したがって、検証エンジニアの目標は、単にバグを見つけることを超え、「バグがない」という事実を統計的かつ論理的な証拠を通じて確信させることにあります。
2. 検証方法論のパラダイム転換: DirectedからConstrained Randomへ
数十年前、数百ゲートレベルの設計を検証していた時代には、エンジニアが予測可能なシナリオを一つ一つコーディングするDirected Testing方式が主流でした。しかしVLSI規模の複雑さを持つ現代の設計において、人間の予測能力のみに依存することはほぼ不可能です。 この限界は検証方法論の根本的な変化をもたらしました。
2.1 Directed Testing: 直感的だが限界が明確なアプローチ
Directed Testingは、検証エンジニアが機能の動作可否を確認するために、
検証者が直接Stimulus inputとExpected Outputを明示的に記述する方式です。例えば、プロセッサ検証において「A命令の次にB命令を実行し、レジスタ値がCであるか確認せよ」といったテストがこれに該当します。
この方式の利点は明らかです。テストの意図が明確であるためデバッグが容易で、初期のBring-up段階で基本的な機能動作の有無を迅速に確認するのに有利です。
しかし致命的な欠点は、「エンジニアが想定しなかったシナリオ」は絶対に検証できないという点です。複雑なPipeline Stall、 非同期インターフェース間の競合状態、例外的なエラー処理などは、人間の頭で全ての組み合わせを列挙することは困難です。また、設計仕様が変更されるたびに手動で作成されたテストケースを一つ一つ修正しなければならないため、保守コストが指数関数的に増加します。
2.2 制約付きランダム検証 (CRV)
このようなDirected Testingの限界を克服するために登場したのが制約付きランダム検証 (CRV)です。
CRVはSystemVerilogのオブジェクト指向プログラミング機能とランダム化機能を活用し、状態空間を無作為に探索しつつ有効な範囲内で制約を設け、テストベンチを生成して検証する方式です。
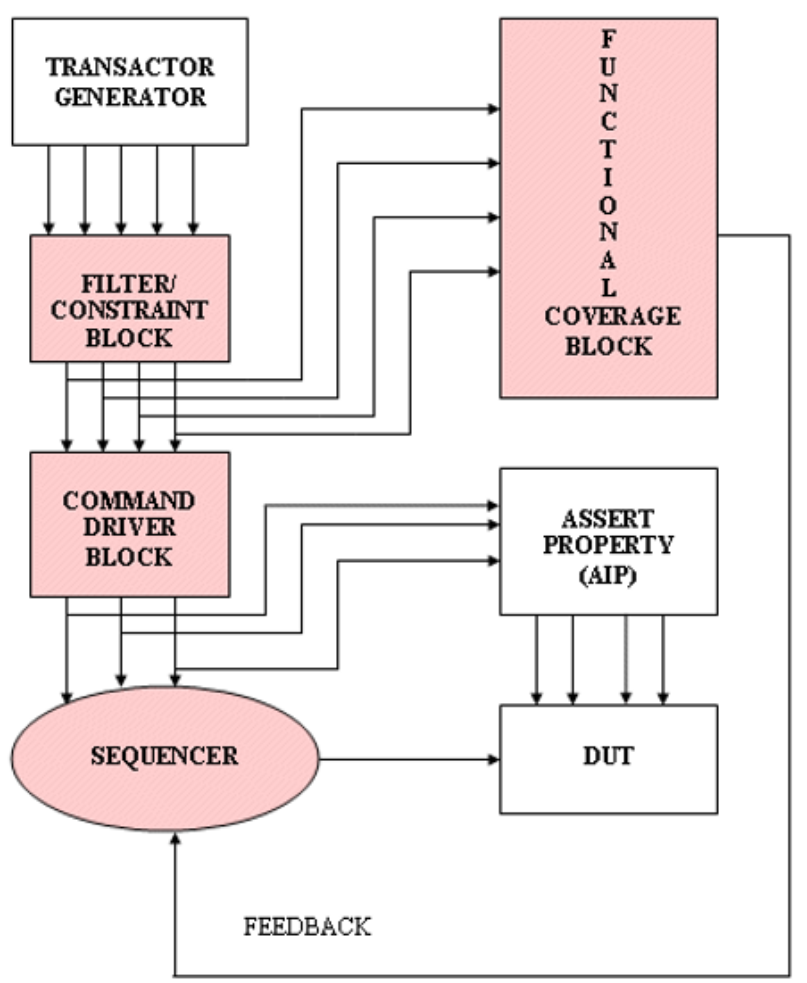
CRVの核心は、ランダム性、自動化、探索です。
エンジニアは個別のテストベクトルを作成する代わりに、 データパケットの構造とプロトコル規則(制約)のみを定義します。シミュレータはrandomize()関数を呼び出すたびに、毎回異なるデータ、アドレス、遅延、制御信号の組み合わせを生成します。例えば、constraint valid_addr { addr < 1024; }のような制約条件を通じて、有効なアドレス空間内でのランダムアクセスを試行させます。
人間が想定し得ないコーナーケース、例えば「FIFOが満杯の状態で突然リセットがかかり、同時に割り込みが発生する状況」といった複雑なシナリオをシミュレータが生成します。
3. UVM (Universal Verification Methodology)
CRVを効果的に実装するためには、堅牢で再利用可能なフレームワークが必要です。これがまさにUVM (Universal Verification Methodology)が誕生した背景であり、現在業界標準として定着した理由です。
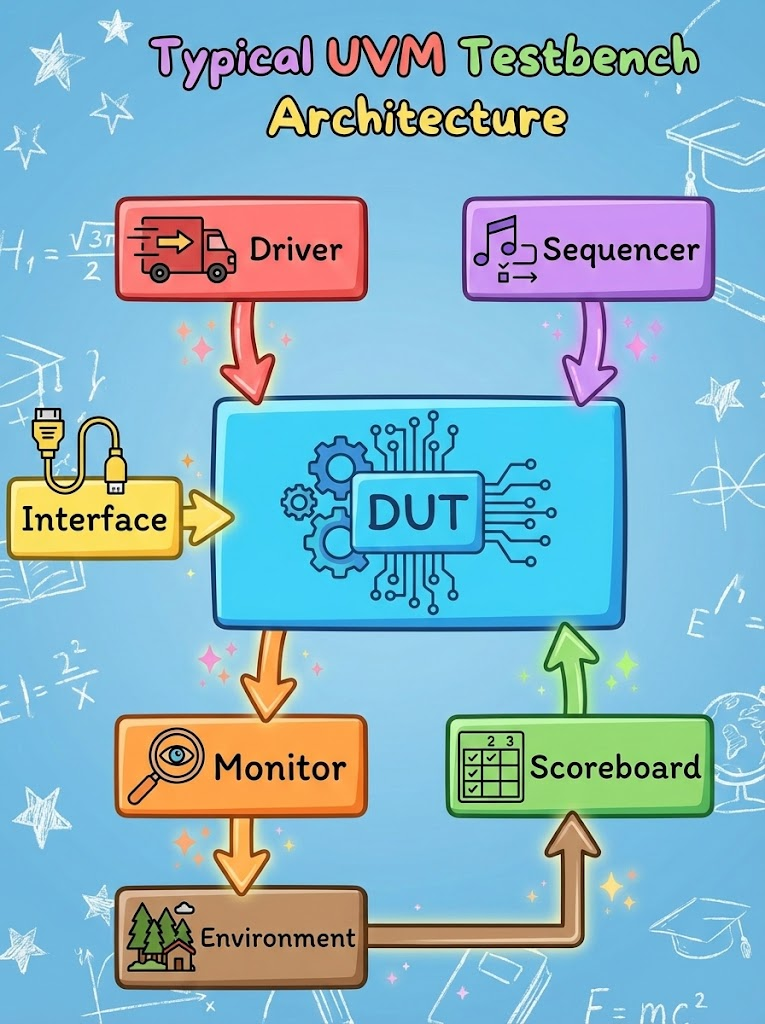
多くのジュニアエンジニアは、UVMの複雑なクラス階層構造と膨大なマクロの前に挫折しがちです。しかし、各コンポーネントの存在理由と役割(Role)を理解すれば、UVMが非常に論理的な構造であることがわかります。
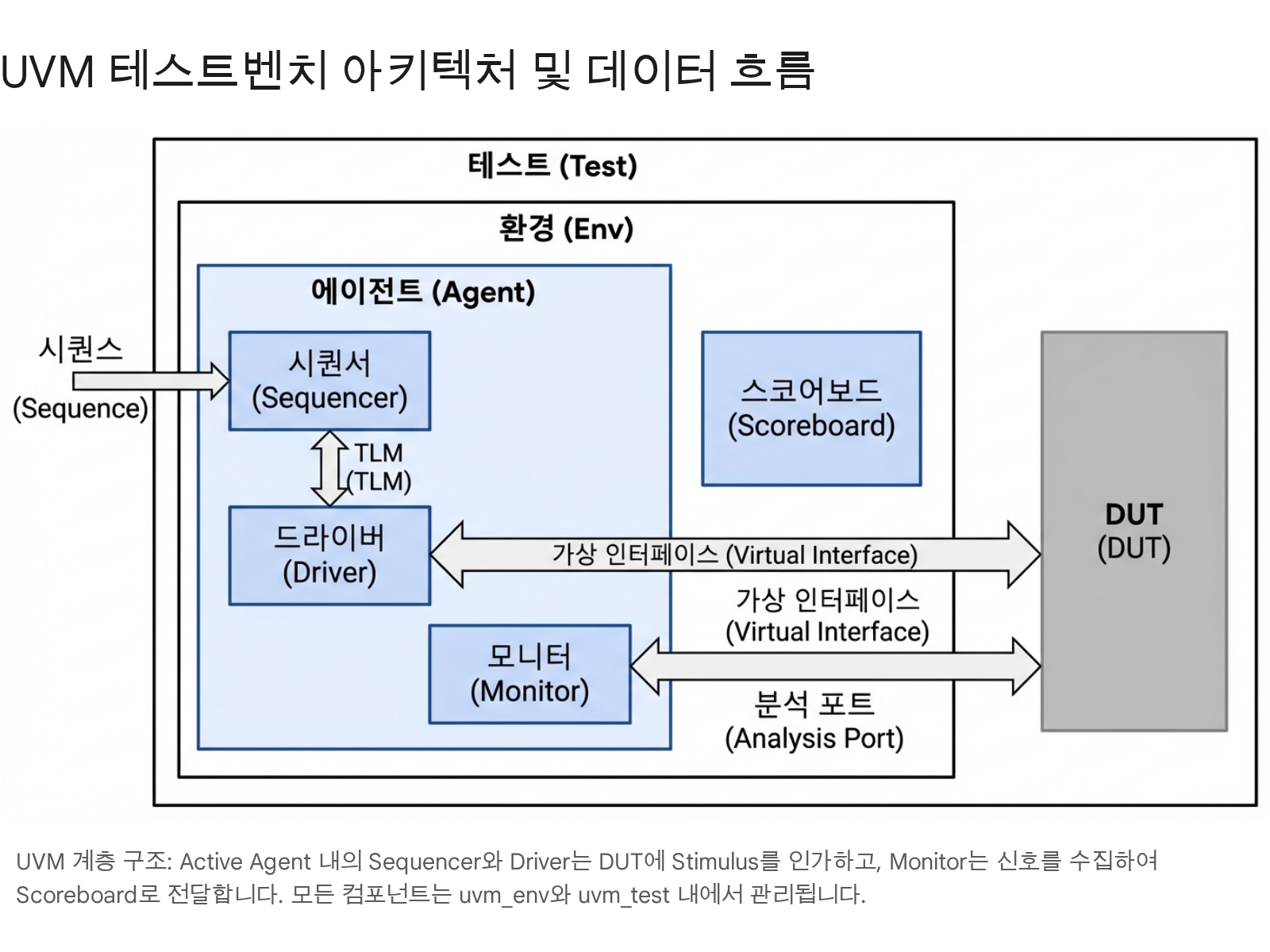
3.1 UVMテストベンチの哲学:関心事の分離 (Separation of Concerns)
UVMの核心的な哲学は、検証環境を機能別に徹底的にモジュール化することです。つまり、刺激を生成する役割(Generation)、信号を駆動する役割(Driving)、信号を監視する役割(Monitoring)、そして正解を判定する役割(Checking)を互いに異なるコンポーネントに分離します。これにより、特定のプロトコル(例: PCIe)向けの検証環境を作成した際、これを他のプロジェクトでも容易に流用できる再利用性(Reusability)を確保します。
3.2 核心構成要素の詳細分析
3.2.1 Sequence Item (Transaction): 抽象化の始まり
検証の最も基礎的な単位は uvm_sequence_item です。これはピン(Pin) レベルの信号(0と1)を、意味のある情報の塊である 'トランザクション'として抽象化したオブジェクトです。例えば、AXIバスでは数多くの制御信号が行き来しますが、トランザクションレベルではアドレス、データ、読み取り/書き込み、バースト長などの属性のみで表現されます。これにより、検証エンジニアは複雑なタイミングから離れ、データの流れそのものに集中できます。