疑似フラット'または'仮想フラット'方式が注目されています。
物理的にはパーティショニングを通じて階層構造を維持しつつ、タイミング解析やCTS段階ではツールが全体設計をフラットに認識させることで、ブロック境界における非効率性を除去する手法です。
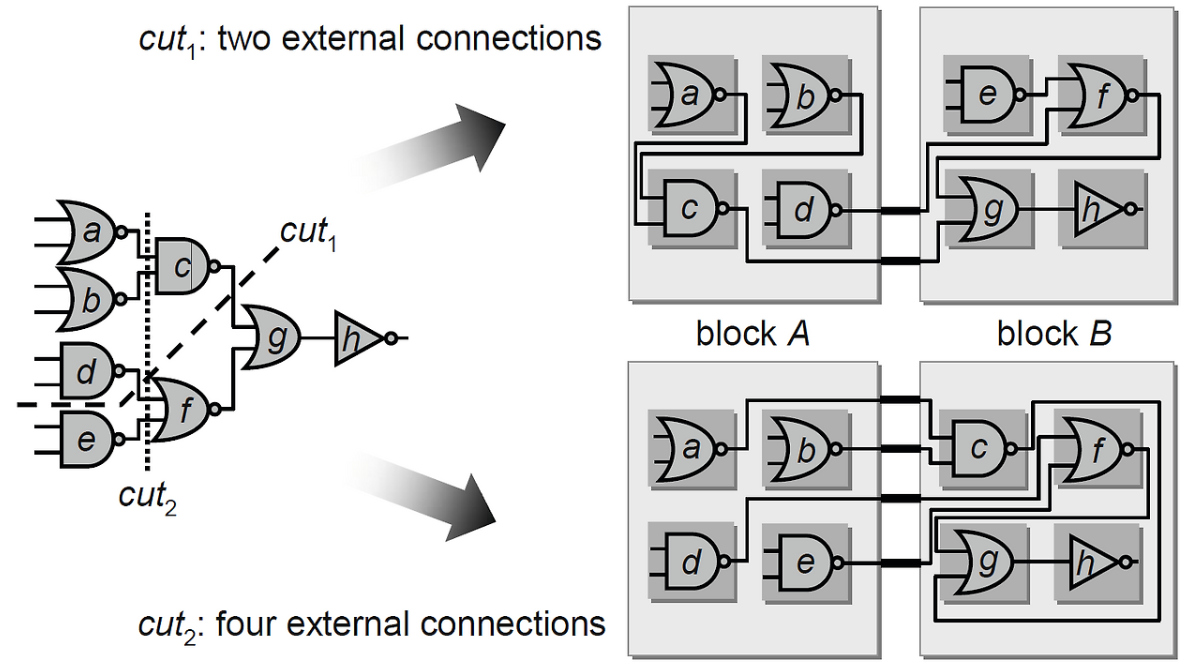
2.2 パーティショニングアルゴリズムと最適化指標
パーティショニングを実行する際には、技術的制約と最適化目標を同時に考慮する必要があります。最も代表的なアルゴリズムはKernighan-Linアルゴリズムです。擬似コードをお見せします。

- 最小カットの原則: 相互接続の数を最小化する必要があります。ブロック間の信号はトップレベルの配線リソースを消費し、 長い配線長によりレイテンシおよび信号の完全性の問題を引き起こします。カーニハン・リンなどのグラフ分割アルゴリズムがカットサイズの最小化に使用されます。
- エリアバランスとアスペクト比: 各パーティションは、物理的に実装可能な形状とサイズを持つ必要があります。高いアスペクト比や直線状の形状は、内部の配置と配線の効率を低下させます。通常、100万~300万インスタンス程度が1つのブロックとして処理するのに適切なサイズです。
- タイミングバジェット: 各パーティションは、物理的な実装が可能な形状とサイズを持つ必要があります。高いアスペクト比や直線状の形状は、内部の配置と配線の効率を低下させます。通常、100万~300万インスタンス程度が1つのブロックとして処理するのに適切なサイズです。
- タイミングバジェット: ルーティングの効率を低下させます。通常、1M~3Mインスタンス程度が1つのブロックとして処理するのに適切なサイズです。
- タイミング予算配分: 分割ブロックは独立したSDCを持つ必要があります。 トップレベルパス遅延のうち、内部ロジックに割り当てる量を決定する予算配分プロセスは、非常に精巧でなければなりません。過度な制約はエリア/電力オーバーヘッドを、緩い制約はトップレベル統合時のタイミング違反を引き起こします。
3. フロアプランニング:構造的基盤
フロアプランニングはチップの物理的骨格を構築するプロセスです。この段階の決定は後続工程であるPlacementとRoutingに絶対的な影響を与え、誤ったFloorplanは回復不可能なPPA LossやRouting Congestionを引き起こします。
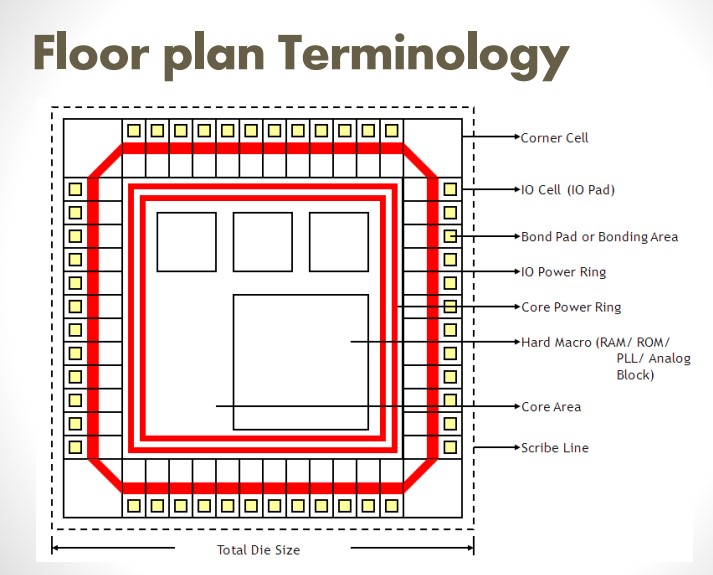
3.1 コアエリア定義と幾何学
- アスペクト比: 幅対高さの比率です。通常、1.0(正方形)に近いほど、水平/垂直配線リソースのバランスが良く効率的です。
- しかし、パッケージング、 PCBフットプリント、ダイソーイングの効率上、長方形が強制される場合もあり、これは特定方向の混雑を引き起こす可能性があります。 CPU、GPU、NPUなどの高周波ブロックを優先的に1.0比率に合わせ、インターフェースブロックを次に合わせる方式が好まれます。
- Utilization: Core Area内でStandard CellとMacroが占める割合です。
- 初期設計時には 60~70% レベルに設定し、バッファ挿入、サイジング、配線マージン を確保します。 80% 以上の高密度は、配線輻輳 の急増により、タイミング ECO が非常に困難になります。また、DFM 歩留まり の低下の原因となります。
3.2 マクロ配置:データフローの視覚化
ハードマクロ(SRAM、PLL、ADC/DAC) の配置は、最も高い熟練度を必要とします。 マクロは巨大であり、特定のメタル層を占有するため、事実上配線障害の役割を果たします。
実際にASIC設計エンジニアが言う、プロジェクトで最も重要な3つの要素は以下の通りです。
- RTL Freeze (RTL を早期に完成させ、テープアウトのスケジュールに間に合わせる)
- SDC Clean (誤ったパス、MCP など不要なパスを適切に整理し、各 EDA フローに適した制約を適切に設定することで、サインオフを安定させる。)
- Golden Floor Planning(これをどう行うかによって、チップのUtilizationとHold time、SI、DRC問題の難易度が決定されます。)
[マクロ配置戦略とガイドライン]
- フライライン分析: マクロ間、マクロと標準セル間の仮想接続線を分析し、データフローを最適化する必要があります。入力から出力方向へデータが直進性を保つように配置することが理想的です。
- 周辺機器配置: マクロをコア境界やブロック外周に配置し、中心領域をスタンダードセルおよび複雑な信号配線のために確保するのが基本です。 中央に配置されたマクロは迂回を引き起こし、深刻なタイミング遅延を招きます。
- マクロチャネル& Halo: マクロ間には、Power StrapやClock Tree Bufferが挿入されるChannelスペースが必要です。また、Keepout Margin(Halo)を設定してPin Accessibilityを確保し、局所的なCongestionを防止しなければなりません。
最近ではAIを利用したフロアプランニング手法も数多く研究されています。
2.3 I/O Planning および Pin Placement
外部世界とチップを接続するI/O Padまたはピンの位置選定も重要です。Wire-bondingパッケージを使用する場合、チップ外周にI/Oリングを構成し、 フリップチップパッケージを使用する場合はチップ前面にバンプを配置します。I/Oピンの位置は内部ロジックのデータフロー方向を決定するアンカーの役割を果たすため、PCB設計チームとの緊密な協議を通じて決定されるべきです。
3. Power Planning: 生命を吹き込む血管、PDN設計
Power Planningとは、チップ全体に電源(VDD)と接地(VSS)を安定的かつ均一に供給するためのPDN(Power Delivery Network)を構築するプロセスです。微細プロセスへの移行に伴い、供給電圧は低下する一方で(Threshold Voltageの減少)、 デバイス密度の増加による電流密度は急増しています。
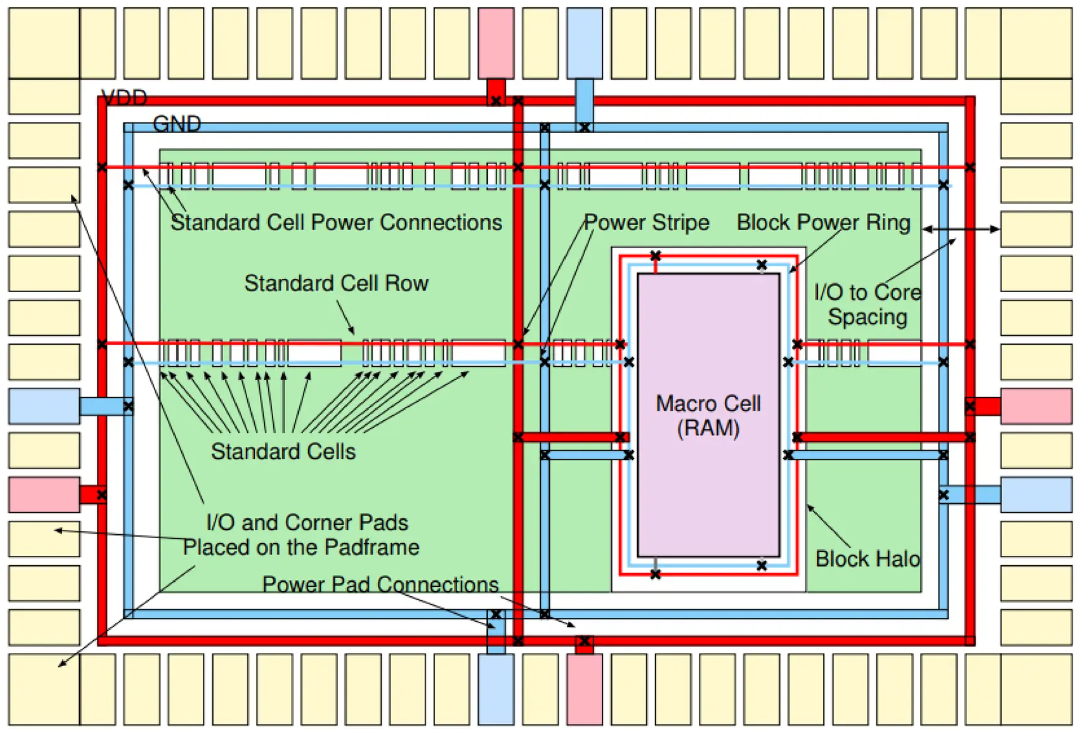
これにより発生するIR DropとElectromigration(EM)の問題は、チップの信頼性問題とFunctional Failureを引き起こす最大のリスク要因となりました。
3.1 PDNアーキテクチャの階層構造
効率的な電源供給網は階層的な網目構造を持っています。
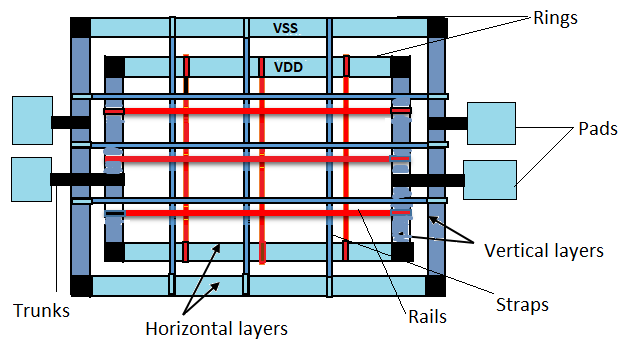
- Power Rings: チップのコア外周全体を覆う、あるいは電力消費の大きいマクロブロックの周囲を取り囲む太い電源線です。外部電源が最初に到達する貯水池のような役割を果たします。
- Power Stripes (Trunks): チップを横断し、電流をコア内部の奥深くまで伝達する主要幹線です。抵抗を最小化するため、最上層の厚いメタル層(Top Metal Layers)を使用し、 適切な間隔(ピッチ)で配置され、IRドロップを制御します。
- 電源レール(Power Rails): 標準セルのVDD/VSSピンに直接接続される最下層の電源線です。主にM1(Metal 1)層に形成され、フォローピンとも呼ばれます。 すべての標準セルは、このレールに接続されて電源を供給されます。
- ビア(Vias): 各層の電源線を垂直に接続する通路です。単一のビアは抵抗が大きく、EM(電磁気)の影響を受けやすいため、ビアアレイ(Via Array)やバービア(Bar Via)を使用して接続性を強化する必要があります。
3.2 IR Dropの物理学と対応戦略
IR Dropは、電源線自体の抵抗(R)により電流(I)が流れるときに電圧が低下する現象(V=IR)です。
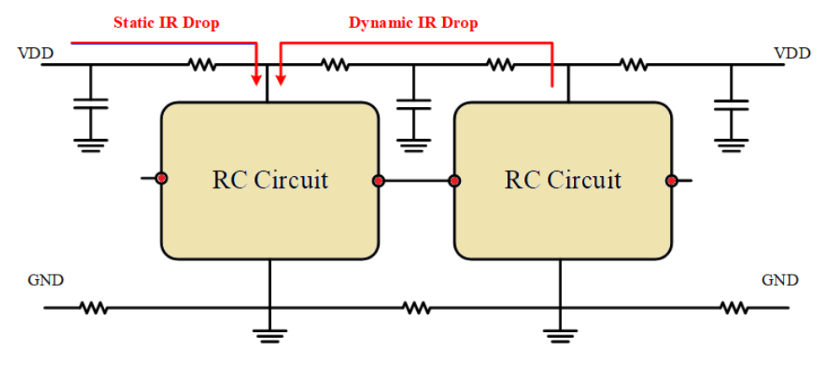
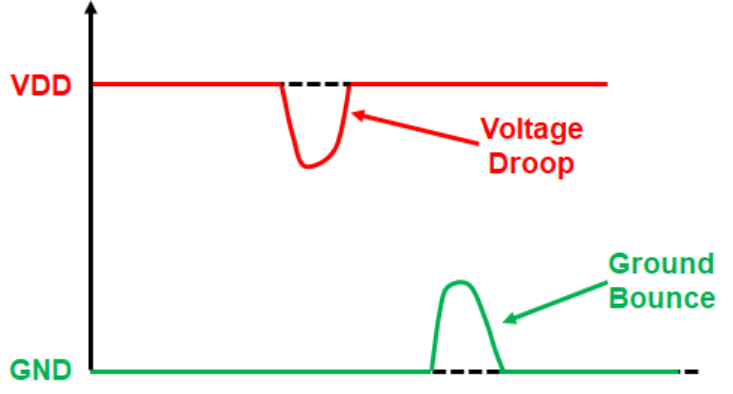
- 静的IRドロップ: スイッチングが発生しない状態や、平均的な電流が流れる際の電圧降下です。
- 解決策 - 該当電源ルーティングの総抵抗を減らす: ストライプの幅を広げるか本数を増やして並列抵抗を減少させるか、あるいはこちら側のセル数を減らす方法で解決できます。
- 動的IR降下: 主にクロックエッジで多数のフリップフロップとロジックゲートが同時にスイッチングする際に発生する瞬間的な過渡電流による電圧降下です。これはL(di/dt)ノイズと組み合わさって深刻な電圧変動を引き起こし、タイミング遅延やデータ誤動作を発生させます。
- 解決策 - デカップリングコンデンサ (Decap): 電源ピン近くにDecapセルを配置し、ローカルなエネルギー貯蔵庫として機能させます。瞬間的な電流需要が発生した際、遠くの電源パッドではなく隣接するDecapから電荷を供給することで、Dynamic IR Dropを緩和します。
4. 配置
配置とは、合成されたネットリストの論理ゲートを、フロアプランで定義された物理的空間内の具体的な座標(x, y)に割り当てるプロセスです。 目標は、単にセルを配置することだけでなく、タイミング、消費電力、面積を最適化しながら、後続の段階である配線が可能(配線可能)な状態を作ることです。
4.1 配置メカニズム:粗から細へ
現代の配置エンジンは、数百万個のセルを処理するために多段階最適化手法を使用します。
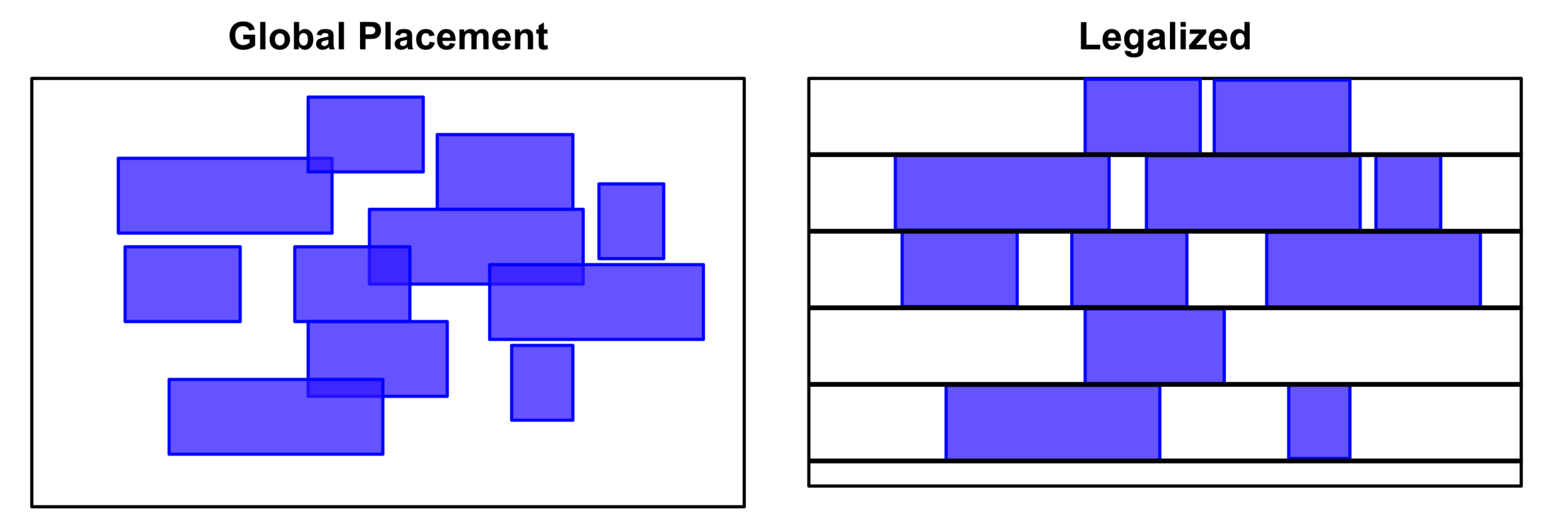
- グローバル配置(粗配置):
- セルをサイズのあるオブジェクトではなく、数学的な点としてのみ扱います。
- 解析的配置: 二次または非線形最適化strong>手法を用いて全体の配線長を最小化します。
- 密度ペナルティ/静電力モデル:セルが凝集するのを防ぐため、セル同士を互いに押し出す電荷としてモデル化し、配線長の最小化(引力)と密度の均一化(斥力)の平衡点を探ります。
- その結果、セルはおおまかな位置に分布しますが、Overlapが存在し、Standard Cell Rowに整列されていない状態です。
- Legalization:
- Global Placementの結果に基づき、すべてのセルを実際に製造可能な位置に移動させます。
- セルを Standard Cell Row および Site Grid に正確に整列(スナップ)させ、オーバーラップを解消します。この際、変位を最小限に抑え、前の段階の最適化結果を保持することが重要です。
- 詳細配置:
- 合法化後に微調整を行います。 隣接セル間のSwappingや空きスペースの移動を通じて、Local Wirelengthを削減し、Pin Accessibilityを改善します。
4.2 輻輳管理とセルパディング
特定の領域で ピン密度 が過度に高い場合、配線 段階で トラック が不足する 輻輳 が発生し、これが DRC 違反 (ショート/オープン) の主な原因となります。
- セルパディング (Bloating): Congestionが予想される複雑なセルの周囲に仮想のPaddingを設定します。 これにより物理的な距離を確保し、配線が通過できるPorosityを提供します。
- Congestion Map: Global Routing予測モデルを通じてチップ全体の混雑度をHeatmap形式で分析し、Hotspot領域のセルを分散させるCell Spreading技法を適用します。
5. Clock Tree Synthesis (CTS): Temporal Synchronization
Clock Tree Synthesis (CTS)は、クロック信号をチップ内部の無数のSequential Elements (Flip-flops)に同時かつ完全な形で伝達するプロセスです。クロックネットワークは全体のPower Consumptionの30~40%を占め、その品質はチップのPerformanceを決定づける核心要素です。
5.1 CTSの主要指標
CTSの目標は、以下の指標を精密に制御することです。
- レイテンシ: クロックソースからフリップフロップに到達する絶対的な時間です。 レイテンシが長いほど、OCV (On-Chip Variation) の影響を大きく受け、タイミングの不確実性 が増大するため、可能な限り短く保つ必要があります。
- Skew: クロックソースから早く到着する Flip-flop と遅く到着するものの時間差。つまり、Sink pin の Latency の差です。Global Skew は 0 Skew が原則ですが、隣接する Register 間の Local Skew を調整して Setup/ホールドマージンを確保する有用なスキュー手法が近年より多く活用されます。
5.2 クロックトポロジー
従来のツリー構造から、高性能コンピューティングのためのメッシュ構造まで、様々なトポロジーが存在します。
6. ルーティング:数十億の点を結ぶ迷路探し
ルーティングとは、配置されたセルのピンを設計ルール(DRC)に準拠しながら、実際に金属線で接続する段階です。 このプロセスは、数学的にNP-Hardの複雑度を持つ迷路探索(Maze Routing)問題の連続です。
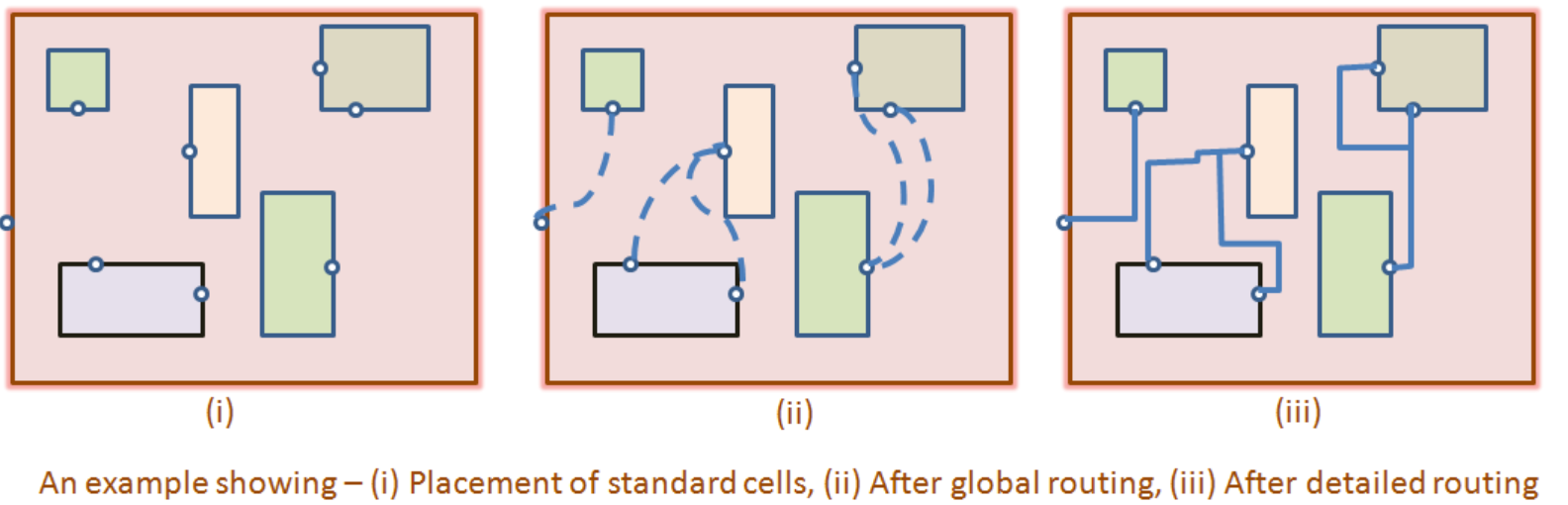
6.1 配線ステージ:パスからジオメトリへ
配線プロセスは、設計の複雑さを制御するために段階的に進められます。
- グローバル配線:
- チップ全体をGCell (Global Cell)領域に分割して管理します。
- 具体的なTrackを指定する前に、Pin-to-Pin接続のために通過すべきGCell経路を探索します。
- 主な目標はCongestionの管理です。各GCell BoundaryのRouting Capacityと実際のRouting Demandを比較し、Detour経路を生成することで混雑を分散させます。
- トラック割り当て:
- グローバルルーティングの結果に基づき、各ネットを特定のメタル層の具体的なトラックに割り当てます。
- 直線配線を優先的に配置し、ビアの使用を最小限に抑え、ルーティング効率を高めます。
- 詳細ルーティング(ナノルーティング):
- グローバルルーティングの結果に基づき、各ネットを特定のメタル層の具体的なトラックに割り当てます。
- 直線配線を優先的に配置し、ビアの使用を最小限に抑え、ルーティング効率を高めます。
- 詳細ルーティング(ナノルーティング):
- グローバルルーティングの結果に基づき、各ネットstrong>の使用を最小限に抑え、配線効率を高めます。
- 詳細配線 (ナノ配線):
- 割り当てられたトラック内で、実際の物理的な形状を作成します。
- ピンアクセスのための微細なJogの作成、 Via 生成、そして数千もの DRC (Spacing, Width, Enclosure など) ルールへの準拠を確認し修正します。
6.2 信号の完全性 (SI) & クロストーク
プロセス微細化に伴い、配線の厚さに対する幅の比率が大きくなるにつれ、隣接配線間の結合容量によるクロストーク現象が深刻化します。
- クロストーク遅延: アグレッサーとビクティム配線が互いに反対方向にスイッチングするとき、結合効果により信号伝達時間が長くなり、セットアップ違反を引き起こします。逆に同じ方向にスイッチングホールド違反の原因となります。
- クロストークノイズ(グリッチ): 被害側配線が停止状態にあるとき、加害側のスイッチングによって望ましくない電圧スパイク(グリッチ)が誘導される現象です。これは論理値を反転させ、機能的なエラーを引き起こす可能性があります。
- Mitigation Techniques: Spacingの確保、配線間のShielding線の挿入、またはAggressor CellのDrive Strength調整技法などが使用されます。
6.3 アンテナ効果と製造上の問題点
製造工程におけるプラズマエッチング段階で、長い金属配線がアンテナのように作用し電荷を収集する現象です。蓄積された電荷が接続されたトランジスタのゲート酸化膜に放電されると、素子が永久的に破損する可能性があります。
- アンテナ比率: ゲート面積に対する配線の面積比率を制限して管理します。
- 解決策:
- ジャンパー挿入: 配線途中にレイヤーを変更するジャンパーを挿入し、配線長を物理的に断ち切ります。
- アンテナダイオード: ゲート付近に逆ダイオードを挿入し、蓄積された電荷を基板へ安全に放電します。
実際のフローでは、Placeの次にPlace_optを行い、 Routeの次にはRoute_optを行うというように、optが途中に継続的に含まれます。
7.Chipfinish
P&R(配置配線)プロセスの最終段階であるチップ仕上げは、設計されたチップが実際に製造されるよう物理的な完成度を高める作業です。
前段階の配線までが「機能的な接続」を完成させるものだったのに対し、 チップフィニッシングは、製造上のエラーを防止し歩留まりを高めるためのDFM(Design for Manufacturability)の性格が強いです。
7.1. フィラーセル挿入 (スペースセル)
スタンダードセルが配置されると、セルとセルの間に空きスペースが生じます。
このスペースをそのままにすると、基板の電位特性が変化します。これを密度問題と呼びます。論理機能を持たず物理的役割のみを果たす「フィラーセル」で埋め、均一な特性を確保します。
7.2. 金属充填(ダミーメタル)
半導体プロセスには、ウェーハ表面を平坦に削り取るCMP(化学機械研磨)プロセスがあります。 この時、チップ全体のメタル密度が均一でない場合、ある部分はより多く削られ、ある部分はより少なく削られる現象(ディッシング/エローション)が発生します。
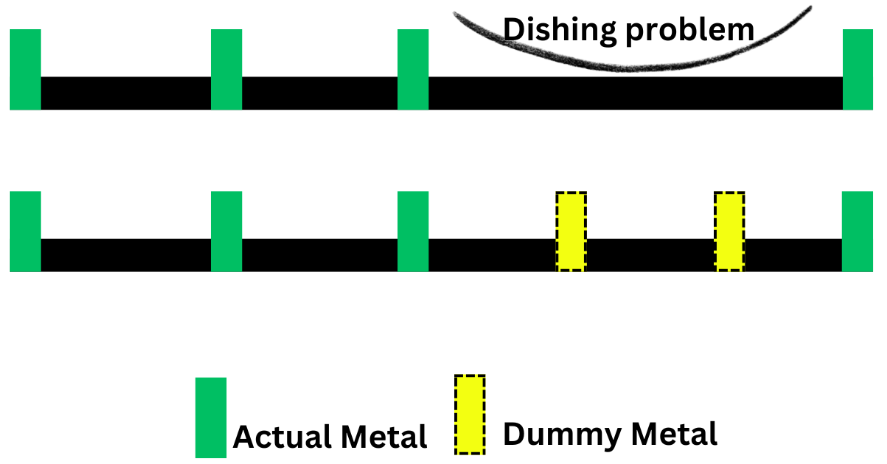
- 作業: 回路動作と無関係な「ダミーメタル」の断片を空いたスペースに埋め込み、金属密度を均一にします。
- 効果: チップの平坦性を確保し、配線不良や断線を防止します。
3. アンテナ効果の修復
プロセス中のプラズマエッチング段階では、長い金属配線がアンテナのように電荷を集めます。この蓄積された電荷が接続されたゲート酸化膜に放電されると、ゲートが破壊される可能性があります。
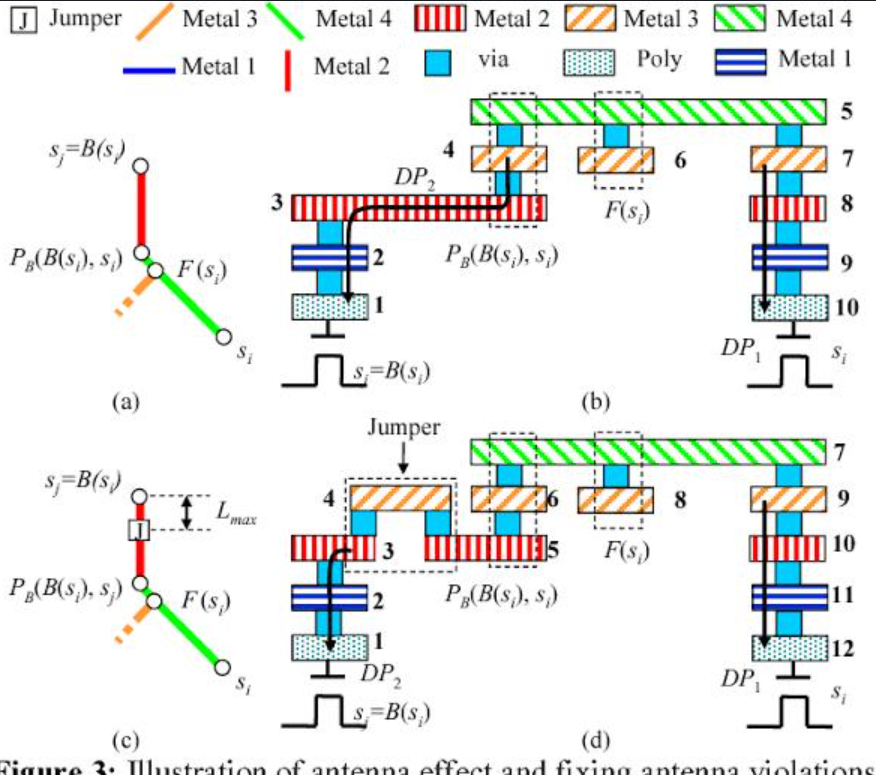
Tsai, Chia-Chun et al. “Antenna Violation Avoidance/Fixing for X-clock routing.” 2010 11th International Symposium on Quality Electronic Design (ISQED) (2010): 508-514.(Jump) 製造工程順序上、電荷が蓄積される長さを物理的に断ち切ります。
4. ビア最適化(冗長ビア挿入)
配線層間を接続する穴であるビアは、工程中に抵抗が高くなったり断線する確率(オープン欠陥)が最も高い脆弱点です。
- 作業: スペースが許す限り、シングルビア(ビア1個)をダブルビア(ビア2個)またはそれ以上に変更します。
- 効果: 1つのビアが不良になっても、残りが接続を維持するため、チップの歩留まりと信頼性が大幅に向上します。
5. Final Verification Preparation (最終検証準備)
この段階が終了すると、ようやくGDSII (またはOASIS)フォーマットでデータを抽出(Stream Out)し、物理検証段階(Physical Verification)へ移行する準備が整います。
- DRC (Design Rule Check): プロセスルール違反の有無
- LVS (Layout Versus Schematic): 回路図とレイアウトの一致性確認
チップ仕上げは設計の'機能'を変更するものではありませんが、チップが'死なずに生まれるように'するための決定的な段階です。
結論:P&R、先端工学の総合的集約
これまで見てきたように、 VLSI物理設計はパーティショニングからチップフィニッシュに至る有機的かつ高度に複雑なエンジニアリングプロセスです。ネットリストという論理設計をGDSIIという物理的実体へ変換する過程は単純な変換ではなく、物理的制約(IR Drop, EM, Antenna)、電気的制約(タイミング、SI、クロストーク)、そして製造プロセスの制約(DRC、DFM)をすべて満たす最適解を探求する旅路です。
特にFinFETやGAAといった次世代プロセスの導入は、P&Rエンジニアに量子化されたセル高さ、RDR、 Self-heatingなど新たな次元の課題を提示しています。したがって現代のP&Rは、EDAツールの自動化機能のみに依存しては決して成功できず、各段階の基盤となるアルゴリズム的原理と物理的現象に対するエンジニアの深い洞察力が不可欠です。
p>
データの流れを読み取るフロアプラン能力、電力完全性を保証するPDN設計能力、そして数十ピコ秒(ps)のタイミングを合わせるECO能力の調和こそが、成功するフロアプラン設計の鍵です。
p>データの流れを読み取るフロアプラン能力、電力整合性を保証するPDN設計能力、そして数十ピコ秒(ps)のタイミングを合わせるECO能力の調和こそが、成功したチップの誕生を保証できるのです。