AI 반도체 설계 분야에서 의미 있는 수익을 내는 주체를 정리하면 아래와 같다.

- NVIDIA와 Google
- Hyperscaler들이 사용할 전용 반도체를 대신 만들어주는 Broadcom과 Marvell, Qualcomm, MediaTek 과 몇 개의 반도체 회사 정도. 손에 꼽는다.
나머지는 이 가치사슬의 어딘가에 끼어 있거나, 끼지 못한 채 narrative와 자본으로 버티고 있다.
대부분의 AI 반도체 기업들은 영업이익을 만들지 못하고 있다.
그러나 동시에, 2026년 글로벌 AI 반도체 스타트업 펀딩은 사상 최대를 기록했다.'
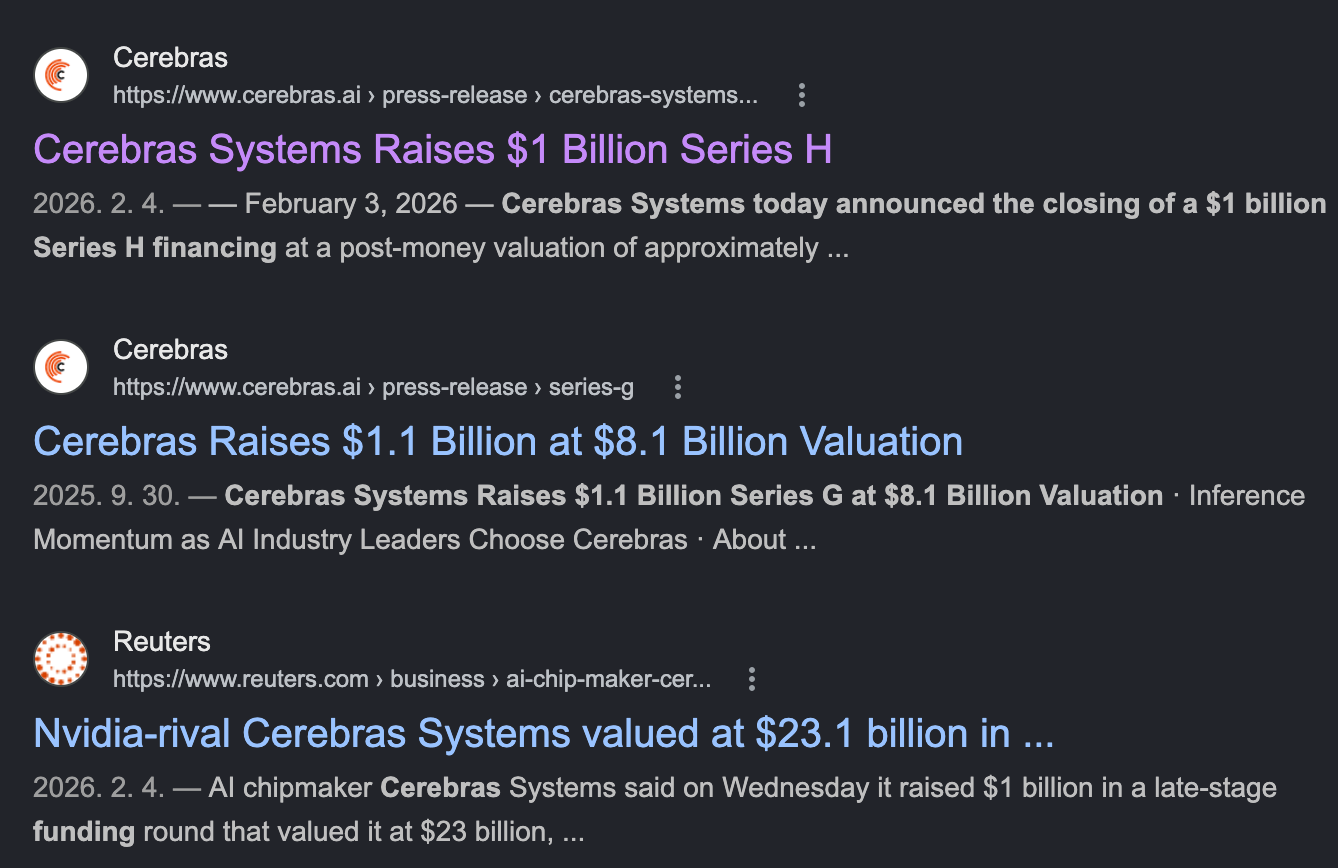
Cerebras $1B, Etched $500M, MatX $500M, Ayar Labs $500M, d-Matrix $275M 등 메가 라운드가 줄을 잇는다. Cambricon의 시가총액은 한때 $90B에 근접했고, Moore Threads는 STAR Market 상장 첫 날 5배 급등했다. 글로벌 펀딩 규모가 $8.3B에 도달했다.
매출은 부재하지만 투자는 폭주한다
AI 반도체 투자는 계속되는데, 성공한 기업은 하나도 없다.
대표적인 낙관론과 비관론 양쪽의 가장 강한 논리를 짚은 후, 가장 가능성 높은 outcome 분포를 정리한다.
낙관론 근거 1: Inference workload의 분화라는 architectural 기회
낙관론의 가장 견고한 논리는 AI inference workload가 architecturally 분화하고 있다는 점이다.
- 현존하는 AI Model들은 이미 세상에 공유된 모든 데이터들을 학습했고, 앞으로는 추론을 잘하는 것이 중요해진다.
- Training은 GPU를 이길 수 있는 반도체가 없었다.
- Inference분야는 맞춤복처럼 소프트웨어에 딱 맞게 설계된 반도체가 최고다.
- Training은 homogeneous하다.
- Transformer에 대규모 GPU 클러스터, NVLink/InfiniBand 인터커넥트, FP8/FP16 연산이다.
- NVIDIA가 압도적인 이유는 이 단일 architecture에 모든 것을 최적화했기 때문이다.
- Inference는 phase별로 요구사항이 다르다.
- Long-context prefill은 compute-bound
- decode는 memory bandwidth-bound
- real-time speech/translation은 ultra-low-latency를 요구
- recommendation/ranking은 sparse tensor를 다루며
- edge inference는 power envelope이 다르다.
다시말해, 추론의 시대에서는 전용반도체가 범용 반도체를 이긴다.
- Groq의 LPU는 SRAM-heavy deterministic dataflow로 token generation latency에서 GPU 대비 한 자릿수 ms로 우위를 보였다.
- SambaNova의 RDU(Reconfigurable Dataflow Unit)는 동일 logic으로 batch latency를 줄였다.
- Cerebras의 wafer-scale engine은 메모리-컴퓨트 거리를 wafer 한 장 안으로 압축해서 large model inference에서 H100 대비 throughput 우위를 시연했다.
- Etched의 Sohu는 transformer 외 모든 architecture를 포기하고 transformer-only ASIC으로 H100 대비 20배 throughput을 marketing한다.
- d-Matrix의 Corsair는 Digital In-Memory Compute(DIMC) 아키텍처로 LPDDR과 SRAM을 결합해 GDDR/HBM 경제성을 우회한다
- Lightmatter, Celestial AI, Ayar Labs는 silicon photonics로 메모리-컴퓨트 인터커넥트의 전력 문제를 공격한다.
이론적으로 이 thesis는 견고하다. Workload가 분화하면 specialized chip의 경제성이 살아난다. 90년대 후반 GPU가 CPU에서 그래픽 워크로드를 떼어낸 것과 동일한 architectural separation이 inference에서도 발생할 수 있다.
낙관론 근거 2: Sovereign AI라는 신시장

두 번째 낙관 논리는 sovereign AI다.
- 미래에 AI는 서비스업, 방산, 모든 산업에 필요하게 될 것이다.
- 현재 AI를 구동 할 수 있는 대부분의 반도체는 미국에서 나온다.
- 현대의 자유 무역은 이미 끝났고, 관세 전쟁, 수출 제재가 만연하다.
즉, 미국 빅테크가 독점한 AI 인프라에 대한 비미국권 국가들의 정치적 불안이 AI 주권 (Sovereign AI)라는 새로운 수요 카테고리를 만들었다.
UAE, 사우디, EU, 일본, 한국, 인도, 인도네시아, 말레이시아 모두 자국 AI 인프라 구축에 수십억 달러를 투입한다.
이들은 가격 경쟁이 아니라 공급망 다양화, 정치적 안전성, 데이터 주권, 공급망 자율성으로 sourcing 결정이 내려진다. NVIDIA의 절대 우위가 일부 무효화되는 시장이다.

- d-Matrix의 Series C에 카타르 투자청과 Temasek이 들어왔다.
- Rebellions cap table에 Saudi Aramco가 있다.
- 모두 sovereign customer를 노린 positioning이다.
미국의 수출규제, 관세 압박 우려가 커질수록, NVIDIA가 못 가는 시장이 생기며, 이는 AI Startup들의 기회가 된다.
중국이라는 강제 분리된 시장
중국 시장은 sovereign AI의 가장 극단적 형태다.

미국 수출제재가 NVIDIA의 중국 데이터센터 AI chip 시장점유율을 95%에서 바닥으로 무너뜨리면서, 그 자리에 Cambricon, Moore Threads, MetaX, Biren, Huawei HiSilicon이 들어갔다.
Cambricon의 2025년 매출은 전년 동기 대비 14배 증가했고 첫 분기 흑자를 기록했다. ByteDance의 대규모 주문이 이 변화를 견인했다.

- Cambricon은 2026년 50만 개 AI 칩 출하를 목표로 한다
- Moore Threads는 88일 만에 STAR Market IPO 심사를 통과해 12월 5일 상장했고
- MetaX가 2주 뒤 상장되었다.
- Biren은 2026년 초 홍콩 상장을 단행했다.
젠슨황과 증권 애널리스트들은 중국이 자국 AI 칩 수요의 대부분을 국내 공급만으로 충당할 수 있는 단계에 진입했다고 본다.
이 현상은 product market fit의 결과가 아니라 정치적 분리의 결과다.
그러나 결과적으로 중국 AI 칩 스타트업들은 매출 성장과 자본 시장 접근이라는 두 가지를 모두 확보했다. 글로벌 시장에서 competing하는 게 아니라 강제로 분리된 중국 시장에서 dominating하는 모델이 가능하다는 것을 증명했다.
낙관론 근거 3: Capital market fit이 product market fit을 대체한다
세 번째 논리는 다소 cynical하지만 가장 실용적이다. AI 반도체 스타트업의 운영 자금은 product market fit이 아니라 capital market fit에서 나온다.

- 매출이 늦어도 narrative이 있으면 valuation이 유지되고
- valuation이 유지되면 다음 라운드가 들어오며
- 충분히 큰 라운드들이 누적되면 IPO 시점까지 도달하거나 incumbent 인수로 exit한다.
FuriosaAI가 Meta의 $800M 인수 제안을 거절하고 IPO를 노리는 이유도 동일하다.
Groq은 product revenue가 거의 없는 상태로 NVIDIA에 $20B에 인수됐다 — 펀딩 누적 $210M 대비 100배에 가까운 multiple이다. 자본 시장은 매출이 아니라 narrative와 talent와 IP를 valuation한다.
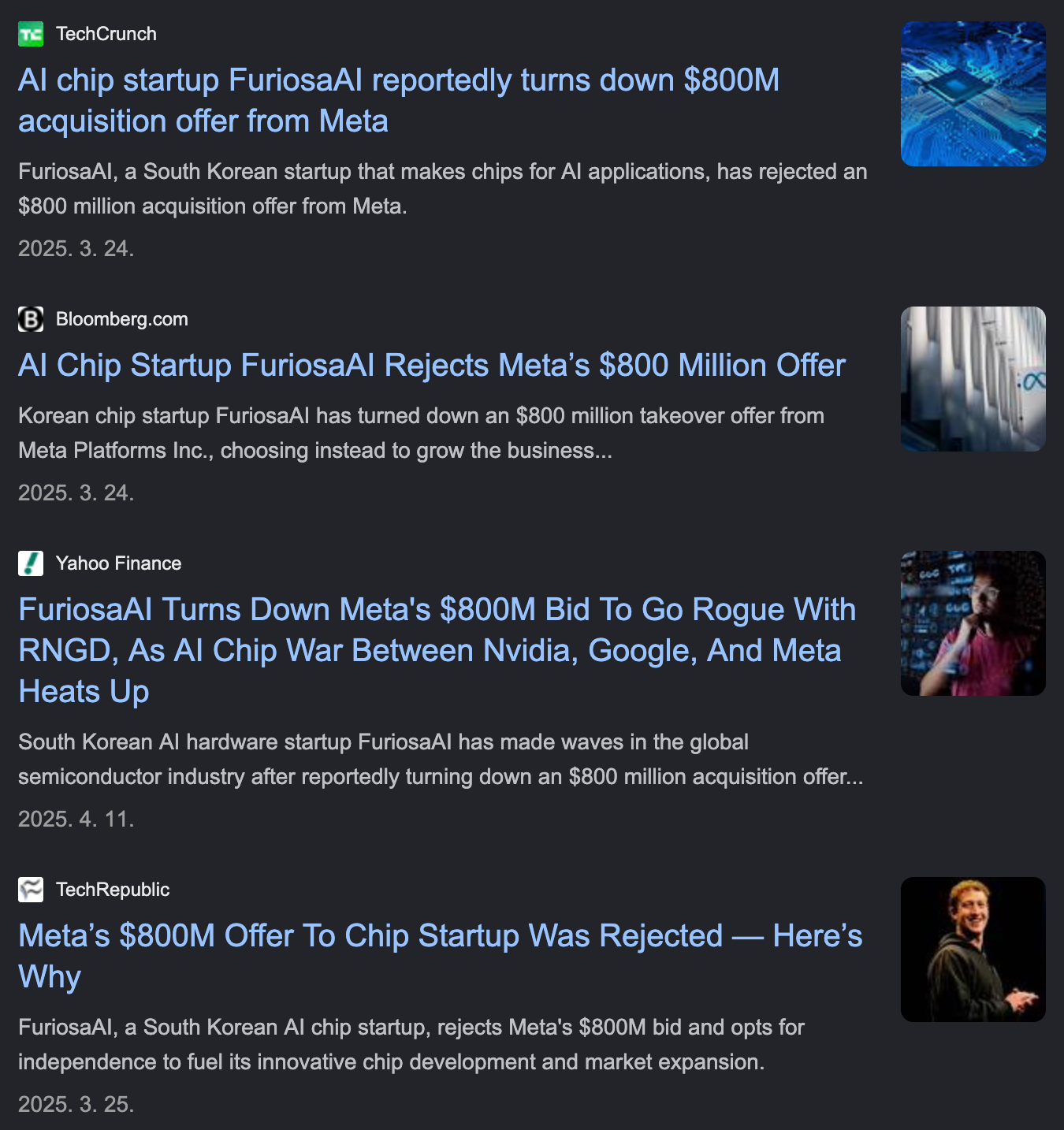
Etched는 VC 투자 관련 흥미로운 예시이다.

- 하버드 중퇴생 두 명이 2022년에 창업해 2026년 3월 시점까지 customer에 chip을 출하하지 않았지만, 총 $625M+ 펀딩을 받았으며 $5B valuation에 도달했다.
- Peter Thiel, Stripes, Ribbit Capital이 들어왔다.
- Independent benchmark 조차 존재하지 않고 raw TFLOPS도 공개되지 않은 상태에서 "transformer가 5-10년 더 지배할 것"이라는 thesis와 창업자 background 만으로 $5B이 베팅됐다.
Cerebras IPO가 가능했던 이유는 매출 multiple이 아니라 "AI 시대의 NVIDIA 대안"이라는 narrative였다.

낙관론자들은 이 자본 사이클이 최소 5-7년은 더 지속될 것으로 본다. AI capex가 hyperscaler 4사 합산 연간 $400B 규모로 올라가는 상황에서, 자본 시장은 "AI 익스포저"를 갈구하고 있으며 NVIDIA 한 종목으로 만족하지 못한다.
비관론 1: 그들은 무엇을 팔고 있는가
비관론의 출발점은 단순하다. 이 회사들이 진짜 돈을 벌고 있는가? 그들의 재무제표는 어떤 상황인가?
- Cerebras의 2025년 매출 $510M은 의미 있는 숫자지만 매출의 약 86%가 UAE 기반 G42와 MBZUAI 두 sovereign 고객에서 나왔다.
- SambaNova는 2024년 매출 추정치가 $100M 이하로 알려졌고, 그나마 system sales보다 service revenue 비중이 컸다.
- Groq은 의미 있는 product revenue 없이 NVIDIA에 인수됐다.
- Etched는 2026년 3월 시점에도 chip 미출하 상태다.
- d-Matrix Corsair는 2025년부터 sampling 시작했지만 매출 규모는 아직 공개되지 않았으며 Series C에서 valuation $2B를 받았다.
- 한국 NPU 회사들은 모두 PoC 매출 위주다. 중국 회사들은 매출이 있지만 강제 분리된 시장 내 매출이며, 글로벌 product market에서의 경쟁력 입증은 아니다.
NPU나 ASIC을 사는 큰손은 결국 hyperscaler이거나 대형 enterprise인데, 그들에게 NVIDIA에서 specialized chip으로 전환하는 비용은 단순한 BOM 비교가 아니다.
CUDA 위에 구축된 모든 모델 코드, 운영 인프라, 모니터링 도구, 개발자 워크플로우, regression test, debugging 도구를 다시 짜야 한다.
- 이 lock-in을 뚫을 수 있는 유일한 customer는 소프트웨어 팀만 in-house team이 수백 명 규모로 있는 곳이다.
- Hyperscaler 4사 정도다. 그런데 hyperscaler들은 NPU 스타트업에서 사는 게 아니라 Broadcom과 Marvell에 ASIC 설계 서비스를 의뢰해서 in-house chip을 만든다.
- Google TPU, Amazon Trainium/Inferentia, Meta MTIA, Microsoft Maia가 모두 그 길을 갔다. NPU 스타트업이 들어갈 자리가 hyperscaler 시장에는 사실상 없다.
남는 시장은 (1) sovereign AI, (2) tier-2 cloud provider, (3) 대형 enterprise on-prem, (4) edge/embedded (5) 혹은 인수되길 기다리는 것이다.
이 시장의 합산 TAM이 NVIDIA 데이터센터 매출($100B+)과 비교하면 한 자릿수 퍼센트 수준이다. 그 좁은 시장을 두고 위 회사들이 모두 경쟁한다.
비관론 2: NVIDIA의 inference 정면 공격: Rubin, Groq LPU
비관론을 결정적으로 강화한 사건은 NVIDIA의 2025-2026 inference 라인업이다. 그동안 inference specialist의 가장 강한 thesis는 "NVIDIA는 training용으로 설계된 GPU라 inference에는 over-spec이고 비효율적"이라는 것이었다. 이 thesis가 정면으로 해체되고 있다.
NVIDIA는 대놓고 "에이전틱 AI 및 고도의 추론을 위한 반도체"를 설계했다.
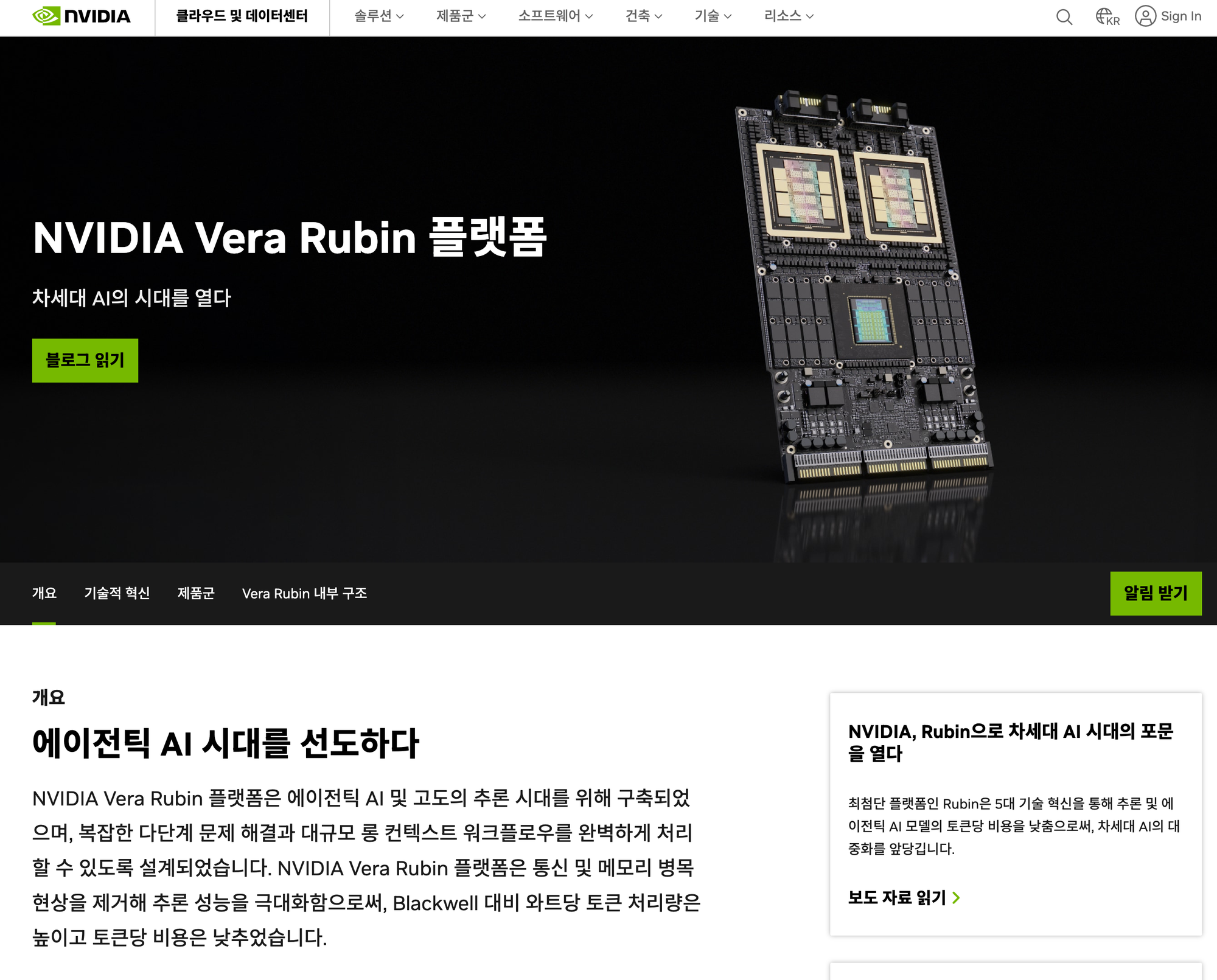
즉, Rubin CPX는 long-context inference 전용으로 설계된 별도 GPU다.
- 30 petaFLOPs NVFP4 연산 성능
- 128GB GDDR7 메모리
- HBM 대신 GDDR7을 쓴 것이 핵심이다.
- Prefill phase는 memory capacity가 많이 필요하지만 ultra-high bandwidth는 필요하지 않다는 사실을 받아들여, NVIDIA는 비용 효율적인 GDDR7로 전환했다.
- Vera Rubin NVL144 CPX rack은 8 exaflops 성능과 100TB fast memory를 한 rack에 담는다.
- hardware video encoder/decoder를 monolithic die에 통합.
LPX는 더 AI 스타트업의 숨통을 조인다. NVIDIA는 Groq을 인수해서 LPU 기술을 자사 rack 아키텍처에 통합했다.
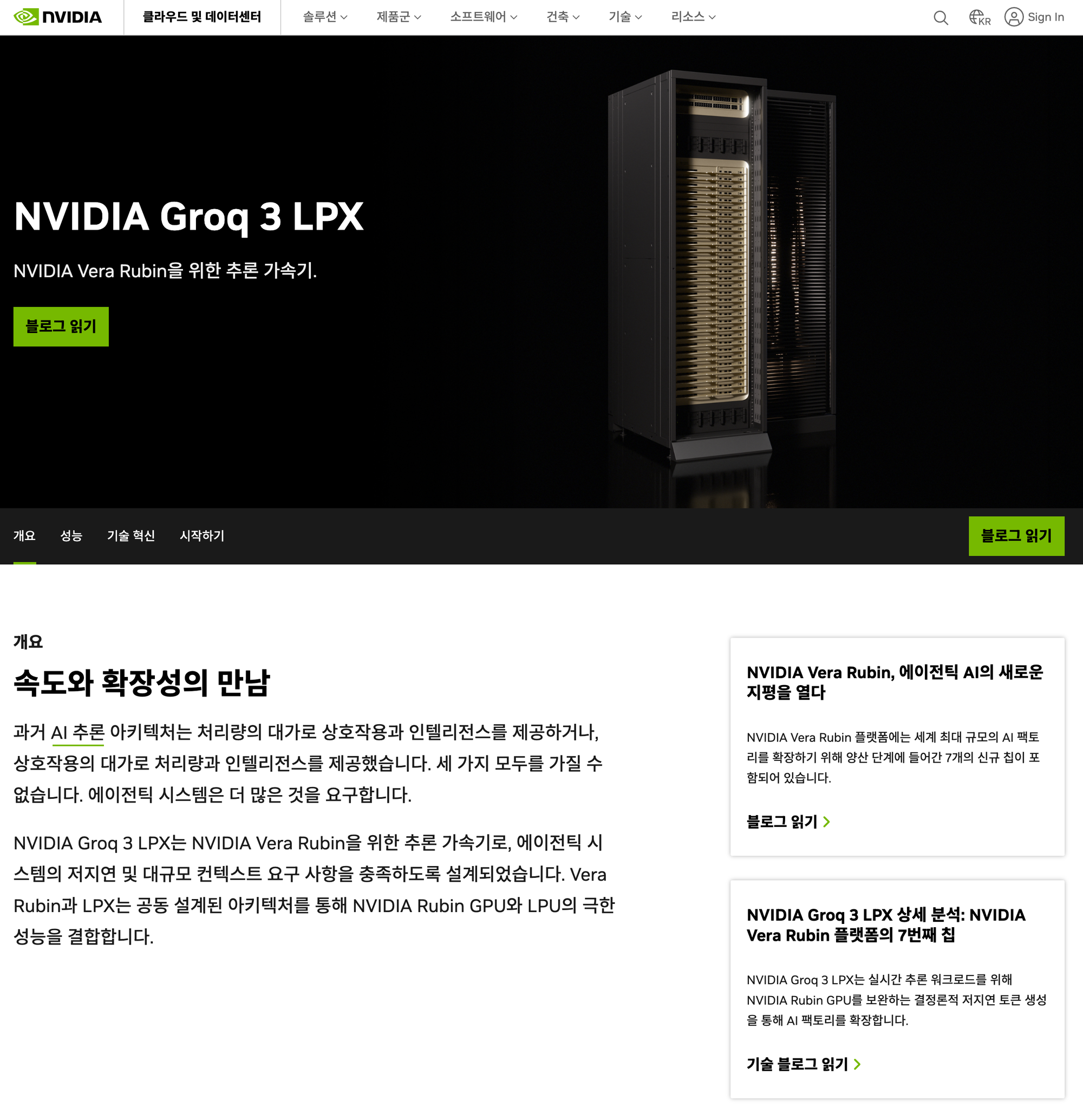
2026년 GTC 기준 256 LPU per rack 구성으로, low-batch ultra-low-latency inference 시장을 직접 공략한다.
결국, Rubin GPU + Rubin CPX + LPX 세 가지 SKU가 inference workload를 phase별로 segment해서 커버한다. Prefill은 CPX, decode와 long-context attention은 Rubin GPU, ultra-low-latency single-batch는 LPX.
스타트업들은 "앞으로 추론의 시대에는 GPU 보다 추론 전용 반도체가 더 좋습니다."를 걸고 창업한 반면, NVIDIA는 Groq을 인수했고, Groq의 반도체에 NVIDIA의 자산인. CUDA, NVLink를 통합했다.
비관론 3: hyperscaler in-house silicon
NVIDIA의 inference 진입만으로도 충분히 비관적이지만, 경쟁 구도는 한 층 더 복잡하다. 데이터센터 AI chip 시장은 현재 네 방향에서 동시에 압박이 들어온다.

- NVIDIA가 inference SKU(Rubin CPX, LPX)로 specialist 시장에 진입했다.
- Broadcom과 Marvell이 hyperscaler ASIC 시장을 사실상 독점하고 있다.
- Google TPU
- Meta MTIA
- OpenAI custom silicon(루머)
- ByteDance
- Apple이 모두 반도체 설계에 나서고 있다.
- Marvell은 Amazon Trainium2를 만들고 Celestial AI를 $5.5B에 인수해 photonic interconnect까지 흡수했다.
- Hyperscaler가 in-house chip을 원하는 순간 그 contract은 NPU 스타트업의 반도체를 사는 것이 아니라, 브로드컴, 마벨, 알칩, GUC 가서, "이런 칩 만들어주세요" 주문한다.
- Qualcomm이 모바일에서 쌓은 power efficiency 노하우로 데이터센터 inference 시장에 진입한다. AI200, AI250 라인이 2025-2026년 상용화를 목표로 한다.
- AMD가 MI400 시리즈로 NVIDIA의 inference 시장 일부를 잠식하고 있으며 Untether AI를 talent absorption했다. Intel은 Gaudi3 이후 노선 정리 중이지만 여전히 후보군에 있다.
이 11중 포위 사이에서 specialist startup이 차지할 자리는 매우 좁다.
- Cerebras는 sovereign으로 갔고
- Groq은 NVIDIA로 흡수됐으며
- Untether는 AMD로
- Celestial AI는 Marvell로
- Graphcore는 SoftBank로 갔다.
독립적으로 살아남으려는 회사들 — Etched, d-Matrix, Tenstorrent, Lightmatter, SambaNova, MatX, 그리고 한국과 중국 NPU 회사들 — 이 매출 부재의 시간을 얼마나 더 자본으로 버틸 수 있느냐가 진짜 게임이다.
AI 반도체는 칩 한두번 양산에 조 단위의 게임이 된다. 즉, 빅테크 투자, 정치 로비, 여론 형성을 해야 살아남을 수 있다.
미래 분석: 이 AI 스타트업은 어디로 가는가?
이제 회사들을 같은 카테고리로 묶지 말고, 자본 구조와 customer 구조에 따라 그룹화해서 outcome을 분석한다.
그룹 1: M&A
- Groq(NVIDIA, $20B), Celestial AI(Marvell, $5.5B), Untether(AMD, asset purchase), Graphcore(SoftBank).
- Independent product company의 길은 자본 소진 전에 포기되고, incumbent의 IP/talent 보강 자산으로 흡수된다.
- Founder와 early investor는 exit하고, 기술은 incumbent의 product line에 통합된다.
그룹 2: Sovereign AI
- Cerebras(UAE G42/MBZUAI), 한국 NPU, 중동/사우디 일부.
- 이 그룹은 sovereign customer 몇 곳에 매출이 집중되는 구조이며, 그 customer가 정치적 결정에 따라 회사의 운명이 결정된다.
- 회사 가치는 매출 multiple로 평가받기 어렵고 IPO는 narrative 기반으로 진행되며, 상장 후 valuation은 sovereign 관계의 안정성에 따라 변동한다.
- 글로벌 챔피언은 아니지만 일정 규모의 비즈니스는 가능하다.
그룹 3: State-backed national champion
- 중국 회사, 한국 NPU 회사
- 이 그룹은 정부, 정치와 깊이 연결되어있으며, 직접 자본을 투입하고, 강제 분리된 국내 시장에서 customer를 확보하며, 정치적으로 망할 수 없도록 설계된다. (이 회사가 망하면, 그 정치인의 실패가 되니까)
- 중국의 Cambricon이 2025년 14배 매출 성장과 첫 분기 흑자를 기록한 것은 product market fit이 아니라 정치적 demand redistribution의 결과다. 이 회사는 미중 갈등이 강화되면 valuation이 높아진다.
그룹 4: Independent product company를 유지하려는 회사들
- Etched, d-Matrix, Tenstorrent, Lightmatter, SambaNova, MatX, Cerebras(부분적).
- 이 그룹이 가장 어렵다. Hyperscaler 채택을 못 받으면 매출이 안 나오고, hyperscaler 채택을 받으면 결국 incumbent acquisition target이 된다.
- Independent 상태를 유지하려는 의지 자체가 capital intensity를 키운다.
그룹 5: IP 라이선스로 pivot한 회사
- Tenstorrent
- 칩을 직접 안 팔고 RISC-V CPU(Ascalon)와 Tensix AI 코어를 IP로 라이선스해 LG, 현대, 삼성, Bosch와 약 $150M 규모 contract을 확보했다.
- 이 모델의 장점은 명료하다. Customer acquisition battle 안 해도 되고, foundry allocation 경쟁 안 해도 되며, 라이선스 + 로열티 모델은 SaaS급 마진을 가질 수 있다.
- Customer는 자기 PDK에 IP를 implement해서 자기 SoC에 박는다. Process portable IP는 multi-process node에 라이선스될 수 있어 매출 지속성이 길다.
- 이 길이 본질적으로 가장 안전하다. 그러나 다른 회사들이 이 길을 못 가는 이유가 명확하다.
- 첫째, monolithic SoC architecture는 IP로 떼어내려면 사실상 재설계가 필요하다.
- 둘째, IP 라이선스 회사의 매출 multiple은 product chip 회사보다 훨씬 작아서 valuation reset이 일어난다.
- ARM이라는 회사는 반도체 업계인 누구나 알지만, ARM은 30년 동안 돈을 거의 못 벌고 있다.
- 셋째, founder와 early investor의 exit 동학과 안 맞는다. License contract 한 건 협상에 12-24개월이 걸리고 royalty 매출이 누적되는 데 다시 수년이 든다. VC fund의 IRR 시계로는 너무 길다.
- Tenstorrent가 이 길을 갈 수 있었던 이유는 Jim Keller라는 founder의 capital raising power와 architectural choice의 선견지명 덕분이다.
그룹 6: Edge AI, On device AI, AIoT 반도체
- Hailo, SiMa.ai, Axelera, Ambarella, Mobilint, DeepX 일부. 이 그룹은 데이터센터 시장이 아니라 robotics, automotive, security camera, industrial 같은 edge 시장을 노린다.
- TAM은 작지만 fragmented하며 customer base가 다양해서 customer concentration risk가 낮다.
- 마진은 데이터센터 chip 대비 낮지만 supply chain risk도 낮다.
- 이 그룹은 NVIDIA의 직접 경쟁권에서 벗어나 있다는 장점이 있다.
- NVIDIA가 Jetson 라인으로 edge에 들어와 있지만 자동차 OEM, 로봇 회사, 산업 자동화 업체들은 power envelope과 customization 요구 때문에 specialist를 선호한다.
- 다만 매출 성장이 느리고 unit economics가 어렵다. Hailo는 IPO를 노렸지만 시장 상황에 따라 지연 중이다.
결론
AI 반도체 스타트업의 운명은 반도체 엔지니어들의 실력만으로 결정되지 않는다.

그 위에 쌓이는 자본 구조, 어떻게 HBM을 받아내고, 어떻게 Foundry slot을 얻고, 어떻게 수주를 받아내고, 정치 구조, customer 구조, software 생태계 복잡하게 얽혀있다.
사실, 내부자들은 다 알고있다.
- VC 투자를 받는 순간 회사는 수십배의 high-multiple exit을 약속한 것이다.
- 그 multiple을을 지키려면 product company로 성장해야 하고, product company로 성장하려면 SoC를 만들어야 하며, SoC를 만들면 IP 라이선스로 pivot할 수 없게 된다.
- 정부 투자를 받았다면, 국가의 증권거래소에 상장을 약속한 것이다.
- 이 자본은 IPO를 요구한다. 그래서 이 회사들도 SoC를 만들고, hyperscaler 채택을 추구하고, sovereign customer에 의존하고, narrative에 valuation을 의탁한다.
Cerebras가 매출의 86%를 두 sovereign 고객에 의존하는 것도, Wafer-scale engine의 economics를 정당화할 수 있는 customer는 sovereign 또는 hyperscaler뿐인데, hyperscaler는 in-house로 가버렸으니 sovereign이 남았을 뿐이다. 자본 구조가 한번 정해지면 customer 구조도 따라간다.
그러나 Founder들이 이런것들을 공개적으로 말하지 않는다. 자본을 모으는 단계에서는 "우리 반도체가 NVIDIA보다 이 부분에 대해서는 더 좋습니다." narrative로 내세워야 valuation이 정당화되기 때문이다.
이 frame 불일치가 산업의 모순을 만든다. 매년 수십억 달러가 specialist startup에 들어가지만 글로벌 챔피언은 거의 등장하지 않는다.
등장하지 않는 것이 실패가 아니다. 자본은 회수되고, 창업자는 exit에 다가서고, 기술은 incumbent를 통해 commercialize되며, talent는 재배치된다.