예전에는 “공정 몇 나노냐, 코어 몇 개냐”가 반도체 성능의 대부분을 설명하는 것처럼 느껴졌다.
요즘은 Chiplet, 2.5D, 3D IC, UCIe 같은 단어들이 먼저 눈에 들어온다.
이게 단순한 유행어라서 그런 건 아니다.
이제는 다이 내부가 아니라, 다이와 다이 사이를 이어주는 인터커넥트가 칩 전체의 성능과 전력, 비용을 좌우하는 수준까지 올라왔기 때문이다.
모 스타트업이 엔비디아를 이겼다 어쩐다 하지만... 엔비디아 칩의 성능+전력+범용성+양산 수율 등 넓은 부분에서 시장성을 이기는 반도체는 없다.
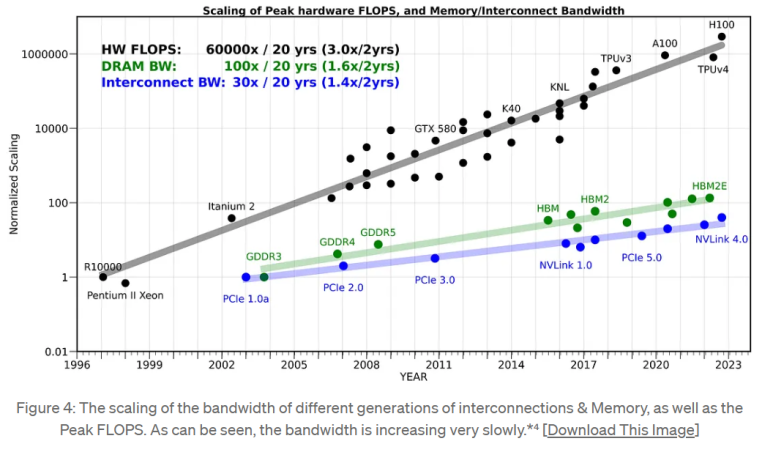
아래 자료는 riselab의 Amir가 정리한 그래프이다.
X축은 연도, Y축은 성능이라고 보면 된다.
검정색은 시스템 반도체의 성능 개선 기울기 > 메모리 반도체의 성능 개선 기울기 > 인터커넥트의 성능 개선 기울기
보드 레벨에서는 결국 이 3개 모두 사용하게 되는데,
GPU의 성능이 아무리 빨라져도, 다른 반도체들의 대역폭이 작아서, 다른 반도체들에서 병목 현상이 일어나게 된다.
그래서 기업들은 현재 메모리에서 가장 큰 대역폭을 가진 HBM을 최대한 많이 갖고 가는게 인공지능 반도체 회사들의 큰 숙제가 되었고,
HBM 덕분에 SK하이닉스(전세계 최고 기술력), 삼성전자(전세계 최고 생산력), 마이크론(미국 최고 메모리 회사)의 주가가 최근 엄청나게 올라가고 있다.
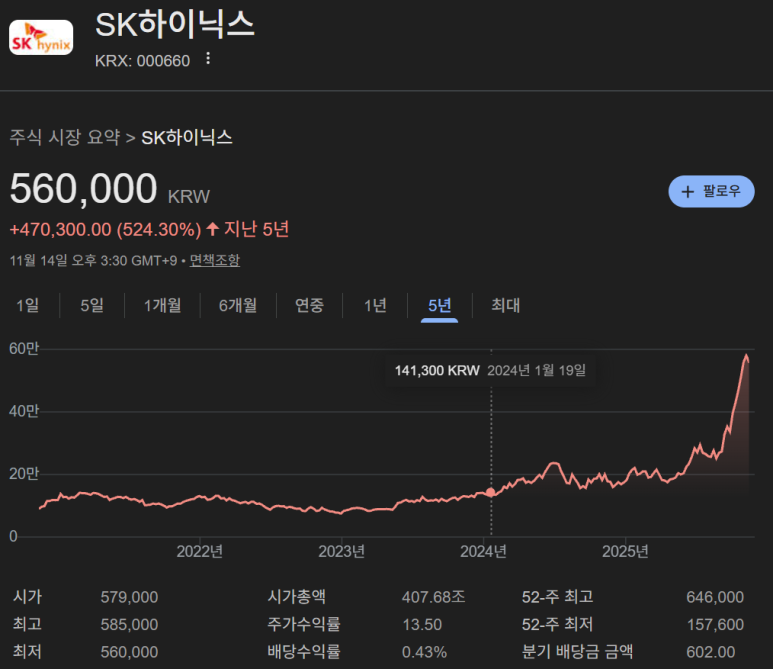
근데... 메모리보다 더 느린건 인터커넥트이다.
나도 예전에는 “Chiplet = 큰 칩 쪼개서 붙이는 거지 뭐” 정도로만 생각했는데, 들여다보면 볼수록, 다음 반도체 게임의 승패를 가르는 건 인터커넥트라는 생각이 든다.
공정은 더 좋아졌는데, 왜 굳이 칩을 쪼갤까
Chiplet 이야기를 하려면 먼저 “왜 모놀리식 SoC를 포기했는가”부터 짚고 가야 한다.
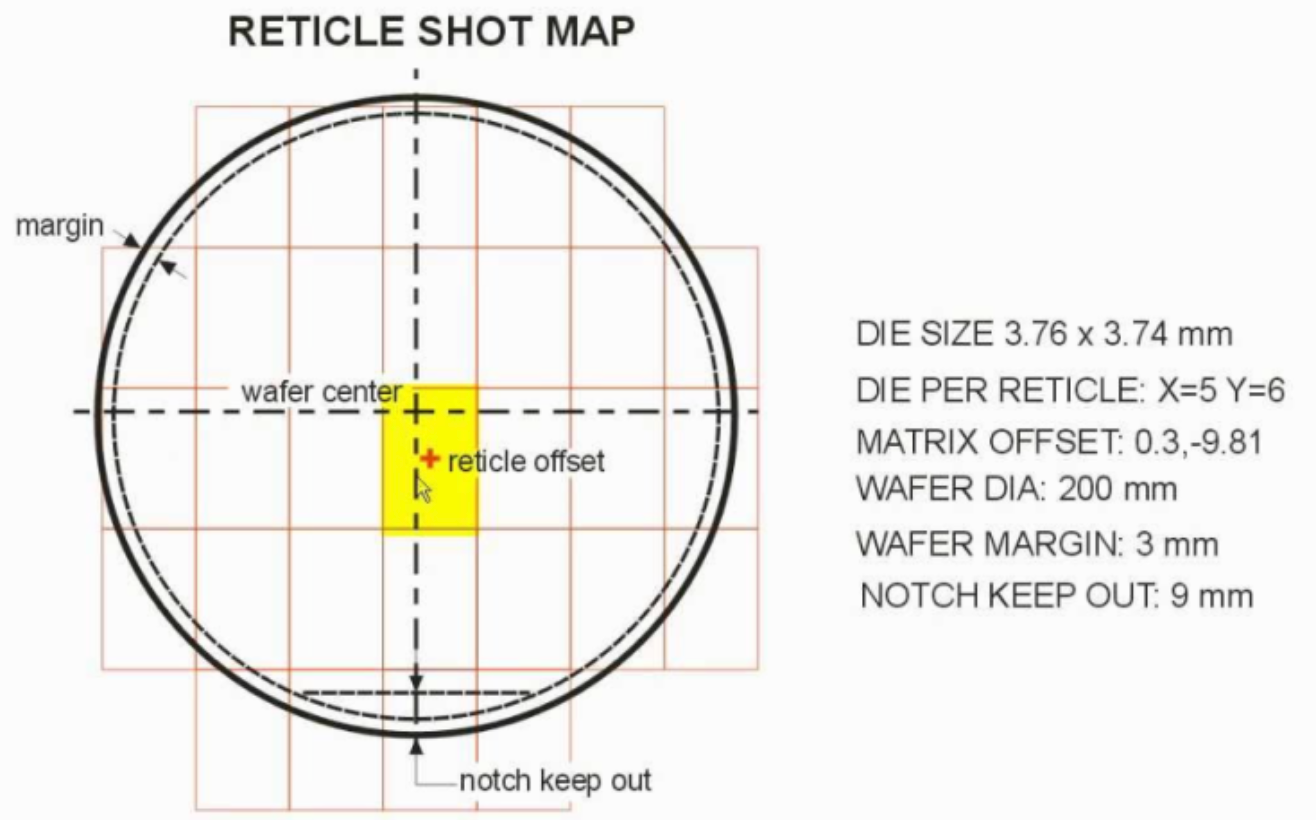
첫째, Reticle Size 한계.
노광 장비(ASML)로 회로도 마스크를 그리는데,
이 장비가 회로를 그릴 수 있는 최대 면적이 있다. 고성능 CPU, GPU, AI Accelerator를 하나의 거대한 다이로 설계하면 이 한계 근처까지 가게 된다. 이 지점을 넘어가면 설계 자체가 복잡해지고, 수율까지 급격히 떨어진다.
둘째, 수율과 비용 구조.
면적이 커질수록 “불량 하나”가 가져오는 손실이 커진다. 800 mm²짜리 다이에 먼지 하나가 끼면, 결국 이 칩 전체가 불량이라 그대로 버려야 하는데, 200 mm²짜리 네 개로 나눴다면 1개가 불량이라도 나머지 세 개는 다른 조합에 쓸 수 있다. 통계적으로 보면 Chiplet 구조가 훨씬 유리해진다. 공정이 미세해질수록 다이 하나의 가격이 올라가니, 이 차이는 더 크게 느껴진다.
https://semiengineering.com/designs-beyond-the-reticle-limit/
셋째, Heterogeneous Integration.
요즘 SoC 하나 안에는 CPU, NPU, GPU, High-Speed SerDes, DDR/LPDDR/PHY, 아날로그, RF, 전원 관리 같은 것들이 다 붙어 있다. 모든 블록을 가장 최신 FinFET/GAA 공정으로 구현하는 것이 항상 최선은 아니다. 디지털 로직은 선단 공정이 유리하지만, 아날로그나 I/O는 오히려 성숙 공정이 더 안정적이고 싸다.
결국 “각 블록을 최적의 공정에서 만든 뒤, 패키지에서 결합하자”는 방향으로 갈 수밖에 없다. 이때 핵심 키워드가 2.5D, 3D IC, 그리고 Chiplet이다.
정리하면, Chiplet은 “공정 한계를 우회하고, 수율과 비용을 잡고, 서로 다른 공정을 한 패키지에서 섞어 쓰기 위한 구조”다. 문제는, 이렇게 쪼개 놓고 나면 그 사이를 어떻게 연결하느냐가 훨씬 더 어려워진다는 점이다.
그런데... 수율과 비용 구조 때문에 Chiplet이 무조건 좋아보이기도 하지만,
2.5D IC, 3D IC의 제조공정 자체가 복잡하기에, 이 과정에 수율이 떨어질 수도 있고, 이걸 보완하기 위해 꽤 많은 돈이 들다보니, 배보다 배꼽이 커지는 상황이 올 수도 있다.
그래서 이게 아직은 양산이 많지 않다.
On-Die Wire에서 Die-to-Die Link로
모놀리식 SoC에서는 대부분의 데이터가 On-Die Metal Layer 위에서 흐른다. Global Wire라고 해도 결국 실리콘 위의 배선이고, 수백 ps~수 ns 수준의 지연, 비교적 낮은 에너지로 신호를 주고받는다.
NoC(Network-on-Chip) 설계가 중요하긴 해도, Physical Routing 자체는 “칩 안에서 어떻게든 해결할 수 있는” 문제에 가까웠다.
Chiplet 구조로 가는 순간, 중요한 데이터가 Die 밖으로 나가서 다시 들어오는 구조가 된다. 즉, 경로가 다음처럼 바뀐다.
Core → On-Die NoC → Die Edge → Micro Bump → Interposer 또는 RDL → 다른 Die의 Micro Bump → On-Die NoC → Core
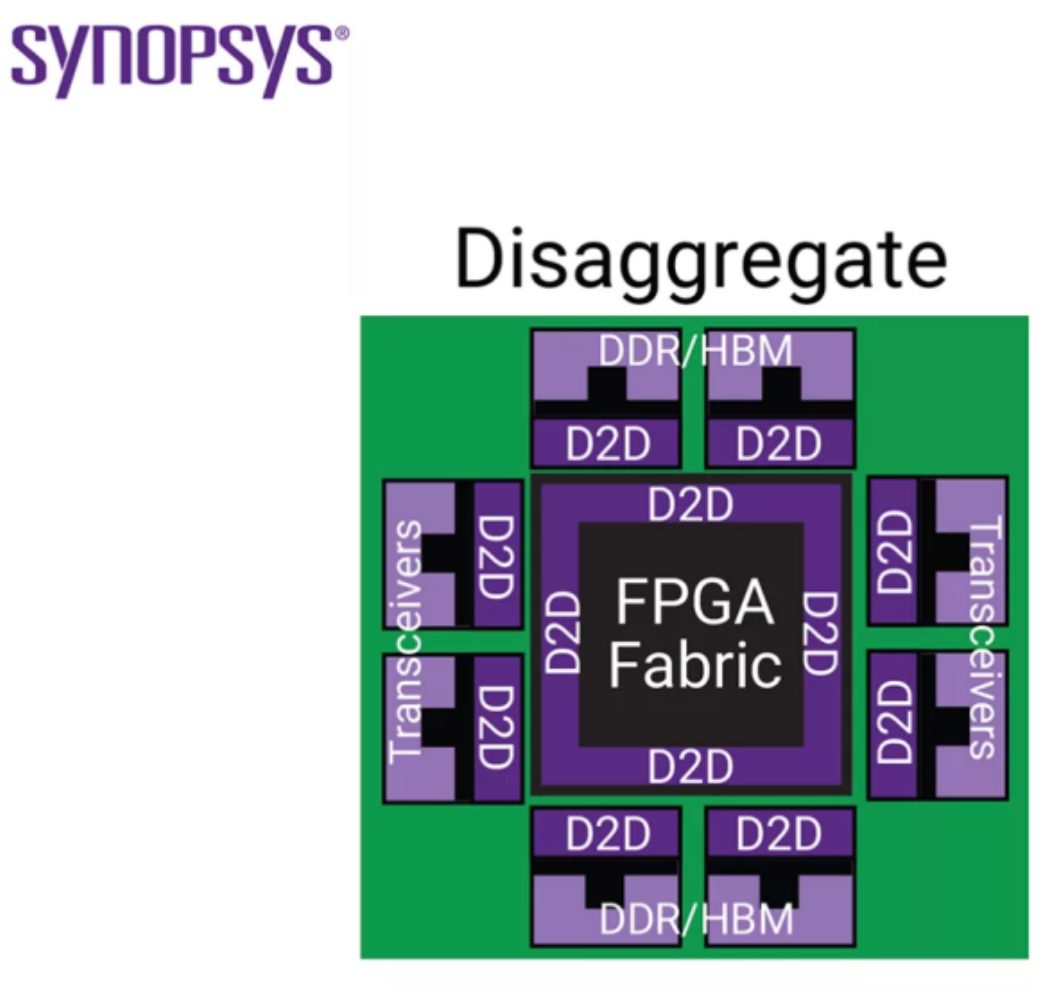
물리적인 관점에서 보면 몇 가지 변화가 생긴다.
배선의 매질이 바뀐다
이제는 실리콘 위 Metal Layer만 다루는 게 아니라, Micro Bump, TSV, Silicon Interposer, Fan-Out RDL, 유기 기판 등 다양한 매질을 통과한다.
각 구간마다 저항, 기생, 손실, 반사 특성이 다르고, 채널 전체를 하나의 시스템으로 모델링해야 한다.
길이와 환경이 달라진다
On-Die Wire보다는 훨씬 길고, 임피던스도 복잡해진다. Signal Integrity 문제가 본격적으로 등장한다. 기존의 Package SerDes와 On-Die Wire 사이에 있던 “벽”이 무너지고, 상당히 고급 SerDes 설계 수준의 고민이 패키지 안으로 들어온다.
에너지와 면적의 가격이 달라진다
On-Die Wire 하나를 더 깔 때의 비용과, Die-to-Die Link를 하나 더 늘릴 때의 비용은 차원이 다르다. Die Edge의 길이는 한정되어 있고, Bump Pitch도 제한적이다. Link 수를 늘리면 Die 주변부 Area, PHY Cell Area,
Routing, 그리고 전력까지 모두 영향을 받는다.
예전에는 “Wire를 조금 더 쓰면 되지”로 끝났던 설계가, 이제는 “이 Link가 정말 그 대역폭을 받을 가치가 있는가”라는 질문으로 바뀐다.
이 순간부터 Interconnect는 단순한 물리 배선이 아니라, 전체 Chiplet System의 아키텍처를 결정하는 핵심 리소스로 올라온다.
PPA 관점에서 보는 Chiplet Interconnect
결국 모든 설계는 PPA(Power, Performance, Area)와 Cost로 귀결된다. Chiplet Interconnect는 이 네 가지 축에 모두 깊게 관여한다.
성능: 대역폭과 지연
AI Accelerator, GPU, High-Performance CPU, 그리고 HBM 같은 고대역폭 메모리 사이에서는 엄청난 양의 데이터가 오간다. 이 데이터가 이제는 On-Die가 아니라 Die-to-Die Link를 통해 흐르면, 링크의 대역폭 밀도와 왕복 지연이 시스템 성능의 상한을 결정한다.
대역폭이 부족하면 코어를 아무리 늘려도 “Memory Wall”에서 막힌다. 그리고 지연이 너무 크면, Fine-Grain한 협업이 어려워지고 아키텍처 자체를 Coarse-Grain으로 설계해야 한다. 예를 들어, L3 Cache를 Chiplet으로 분리했는데 Latency가 너무 크다면, 사실상 Off-Chip Memory에 가까운 존재가 되어버린다.
전력: pJ/bit 싸움
On-Die Wire는 수십 fJ/bit 수준까지 전력을 압축할 수 있지만, Package-Based SerDes는 수 pJ/bit가 나오는 경우가 많다. Chiplet용 Short-Reach, Ultra-Low-Power PHY도 목표는 pJ/bit 이하지만, 여전히 On-Die에 비하면 비싸다.
결국, System Architect 입장에서는
“이 데이터를 정말 Die를 넘어 보내야 할까, 아니면 이 Die 안에서 한 번 더 계산해서 압축해서 보낼까?”
같은 고민을 하게 된다. Interconnect의 전력 가격표가 바뀌면, Compute vs Communication Trade-Off도 함께 달라진다.
Area: Die Edge와 PHY Area
Chiplet Interconnect는 “Edge-Centric”이다. Die Perimeter를 따라 Bump와 PHY가 배치된다. Die 크기를 키우면 Core Area뿐 아니라 Edge 길이도 늘어나긴 하지만, Edge를 얼마나 효율적으로 Interconnect에 할당하느냐가 PPA에 직접적인 영향을 준다.
특히 UCIe처럼 Standardized Die-to-Die Interface를 쓰면 PHY, Controller, Protocol Stack이 차지하는 Area도 무시할 수 없다. 여기 들어가는 면적과 전력을 줄이는 것이 곧 Chiplet Design의 경쟁력이 된다.
Cost: 공정 조합과 패키지 복잡도
Chiplet 구조를 쓰면 Logic은 선단 공정, I/O는 성숙 공정으로 나누는 식으로 Die 단위 Cost를 줄일 수 있다. 문제는 패키지 비용이다. Silicon Interposer, 고밀도 RDL, Fine-Pitch Bump는 매우 비싸다. Interconnect 요구 사항이 과도하면 패키지 구조가 복잡해지고, 결국 전체 Cost가 올라간다.
그래서 Interconnect는 “이 Chiplet 아키텍처가 경제적으로 의미가 있느냐”를 결정하는 바로미터가 된다.
UCIe, 그리고 Die-to-Die Interface의 표준화
요즘 가장 많이 언급되는 키워드 중 하나가 UCIe(Universal Chiplet Interconnect Express)다. 이름만 보면 PCIe 느낌이 나는데, 실제로도 PCIe/CXL 같은 기존 프로토콜과의 호환성, 그리고 Die-to-Die 환경에 특화된 PHY를 제공하는 것을 목표로 한다.
UCIe가 등장한 이유는 명확하다. 서로 다른 회사의 Chiplet을 조합할 수 있다
각 회사가 자기들끼리만 쓰는 Proprietary Die-to-Die Interface만 고집하면, Chiplet Ecosystem은 절대 커질 수 없다. “누구나 합쳐 쓸 수 있는 표준 인터페이스”가 있어야 진짜로 SoC-Level에서 “조립식” 설계가 가능해진다.
표준화가 되면 좋은 점은 분명하다.
예를 들어, 한 회사는 CPU Chiplet, 다른 회사는 NPU Chiplet, 또 다른 회사는 SerDes/IO Chiplet을 만들고, System Company가 이들을 조합해 하나의 패키지로 만들 수 있다. 물론 현실적으로는 IP, 검증, 책임 소재 문제가 있어서 그렇게 간단하지는 않다. 그래도 “가능한 시나리오”가 되었다는 것 자체가 큰 변화다.
EDA와 Design Flow가 정리된다
매번 새로운 Proprietary PHY, Protocol을 모델링할 필요 없이, UCIe 기반 채널과 링크 모델을 공통 기반으로 삼을 수 있다. STA, SI, PD, Package Co-Design Flow에 공통 분모가 생긴다.
반대로, 표준이 생긴다는 건 “Interconnect 자체가 하나의 경쟁 포인트가 된다”는 뜻이기도 하다. 전력/대역폭/지연/Area를 더 좋게 만들 수 있는 PHY IP, Package 구조, Co-Optimization 기술을 가진 회사가 시장에서 우위를 점하게 된다.
패키지와 칩 설계의 경계가 흐려지는 시대
Chiplet Interconnect가 중요한 또 하나의 이유는 “설계 경계”를 무너뜨린다는 점이다.
예전에는 대략 이렇게 나눌 수 있었다.
Die 내부: Logic Design, Physical Design, STA, On-Die SI
패키지: PCB/Package Team이 따로, 훨씬 낮은 속도 기준으로 설계
Chiplet 구조에서는 이 둘을 완전히 나눌 수 없다. Die-to-Die Link의 채널은 패키지와 Die Edge 구조를 동시에 본다. Die 배치, Bump Mapping, Interposer Routing, Package Stack-Up, 그리고 Die 내부 PHY Placement가 한 번에 고민되어야 한다.
결국 이런 질문들을 한 팀이 같이 다루게 된다.
A Chiplet과 B Chiplet을 얼마나 떨어뜨려 놓을 것인가
Interposer 위에서의 채널 길이는 얼마나 허용할 수 있는가
Die Edge에 어떤 순서로 Bump를 배치할 것인가
On-Die NoC와 Die-to-Die Link의 Boundary를 어디로 잡을 것인가
이 과정에서 Package Engineer, PD Engineer, SI Engineer, System Architect, EDA Tool Vendor가 한 테이블에 앉게 된다.
Chiplet이 본격적으로 확산되면, 설계자에게 요구되는 관점도 바뀔 수밖에 없다.
단순히 “공정 몇 나노 이해”에서 끝나는 게 아니라
Interconnect의 물리, 논리, 프로토콜 레이어를 함께 이해하는 능력
On-Die NoC와 Off-Die Fabric을 통합해서 보는 System-Level 관점
Power/Area/Cost까지 포함한 End-to-End Trade-Off 분석 능력
이 세 가지가 점점 더 중요해질 것이다.
“아직도 Transistor, Logic, PD, STA만으로도 할 게 많은데 거기에 Interconnect, Package까지 붙냐”라는 생각이 들 수도 있다. 그래도 최소한 “칩 성능과 비용을 결정하는 진짜 병목이 어디인지” 정도는 알고 설계에 들어가는 게 낫다. 요즘에는 그 병목이 아주 자주 Interconnect 쪽으로 밀려온다.
본인 입장에서 보면, Chiplet 시대의 Interconnect는 피할 수 있는 주제가 아니라, 커리어를 넓힐 수 있는 좋은 기회에 가깝다. Die 안에서의 Timing, SI만 보던 사람이 Die-to-Die, Package까지 이해하는 순간 “칩 전체를 보는 사람”이 된다. 일할 수 있는 범위도 훨씬 넓어진다.