AI는 이미 전세계 모든 교과서를 다 집어삼켰다. Claude는 모든 전공의 교과서를 다 메모리에 넣은 만물박사에 가깝다. 오픈소스 코드도 다 봤다. AI가 신입보다 잘하는 영역이 점점 늘고 있다.
그런데 시장은 왜 SaaS (SAP, Adobe) 주가는 후려치고 NVIDIA·TSMC·Synopsys 주가는 안 후려치는가? NVIDIA 같은 설계 회사도 GDS라는 Code를 만드는 회사이고, Synopsys도 반도체 설계용 소프트웨어인데...?
학습 데이터에 없는 자산을 가진 회사는 AI 시대에 프리미엄을 받는다.

AI는 이미 오픈소스 RTL도 다 봤다. 오픈소스 EDA Tool, 유출된 반도체 기밀 문서, 유저가이드도 다 봤다. UVM testbench도 짠다. AI가 신입 엔지니어보다 잘하는 영역이 점점 늘고 있다. 그런데 왜 AI는 NVIDIA·TSMC·Synopsys를 대체 못하는가!
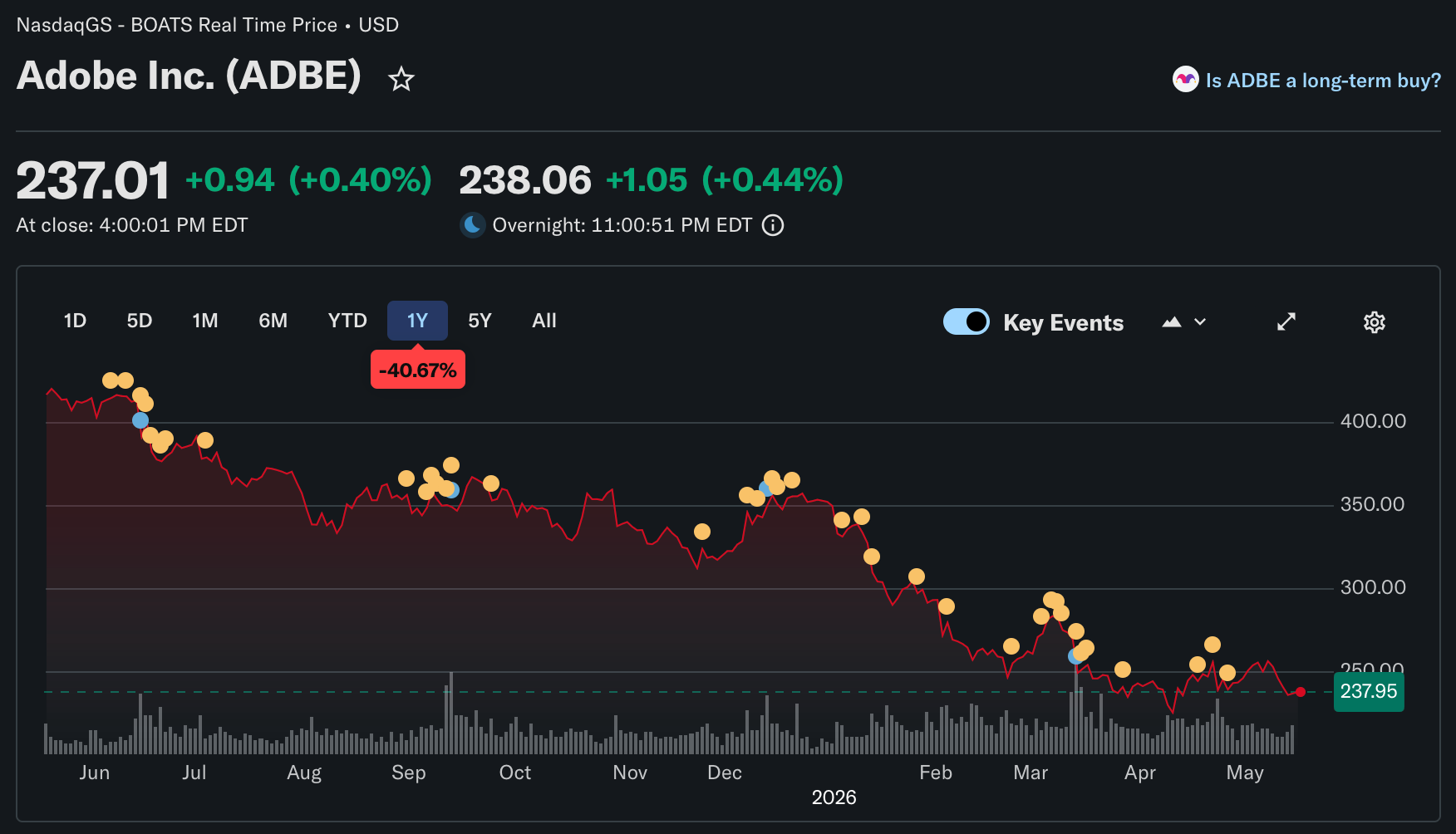
2026년 3월 기준 SaaS median EV/Revenue 배수는 3.4x. 2021년 대비 1/5 수준이다. 48시간 만에 $300B이 증발한 2월 SaaS apocalypse는 시장이 "AI가 seat을 대체하면 SaaS 매출 모델 자체가 역회전된다"고 판단했다는 뜻이다.

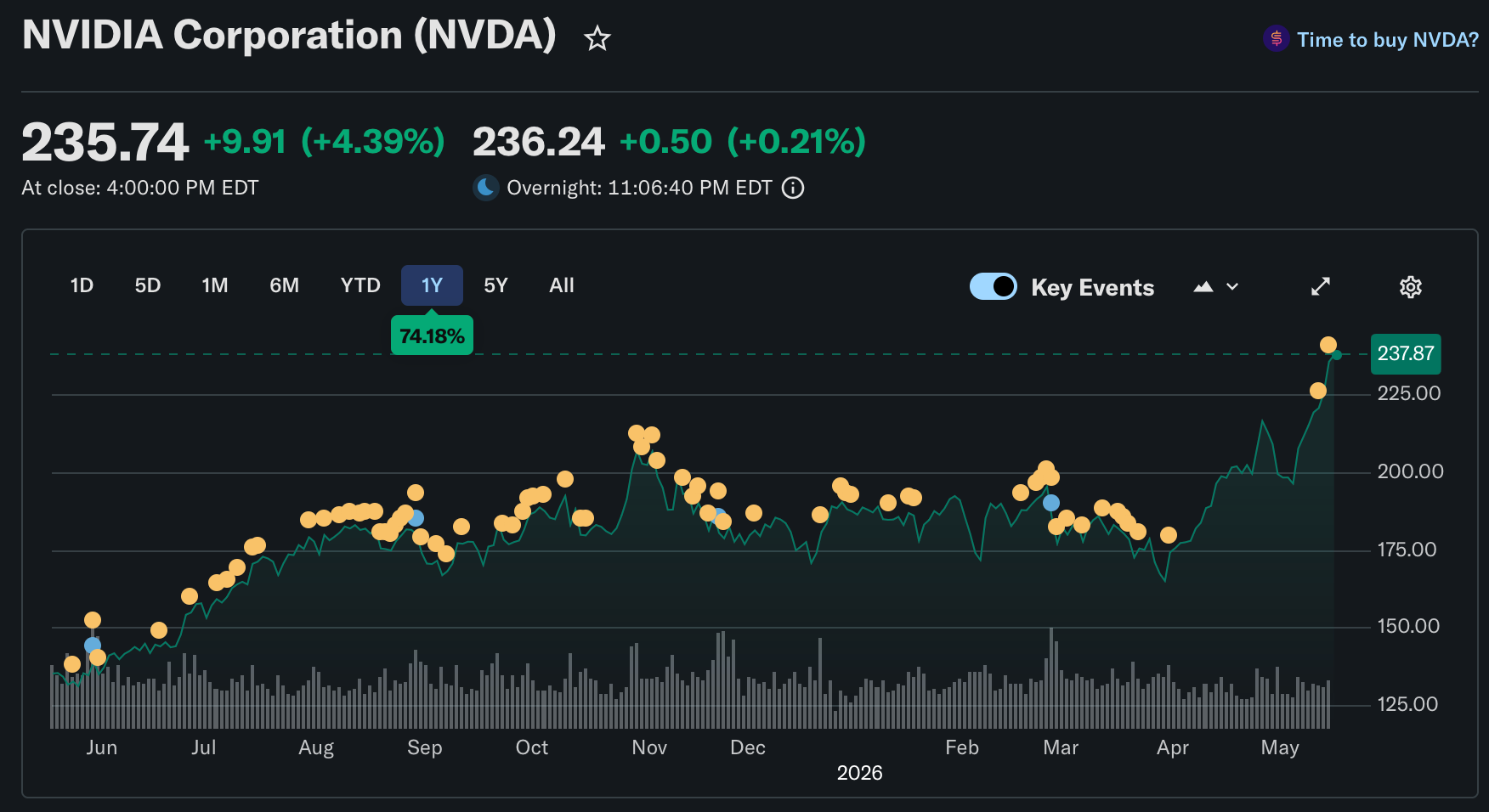
반면 EDA/반도체 장비 섹터의 멀티플은 사상 최고치 근처다. Synopsys FY25 P/E 55x, Cadence 60x. NVIDIA는 말할 것도 없다. 시장이 멍청한 게 아니다. 이유가 있다.
AI가 못 이기는 4가지 자산
공통점이 하나 있다. 전부 비공개다. LLM 학습 데이터에 없다. 그리고 만드는 데 돈과 시간이 물리적으로 든다.
1. Foundry-tied 자산: PDK, SPICE model, yield 데이터
TSMC N2/A16, Samsung SF2, Intel 18A. 이 노드들의 PDK, DRC/LVS rule deck, SPICE device model, yield/defect correlation 데이터는 전부 NDA다. 어떤 학술 논문에도, 어떤 GitHub에도 없다.
이 데이터가 유출 되면, 그 사람은 평생 감옥에서 못 나오게 될 것이다.
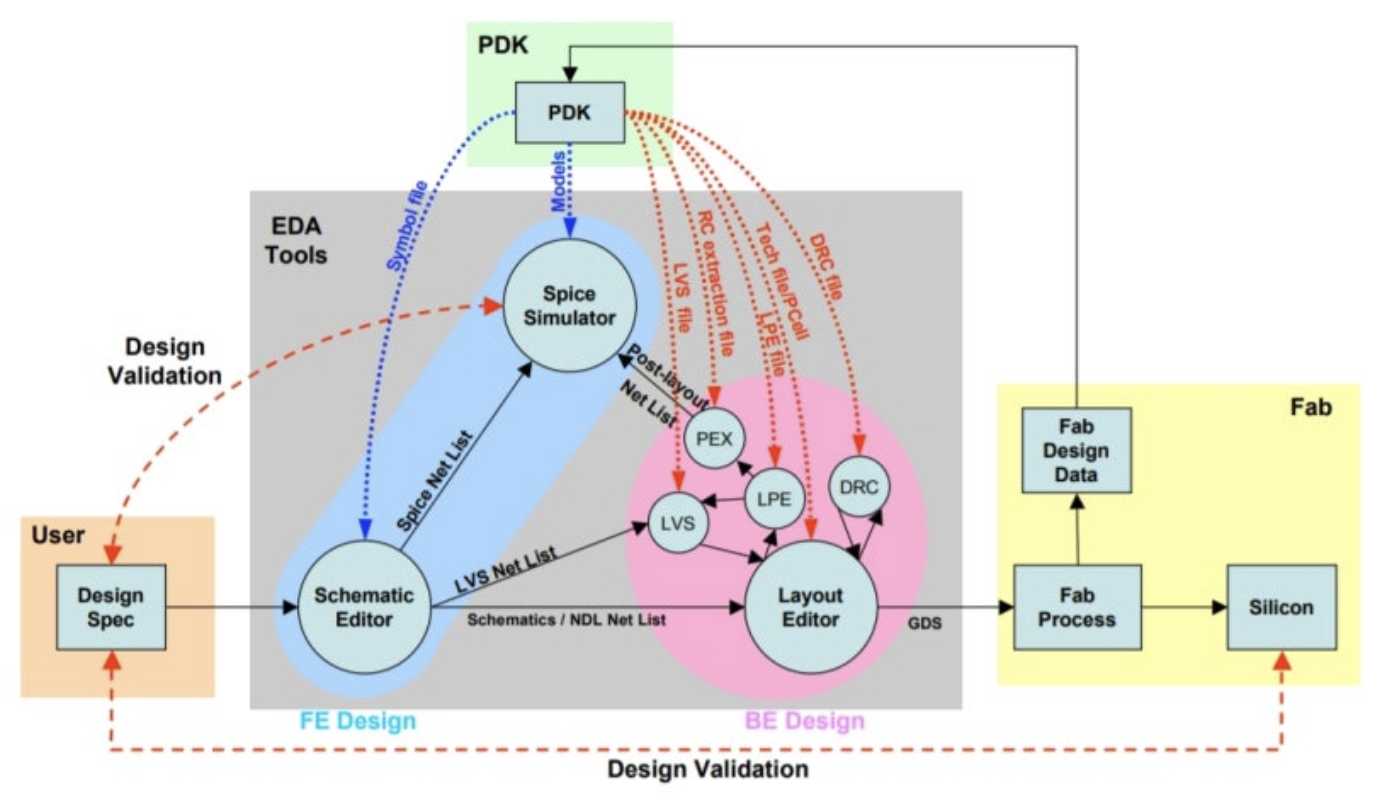
N2 GAA SPICE model의 정확도는 수십조원 규모의 wafer 누적 측정치에서 나온다.
단순히 코드만 작성한게 아니라, 간단한 Test vehicle 설계부터 실제 Silicon 간의 간극 분석, Process corner별 device 특성, voltage/temperature에 따른 aging model, local variation 통계들을 모두 실험을 통해 뽑아낸 값들이다. 이런 값들은 회사들이 외부에 절대 공개하지 않는다.
AI가 Fabless, Foundry, EDA를 대체하려면 이러한 데이터를 얻어야한다.
- 이 실험은 각 회사들이 절대 내놓지 않는다. 이걸 준다는 뜻은 은행이 금고를 열어주는 것과 똑같다.
- 현재 회사들이 하고 있는 방식은, "AI 회사들은 자체 반도체를 설계"하고, "반도체 회사들은 자체 AI 개발" 하는 방식으로 섞이고 있다.
중요한건 실험 데이터를 쥐고 있어야한다는 것.
반도체 실험 데이터가 회사의 가장 큰 자산이다. 반도체 회사들은 절대 그들의 데이터를 외부 공유하지 않는다. 대신에 이들은 자체 AI를 구축한다.
신규 진입자들이 반도체 선단설계 영역으로 들어올 수 없게 만들고 있다.
2. 반도체 IP 회사
반도체 IP 회사들은 보통 Soft IP나 Hard IP라고 불리는 설계를 판매한다. 예를들어 Synopsys는 표준화된 USB IP를 전세계 팹리스에 판매한다. 삼성이든, 애플이든, 세계 표준을 맞추기 위해서 IP 회사의 반도체를 사용한다.
반도체 IP는 자체 PPA 뿐만 아니라, 표준화가 중요하다.
그리고... 이것들의 공통점: 교과서로 못 만든다.
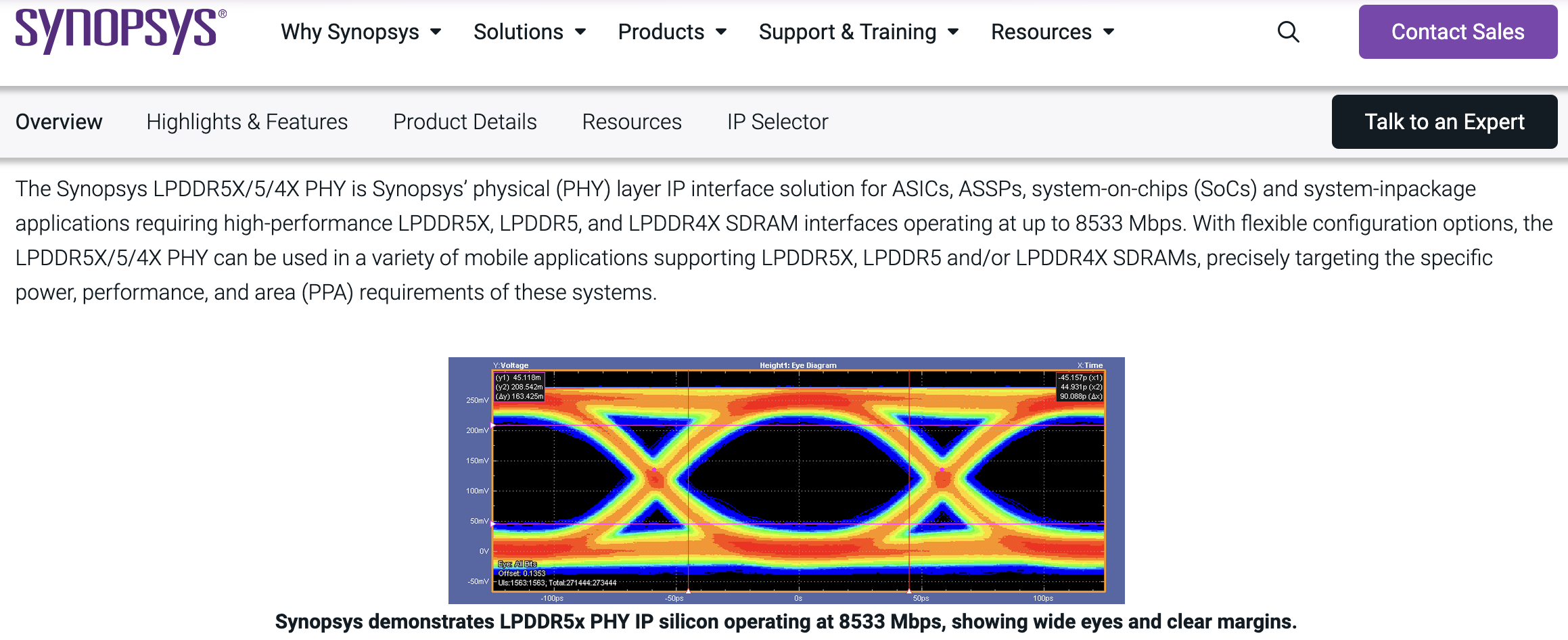
- Alphawave의 224G SerDes
- Synopsys DesignWare HBM4 PHY
- Cadence 224G-LR PHY
- ADI의 RF front-end
- TI의 power management.
224G SerDes의 jitter budget은 sub-100fs RMS 수준이다. 이걸 달성하려면 CTLE/DFE tap 계수, TX FIR 최적화, PLL loop bandwidth, power supply rejection — 전부 silicon iteration으로 tuning한다. 시뮬레이션에서 pass해도 silicon에서 fail하는 경우가 태반이다. Process corner, temperature, crosstalk, package parasitic이 전부 얽혀 있어서다.
이것들을 AI가 하려면 1과 같은 문제가 발생한다. AI 회사들이 이러한 실험 데이터를 갖고있지 않다는 것이다.
Synopsys가 TSMC N2P에서 silicon proven을 달성했다는 건, 그 IP가 실제 wafer 위에서 동작한다는 뜻이다. LLM이 RTL을 짜서 넘겨도, silicon success는 다른 문제다. Analog/mixed-signal은 "코드가 맞으면 동작한다"는 논리가 안 통한다.
3. System co-design + supply chain lock
NVIDIA, Apple, AMD, Broadcom. 이 회사들의 해자는 chip 자체가 아니다.
NVIDIA의 경우:
- CUDA ecosystem (500만+ 개발자), NVLink/NVSwitch interconnect, CoWoS packaging allocation (TSMC capacity의 50%+)
- HBM 공급계약 (SK hynix/Samsung/Micron 3사 전부)
- DGX/HGX system integration, 그리고 이 모든 걸 묶는 소프트웨어 스택.
AI가 Blackwell 급 chip RTL을 짜더라도...
- 제조해줄 Foundry slot allocation 없이
- HBM 공급망 없이
- NVLink 없이
- CUDA 없이
그건 그냥 netlist일 뿐이다. 실체가 없다.

A-series/M-series chip은 iOS/macOS ecosystem, TSMC N3 독점 물량, 자체 GPU/NPU architecture, 자체 interconnect가 한 몸이다. Chip만 따로 떼서 보면 해자가 안 보인다. 시스템으로 보면 깨지지 않는다.
4. EDA signoff tool
Synopsys PrimeTime, Siemens Calibre. 이 도구들이 반도체 설계의 final gatekeeper다.
내가 매일 하는 일이 이거다. PrimeTime으로 STA signoff를 한다.
Timing report에서 slack을 읽고, constraint를 고치고, ECO를 한다. 이 과정에서 중요한 건 PrimeTime의 "정확도"가 아니다. TSMC가 PrimeTime을 N2 signoff tool로, Samsung Foundry가 SF2에서 공정 인증(certify)했다는 사실이 중요하다.
LLM이 STA 엔진을 만들 수 있을까?
가능하다. 근데 Silicon Correlation을 어떻게 할 것인가? 또 1번에서 봤던 실험 데이터 문제가 발생한다.
그리고 EDA Tool code를 보다보면... f(tran, cap, K) 이런 함수들이 보이는데, 대체 이 K값은 어떻게 결정된 것인지 알 수가 없다.
나: 이거 왜 이 식에 K 값은 어떻게 결정된거에요? (당연히 내가 모르는 반도체 수식이 있을거라고 생각함)
선배: 그거 130nm 디자인에서 이 디자인들을 넣어서 해보면, 기가막히게 그 값이 Silicon이랑 오차율이 N% 미만으로 나옴.
이 대화를 쪼개서 보면,
- 수십년 전부터 전세계 고객들의 STA와 Silicon correlation이 낮다는 Complain 메일 기록이 존재.
- 그 메일에는 고객의 디자인, Silicon 결과 값들이 포함
- 이런 메일들이 엄청나게 많다. (본인만 하더라도, 메일이 하루에 수십개에서 수백개 오니까)
- 모든 설계들이 모든 실리콘 데이터와 잘 맞는 결과를 만들도록 STA EDA Tool 코드 변경이 누적 되었다.
이런 데이터를 얻으려면 파운드리, 팹리스들과 공동 개발을 해야 하는데, 그 파운드리, 팹리스들은 이미 Synopsys/Cadence/Siemens와 하고 있다. 그리고 그 회사들도 각자의 AI가 있다.

2026년 4월 Synopsys가 발표한 TSMC 파트너십 확대도 같은 맥락이다. N3C, N3P, N2P, A16까지 certified EDA flow와 silicon-proven IP를 동시에 커버한다. 이 생태계에 끼려면 수십 년이 필요하다.
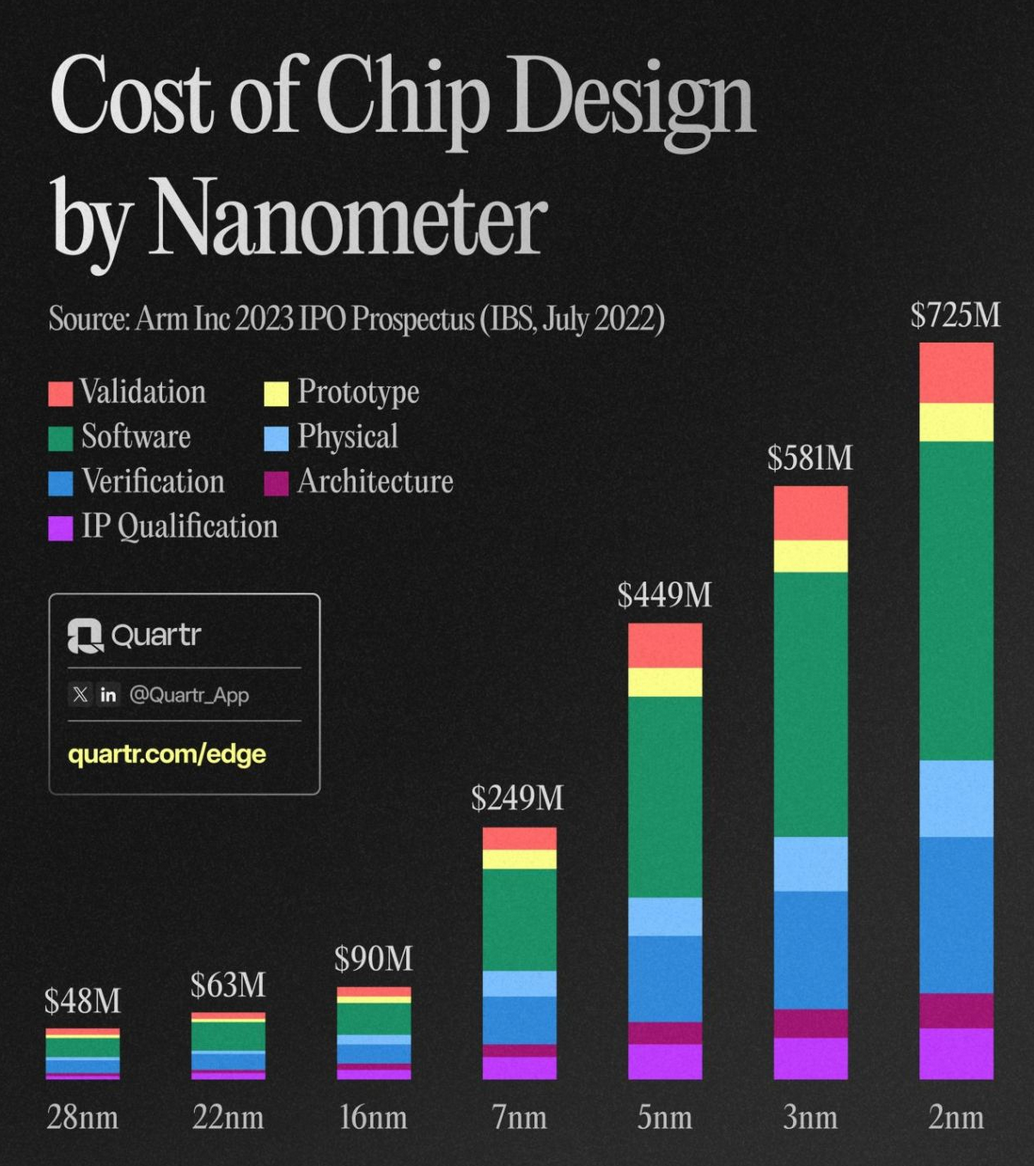
선단공정의 반도체 칩 Tape-out 한번에 $725M 수준이 쓰인다. 경영진들은 AI Tool을 절대 Signoff 툴로 사용하지 않는다. Silicon Failure 한번 발생하면 작은 회사들은 망할 수 있고, 큰 회사들은 큰 슬럼프를 겪게 된다.
대신에 "AI 기반 설계 (Logic design, Physical Design)"를 하고, Silicon Proven 되어있는 상용 EDA Tool에서 Signoff를 하자. 이런 방식으로 섞이고 있다.
SaaS와의 대비: 왜 디스카운트가 갈리는가
SaaS의 본질은 UI + DB + workflow다. 이 세 개 모두 공개 학습 데이터 위에서 재생산 가능하다.
GPT-5급 모델에게 "Salesforce CRM 기능을 SaaS로 만들어줘"라고 하면, MVP는 나온다. 물론 enterprise 수준의 완성도와는 거리가 있지만, 시장은 그 방향성만으로 가격을 조정했다.
반도체의 핵심 자산 4가지는 전부 비공개이거나 물리적이다.
- PDK는 NDA. Silicon IP는 fab에서 나온다.
- Supply chain은 계약이다.
- EDA certification은 수십 년 파트너십이다.
- AI가 실험 데이터에 단독으로 진입할 경로가 물리적으로 없다.
시장은 이걸 안다. 학습 데이터에 없는 자산을 가진 회사는 AI 시대에 프리미엄을 받는다.
안에서 보면 다르게 보인다 — 진짜 위협받는 영역
바깥에서 보면 "반도체는 AI로부터 안전"이라는 내러티브가 편하다. 하지만 안에서 일하는 사람으로서 말하면, 명확히 깎이고 있는 영역이 있다.
깎이는 영역
- Commodity ASIC implementation — lower-end design house의 RTL-to-GDS turnkey 작업. 표준 IP 붙이고, clock tree 넣고, timing closure 하는 루틴 작업. AI가 꽤 자동화할 수 있다.
- 앞으로는 시니어 엔지니어 한명이 훨씬 더 큰 인스턴스 카운트의 디자인을 맡게 될 것이다.
- 표준 IP integration, glue logic — AXI interconnect 붙이기, interrupt controller, register file 생성. 이미 상당 부분 template 기반이었고, AI가 더 빠르게 한다.
- UVM testbench 1차 작성 — Agent/driver/monitor scaffolding, 기본 sequence 작성, coverage point 초안. LLM이 잘한다. Lint/CDC 1차 cleanup도 마찬가지.
- Datasheet/PR/기술 문서 초안 — 이건 이미 대체되고 있다.
안전한 영역
- EDA engine 개발, foundry signoff correlation — 위에서 설명한 이유. Certification 데이터 없이는 의미 없다.
- EDA 회사에서 일하는 엔지니어가 안전하다는 뜻이 절대 아니다. EDA 회사가 안전하다는 뜻이다.
- Analog/RF/PHY silicon bring-up — 오실로스코프 앞에서 jitter 잡고, impedance matching 조정하는 일. 물리 세계와의 interaction이라 코드만으론 안 된다.
- Application engineering의 customer-specific debug — 고객 환경에서만 재현되는 문제. 고객 NDA 데이터 + 엔지니어 경험의 교집합. AI에게 넘길 수 없는 context.
- Architecture / system-level co-design — chip-package-system을 동시에 최적화하는 일. Trade-off 공간이 너무 넓고, constraint가 비공개(고객 요구, 공정 한계, 공급 조건)다.
- 너무 큰 경험 데이터가 필요한 것들은 아직 AI가 잘 하지 못한다.
정리하면: commodity work은 깎인다. Silicon-correlated work은 안 깎인다. 경계선은 "그 일을 하려면 비공개 데이터가 필요한가?"로 긋는다.
커리어의 경우, Implementer보다 architect 또는 owner. Routine 업무보다 모험적인 업무로 벡터를 옮겨야 한다.
창업자에게 AI는 두가지 양날의 검을 갖고 있다. 확실히 과거보다 구현 비용이 줄어들었다. 좋은 아이디어와 백그라운드만 있으면 된다.