Logic 디자인 쪽만 하다가 DFT Lab에 처음 들어오면 제일 당황하는 지점이 있다.
Scan, ATPG, stuck-at pattern, transition pattern 이런 건 익숙한데, memory 쪽으로 가는 순간 갑자기 March algorithm, MBIST, fault model 이야기가 쏟아진다.
게다가 시니어 DFT 엔지니어들도 가끔 이런 걸 헷갈린다.
“March C-가 정확히 어떤 fault까지 커버하지? 단점이 뭐였더라…”
“왜 꼭 up/down으로 두 번씩 도는 거였지?”
이 글의 목표는 단순하다.
- DFT/ATPG는 이미 익숙하지만 memory test는 어색한 사람에게
- March algorithm이 무엇이고, 왜 그런 순서로 동작하는지,
- Logic test pattern과 무엇이 근본적으로 다른지
- 그리고 실무에서 자주 들리는 Checkerboard pattern이 어떤 역할을 하는지
1. Logic Test vs Memory Test: 패턴이 왜 달라질까?
1.1 Logic 쪽: Scan + ATPG의 세계
일반적인 logic block은 이렇게 테스트된다.
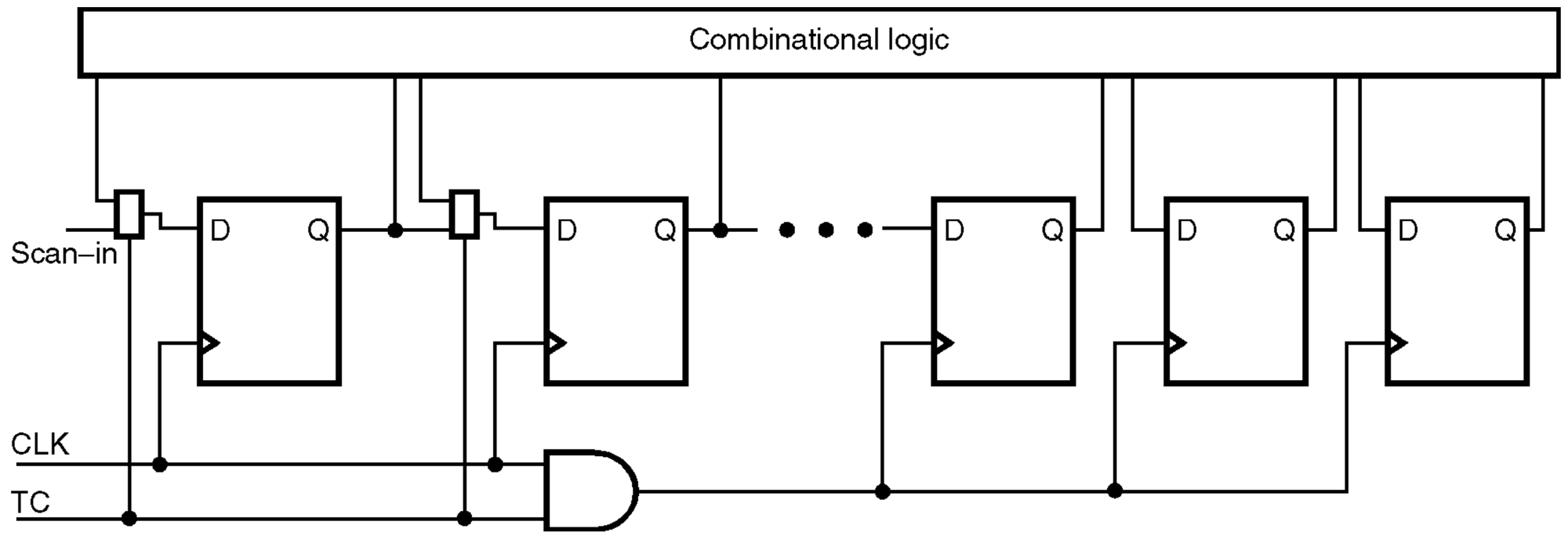
- Flip-flop들에 scan chain 삽입
- ATPG tool이 stuck-at fault, transition fault를 타깃으로 test vector 생성
- ATE 장비나 board에서
- 입력 포트 + scan-in으로 값 주입 (scan shift)
- capture
- scan-out으로 값 관찰
핵심 포인트는 세 가지다.
- Fault가 flip-flop (scan cell) 기준으로 정의된다.
- Test pattern 한 벡터가 여러 node를 동시에 자극한다.
- Fault activation → propagation → observation이 조합 논리 경로를 타고 흐른다.
그래서 logic 테스트의 철학은:
“한 번의 패턴으로 최대한 많은 fault를 커버하자.”
ATPG가 하는 일은 이 철학을 수학적으로/알고리즘적으로 풀어내는 작업에 가깝다.
1.2 Memory 쪽: 구조가 완전히 다르다
반대로 SRAM 같은 memory의 구조는 아래와 같다.
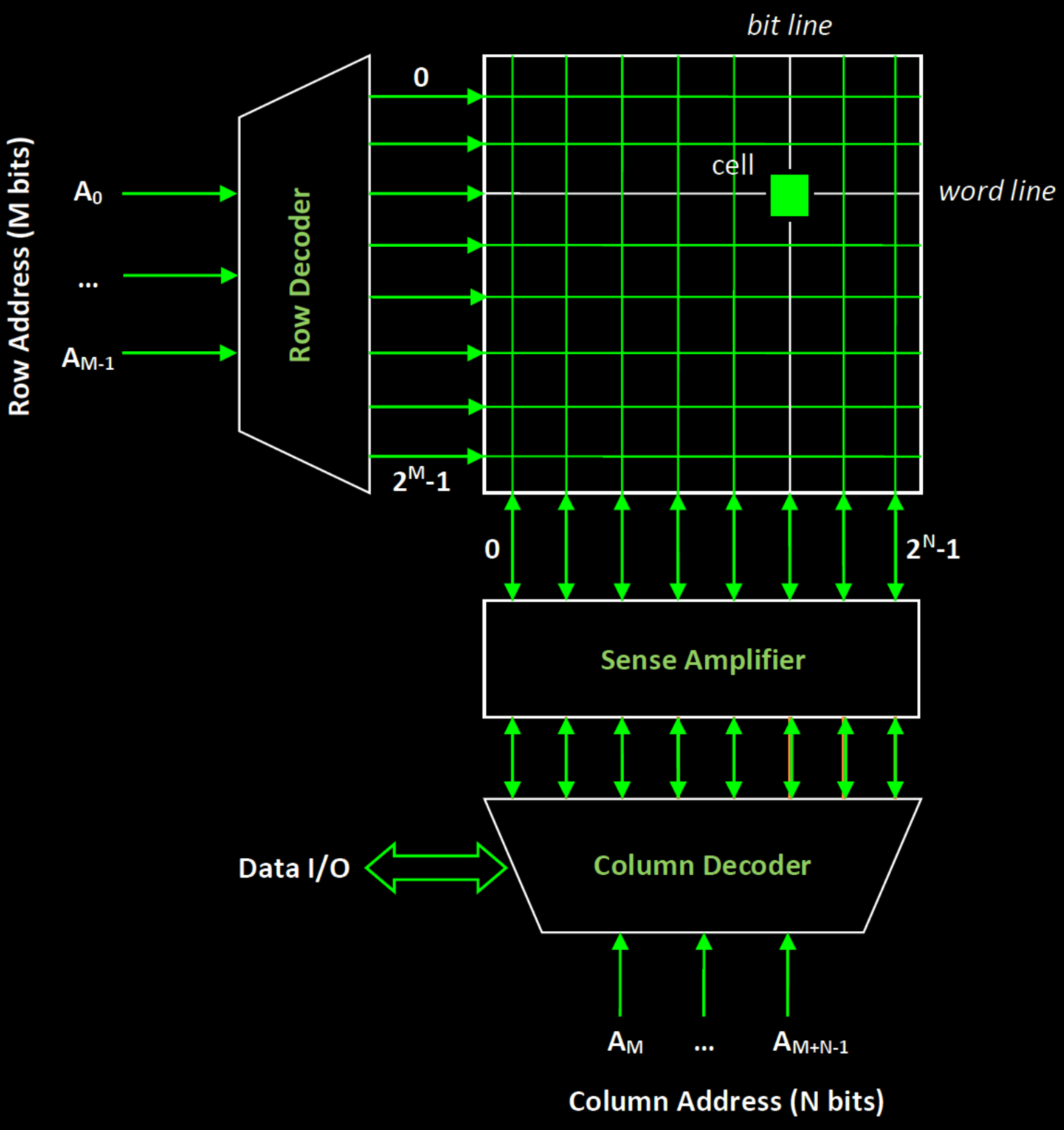
- Address decoder: 선택된 address의 wordline을 활성화
- Bitline pair + cell: 선택된 cell의 데이터를 읽거나 쓴다
- 보통 한 번에 한 address line만 접근 가능
이 구조 때문에 memory test에는 몇 가지 중요한 특징이 생긴다.
(1) Access granularity
- Logic: 여러 flip-flop / node를 한 번에 테스트
- Memory: 보통 “한 address씩 순서대로” 접근
(2) Fault model 자체가 다르다
- Logic: stuck-at, transition, bridging 등 gate/net 중심
- Memory:
- cell 자체의 불량
- cell 간 상호작용
- address decoder 이상
- 주변 cell pattern에 민감한 현상 등
대표적인 memory fault model만 봐도 이미 다르다.
- Coupling fault (CF)
- Address decoder fault (AF)
- Neighborhood pattern sensitive fault (NPSF)
- Read/Write destructive fault 등
(3) Sequence 의존성
어떤 fault는 예를 들어 아래와 같은 순서에서만 드러난다.
이 cell에 1을 쓰고 → 이웃 cell에 0을 쓰고 → 다시 원래 cell을 읽어봐야 깨진다.
즉, “어떤 순서로, 주변 cell이 어떤 data를 갖고 있을 때”가 중요하다.
그래서 memory는
- “한 번에 여러 node를 터뜨리는 ATPG vector” 보다는
- “모든 cell을 일정한 순서로 쭉 훑으면서, read/write 시퀀스를 반복하는 알고리즘”이 훨씬 잘 맞는다.
그게 바로 March algorithm이다.
말 그대로, address 공간을 한 줄로 세워서 행진(march)시키는 개념이다.
2. March Algorithm의 핵심 아이디어
2.1 정의: Address를 “행진(march)”하면서 테스트
March algorithm을 한 줄로 요약하면 이렇게 표현할 수 있다.
메모리의 모든 address를 일정한 방향(↑, ↓ 혹은 둘 다)으로 훑으면서,
각 address마다 미리 정의된 read/write 연산 시퀀스를 수행하는 test algorithm
표기법은 보통 다음과 같다.
↑: increasing addressing sequence↓: decreasing addressing sequence↕: increasing 또는 decreasing, 방향 무관 (모든 address를 한 번씩)wx: 값 x를 write (w0,w1)rx: 값 x를 read & check (r0,r1)
예를 들어:
↑ (w0) : address 0부터 MAX까지 가면서 각 cell에 0을 write
↑ (r0, w1) : 다시 0부터 MAX까지, 0인지 읽고(r0) 1을 write
이처럼 “방향 + 연산 시퀀스”를 묶은 것을 하나의 March element라고 부른다.
여러 element를 순서대로 이어 놓은 것이 하나의 March test다.

2.2 “그냥 w0→r0, w1→r1 두 번이면 안 되나?”
메모리 전체에 대해
w0 → r0 → w1 → r1
이 네 동작만 해주면 testing이 끝날까?
문제는 Memory fault model이다.
- 어떤 fault는 0→1 transition에서만 드러난다.
- 어떤 fault는 이웃 cell 상태에 따라 드러난다.
- 어떤 fault는 up 방향 address traversal에서는 멀쩡한데, down 방향에서는 문제를 일으킨다.
- 예: 특정 decoder path, coupling 구조 등
그래서 March algorithm은 다음을 강제한다.
- 각 cell이 0과 1을 모두 여러 번 경험하게 만들고
- 0→1, 1→0 transition을 모두 수행하게 만들고
- up/down 방향을 모두 돌면서 인접 cell과의 relative ordering을 바꿔본다.
이 과정을 통해 한 번에 커버하면서도, test time을 O(N) 수준으로 유지하는 알고리즘들이 현업에서 많이 쓰인다.
- 단일 cell fault
- 2-cell coupling fault
- address decoder fault
자, 그럼 구체적으로 어떤 March algorithm이 많이 쓰일까?
3. 우리가 딱 두 개만 기억한다면: March X & March C-
3.1 March X — 교육용으로 가장 단순한 기본형
March X는 가장 기본적인 March algorithm 중 하나다. 보통 아래처럼 쓴다.
1) ↑ (w0)
2) ↑ (r0, w1)
3) ↑ (r1, w0)
의미를 풀어보면:
- 모든 cell을 0으로 초기화 (
↑(w0)) - 다시 올라가면서
- 0인지 읽고 (
r0) - 1을 쓴다 (
w1)
- 0인지 읽고 (
- 다시 한 번 올라가면서
- 1인지 읽고 (
r1) - 0을 쓴다 (
w0)
- 1인지 읽고 (
이 정도만 해도:
- 모든 cell이 최소 한 번은 0, 1을 저장
- 0→1, 1→0 transition을 모두 수행
- 기본적인 Stuck-at fault, Transition fault는 어느 정도 검출 가능
한계도 분명하다.
↓방향 traversal이 없다.- Coupling fault, Address decoder fault에 대한 커버리지가 제한적이다.
그래서 개념 설명, 교육용, 아주 단순한 SRAM 정도에 쓰이는 경우가 많고,
실제 MBIST에서는 더 강력한 알고리즘을 쓴다.
3.2 March C- — 실무에서 가장 많이 쓰이는 표준형
실제 MBIST에서 가장 많이 등장하는 건 March C-다.
실제로는 SRAM designer들이 이것보다 더 많은 알고리즘을 설계해두었고,
March 이름도 다양하지만, 상당수는 March C-에서 파생된 family라고 봐도 된다.
March C-는 보통 아래처럼 정의한다.
1) ↕ (w0)
2) ↑ (r0, w1)
3) ↑ (r1, w0)
4) ↓ (r0, w1)
5) ↓ (r1, w0)
6) ↕ (r0)
여기서 ↕는 방향 상관 없이 “모든 address를 한 번씩” 이라는 의미로 이해하면 된다.
조금 더 풀어보면:
- 모든 cell에 0을 쓴다. (초기화)
- address를 위로 올리면서
- 0인지 읽는다 (
r0) - 1을 쓴다 (
w1)
- 0인지 읽는다 (
- 다시 위로 올리면서
- 1인지 읽는다 (
r1) - 0을 쓴다 (
w0)
- 1인지 읽는다 (
- 이번에는 address를 아래로 내리면서
- 0인지 읽고 (
r0) - 1을 쓴다 (
w1)
- 0인지 읽고 (
- 다시 아래로 내리면서
- 1인지 읽고 (
r1) - 0을 쓴다 (
w0)
- 1인지 읽고 (
- 마지막으로 전체를 한 번 더 훑으며
- 0인지 읽는다 (
r0)
- 0인지 읽는다 (
이 한 세트 안에 다음이 모두 들어 있다.
- 모든 cell이 0과 1을 여러 번 경험
- 0→1, 1→0 transition을 반복
- up / down traversal을 모두 수행
- 읽기 직후 이웃 cell 상태가 바뀌거나, 이전 패턴의 흔적이 남아 있는 상황을 일부러 만들어냄
그래서 March C- 하나로 아래를 상당히 잘 검출할 수 있다.
- Stuck-at fault (SAF)
- Transition fault (TF)
- 대부분의 Address decoder fault (AF)
- 대표적인 2-cell Coupling fault (CF)
실제 product-level memory BIST에서는 “March C- (또는 파생 변종)” + 추가 background 조합이 거의 디폴트처럼 쓰인다.
4. Fault Model 관점에서 March X vs March C-
감각을 잡기 위해 fault model 기준으로 둘을 비교해 보자.
(“O”는 일반적으로 좋은 커버, “△”는 부분적/제한적 커버 정도로 이해하면 된다.)
실무적인 요약은 간단하다.
- 연구실에서 기본 개념 설명 → March X
- 실제 product-level memory BIST → 거의 March C- (또는 C-에서 파생된 변종)
5. Memory 구조 관점에서 March가 직관적으로 보이는 이유
5.1 Access 방식
SRAM 한 bank를 떠올려보면:
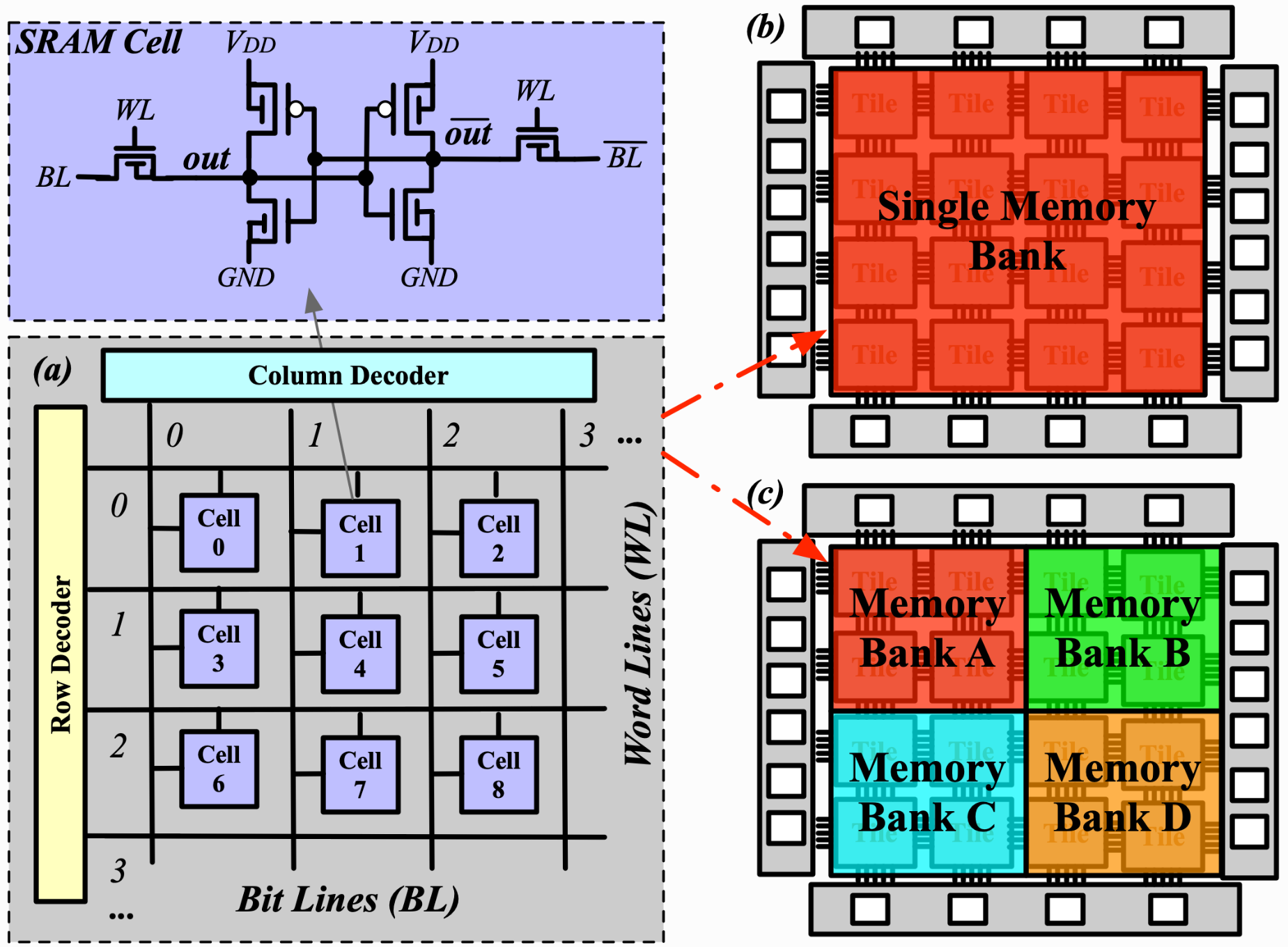
- Address bus로 특정 row(wordline)를 선택
- 그 row에 연결된 bitline을 통해 cell의 값을 읽거나 쓴다
- 한 번에 “한 address”만 확실하게 control 가능
그래서 test의 기본 단위는 자연스럽게 이렇게 된다.
“주소 하나 선택 → read/write 시퀀스 수행 → 다음 주소로 이동”
이 흐름 자체가 March element 정의와 거의 1:1로 겹친다.
5.2 Address decoder fault를 어떻게 잡는가?
예를 들어, 어떤 address에서:
- Decoder fault로 인해 두 개의 row가 동시에 켜진다고 하자.
- 이 address에
w1을 하면, 의도한 cell뿐 아니라 이웃 row의 cell도 같이 1이 될 수 있다.
이제 다른 address에서:
- 그 이웃 cell을
r0한다고 기대했는데1이 읽힌다.
March C-처럼 up/down으로 여러 번 왕복하면서 r0, r1을 반복하면
“의도하지 않은 cell이 함께 켜져서 덮어쓴 값”을 어느 시점엔 반드시 읽어보게 된다.
이게 March C-가 Address decoder fault를 검출하는 메커니즘이다.
5.3 Coupling fault를 어떻게 잡는가?
Coupling fault는 다음과 같은 상황이다.
aggressor cell에 특정 연산(write, toggle)을 했을 때
neighbor cell(victim)의 값이 바뀌거나 유지되지 않는 fault
March C-는:
- 어떤 cell에
w1을 한 직후 - 그 이웃 cell을
r0또는r1로 확인하는 패턴을 - up/down 방향을 바꾸어가며 여러 번 반복한다.
이 과정에서:
- “이웃 cell의 패턴이 특정 상태일 때만 드러나는 fault”를 찾기 위해
- 다양한 relative ordering을 강제로 만들어 놓는 셈이다.
단순히 Checkerboard pattern 한 번만 write/read 하는 것보다
시간은 조금 더 쓰지만 훨씬 높은 fault coverage를 얻는다.
6. Checkerboard Background와 March Algorithm
이제 실무에서 자주 듣는 Checkerboard를 끼워서 보자.
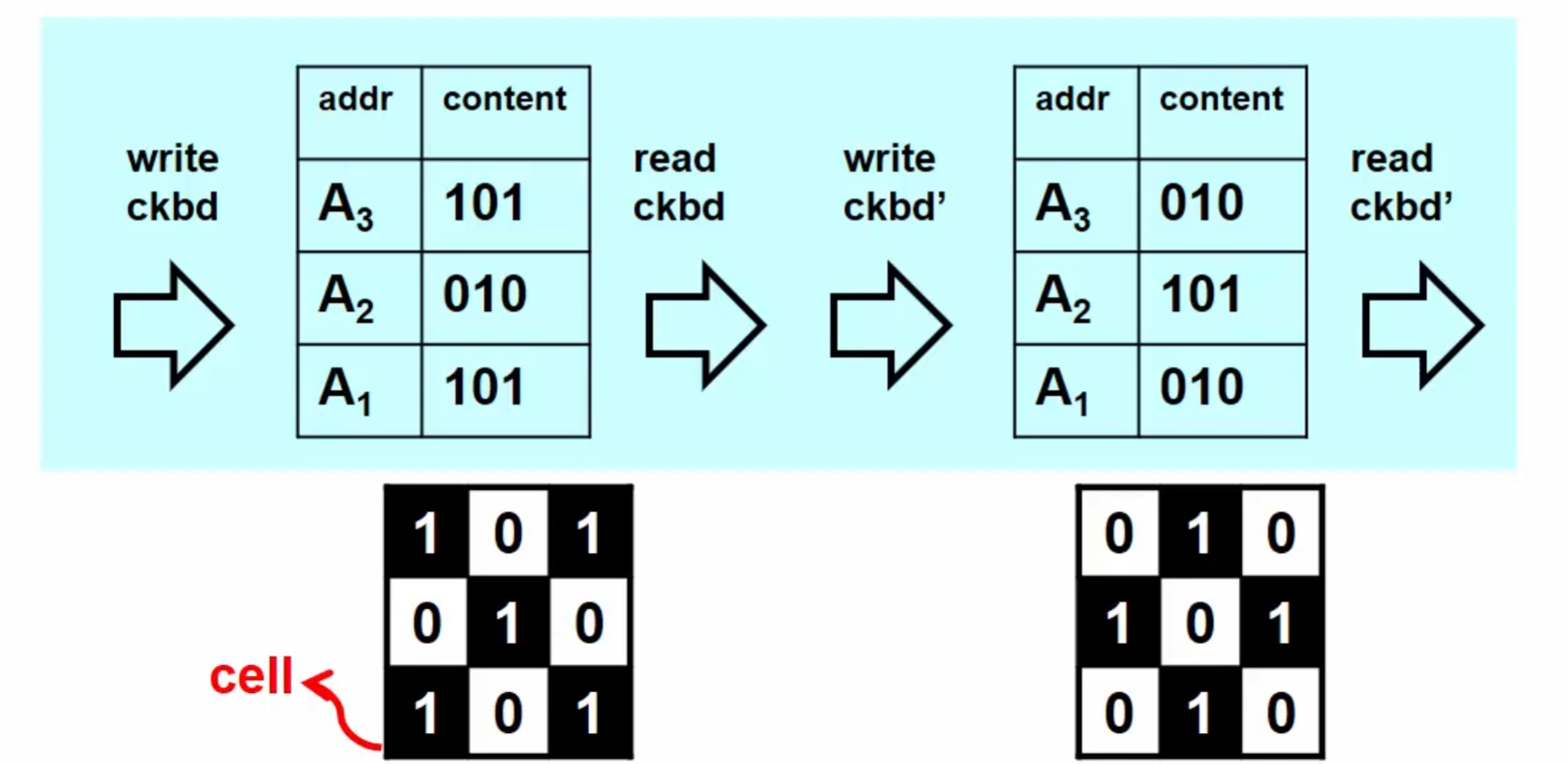
6.1 Checkerboard pattern이란?
한 줄 정의부터 하자.
Checkerboard pattern = memory cell들이01010101…/10101010…처럼
서로 이웃한 cell끼리 값이 항상 반대가 되도록 만든 data background.
비트 기준으로 보면:
- 패턴 A:
0x55...(…0101 0101) - 패턴 B:
0xAA...(…1010 1010)
주소 기준으로는 보통:
- 짝수 address →
0x5555_5555 - 홀수 address →
0xAAAA_AAAA
혹은 그 반대로 설정해서,
가로(비트 방향) / 세로(주소 방향) 모두에서 0과 1이 체스판처럼 번갈아 나오게 만든다.
이와 반대되는 패턴을 Inverse-checkerboard라고 부른다.
6.2 왜 굳이 Checkerboard를 쓰는가? (All-0/All-1이면 안 되나?)
All-0, All-1 패턴도 당연히 중요하다.
w0 → r0,w1 → r1만 해도 Stuck-at fault는 잘 잡힌다.- Transition fault도 어느 정도 커버된다.
문제는 이웃 cell 간 상호작용이다.
- bitline/wordline 간 short/bridge
- Coupling fault
- Neighborhood pattern sensitive fault (NPSF)
이런 fault는 아래와 같은 상황에서만 드러나는 경우가 많다.
- 두 cell이 서로 다른 값(0/1)을 가지고 있을 때
- 주변이 특정 pattern (예: 010/101)일 때
예를 들어, 두 cell이 약하게 short 되어 있다면:
- 둘 다 0이면 short가 있어도 0이어서 티가 안 날 수 있고
- 하나는 0, 다른 하나는 1일 때만 전류가 흐르면서 값이 뒤틀릴 수 있다.
그래서 test 입장에서는:
“이웃한 cell들이 항상 서로 반대 값”인 상황을 만들어서
bitline / cell / wordline 사이의 간섭을 최대한 자극하고 싶다.
그걸 가장 간단하게 만들어주는 것이 Checkerboard pattern이다.
6.3 Checkerboard와 March의 관계
여기서 헷갈리기 쉬운 포인트가 있다.
- March algorithm =
↑, ↓+(r0, w1, r1, w0 …)같은 연산 시퀀스 - Checkerboard =
그 연산 시퀀스를 실행할 때의 data background
즉, 구조를 이렇게 보면 편하다.
- Data background를 solid 0 / solid 1 / checkerboard / inverse-checkerboard 중 하나로 세팅
- 그 상태에서 March algorithm sequence 실행
예를 들어:
- Step 1: memory 전체를 Checkerboard로 채운다.
- Step 2: 그 상태에서
March C-의↑(rX, wY)element를 수행한다. - Step 3: Inverse-checkerboard로 전환하고 다시 March를 돌린다.
MBIST 툴 스크립트에서 흔히 보게 되는 구성이 바로 이런 식이다.
Algorithm:March C-
Background:solid 0/1,checkerboard,inverse-checkerboard
이렇게 Algorithm과 Background를 orthogonal하게 정의해놓고,
조합으로 fault coverage를 끌어올린다.
실제 제품 스펙에서는 대략 이런 그림이 나온다.
- Consumer SoC:
March C- @ solid 0/1- 필요시 짧은 checkerboard sequence 추가
- Automotive / 서버급 SoC:
March C- @ solid 0/1March C- @ checkerboard / inverse-checkerboard- 추가로 March SS, NPSF-oriented algorithm까지 얹어 진단 커버리지 목표를 맞춘다.
7. MBIST 관점에서 March / Checkerboard는 언제, 어떻게 결정되는가?
이제 마지막으로,
“이 Test vector/algorithm은 설계 플로우에서 언제 정해지냐?”를 정리해보자.
여기서 March algorithm과 ATPG vector를 헷갈리지 않는 게 중요하다.
7.1 Algorithm 선택 기준
현업에서 알고리즘을 고르는 과정은 보통 이렇게 요약할 수 있다.
Test requirement + Memory 특성 + Test time(ATE 비용) + Tool/Library 기본값
- 제품 성격
- Consumer electronics SoC → “적당한 품질 + 짧은 test time”
- Automotive / Safety-critical → “매우 높은 신뢰성 + 더 긴 test time 감수”
- 목표 DPPM/PPM, 표준 요구사항
- ISO 26262 진단 커버리지
- Foundry / 고객 coverage guideline
- Memory 특성
- Single-port / Dual-port / Multi-port SRAM
- Register file, CAM, ROM, eDRAM, eFlash 등
- bitcell 구조, redundancy, ECC 유무
- 예: eFlash/eFuse/NVM은 program/erase/retention test 포함
- Multi-port SRAM은 port interaction fault를 위해 port 간 read/write 조합을 넣은 March 변종 사용
실무에서는 Memory compiler / IP vendor가 추천 March set을 같이 주는 경우가 많다.
“이 SRAM macro는 March C- + Checkerboard 기준으로 fault coverage XX% 달성”DFT 엔지니어는 이를 기반으로
- 회사 표준 / 고객 요구와 맞는지 확인
- 부족하면 March element를 하나 더 얹거나, background를 추가하는 식으로 커스터마이즈
한다.
추가로, 많은 회사에서는 BU / 회사 차원에서 표준 MBIST 알고리즘 세트를 운영한다.
- 예)
March C- + March LA + Checkerboard - 새 프로젝트의 DFT 엔지니어는 이걸 기본값으로 쓰고,
특이한 memory(eFlash, 특수 SRAM 등)만 따로 튜닝한다.
실제로 개별 엔지니어가 March algorithm을 완전 처음부터 설계하는 경우는 많지 않고,
표준 템플릿 + 약간의 커스터마이즈가 현실에 가깝다.
7.2 실제 Design/Test Flow 안에서의 위치
Chip design 플로우에 대입해서 보면 대강 이런 순서다.

- Chip 아키텍처 설계
- Product spec, Test requirement 결정
- 어떤 종류의 SRAM을 어디에, 어떤 크기로 split해서 쓸지 대략 정해진다.
- “우린 MBIST 쓸 거고, 표준 March는 C- 기반” 정도의 합의가 이 단계에서 나는 경우도 많다.
- Foundry design methodology guide에 제안 March 알고리즘이 있는 경우도 있다.
- Silicon virtual prototyping 단계에서 P&R floorplan 레벨까지 감이 잡힌다.
- DFT 아키텍처 설계 단계
- Scan 구조, JTAG, boundary scan, LBIST, MBIST 전체 다이어그램 설계
- 여기서:
- MBIST controller를 몇 개 둘지
- 어떤 memory들을 한 controller에 묶을지 (grouping)
- 각 controller에 어떤 March algorithm + background 세트를 태울지
의 흐름이 잡힌다.
- RTL / Netlist 단계에서 MBIST 삽입 (DFT insertion)→ 이 단계에서 March algorithm + Checkerboard 같은 background가 툴 옵션으로 “고정”된다고 보면 된다.
- Synopsys DFT Compiler, Siemens Tessent, Cadence Modus 같은 툴로
MBIST controller + wrapper + address/data mux를 자동 삽입한다. - 옛날에는 Synopsys 쪽 DFT 툴이 압도적으로 많이 쓰였고,
요즘은 Tessent를 쓰는 회사도 상당히 많고, Modus를 쓰는 곳도 있다. - 이때 MBIST 스크립트에서:
- Algorithm:
March C-(또는 변종) - Background:
solid 0/1,checkerboard등 - Port type, diagnostic 옵션 등을 설정한다.
- 그리고 여기서 나온 Port type 정보를 RTL 엔지니어에게 다시 보냅니다.
- Algorithm:
- Synopsys DFT Compiler, Siemens Tessent, Cadence Modus 같은 툴로
- Simulation / Verification 단계
- RTL sim 또는 Gate-level sim에서:
- MBIST sequence가 제대로 돌아가는지
- memory model이랑 handshake가 정상인지
- fault injection 모드로 몇 개 fault를 넣었을 때 BIST가 fail을 잘 잡는지
- 현실적으로 March full sequence 전체를 gate-level에서 끝까지 돌리지는 않는다.
타이밍, 성능 상 부담이 크기 때문에:- 축약된 시퀀스
- handshake 중심
- 일부 fault scenario 위주의 sim
식으로 sanity check를 하는 경우가 많다.
- RTL sim 또는 Gate-level sim에서:
- Fab-out 이후 (실리콘 / ATE / 양산)
- 실제 칩에는 이미
MBIST controller + March microcode/hard-wired sequence가 들어있다. - ATE 쪽 vector는 크게 보면:
- JTAG/Test mode 핀으로 MBIST 실행 명령 넣기
- BIST done/fail flag, fail address 등을 읽어오기
- 즉, memory cell 하나하나를 외부 tester vector로 직접 자극하는 구조가 아니라,
칩 안에서 March algorithm이 자율 실행되고,
tester는 “버튼 눌러서 BIST 시키고 결과 받는 역할”에 가깝다.
- 실제 칩에는 이미
8. 요약: DFT/ATPG 엔지니어가 기억해두면 좋은 포인트
정리해보면, DFT/ATPG 엔지니어 입장에서 아래 정도만 머리에 들어 있으면 쓸모가 많다.
- Logic test와 Memory test는 철학부터 다르다.
- Logic: scan + ATPG, gate-level fault 중심
- Memory: address 단위 sequential access, cell/neighbor/decoder fault 중심
- March algorithm은 “address를 행진시키며 read/write 시퀀스를 반복하는 test”다.
- 방향(↑/↓) + 연산(r0/r1/w0/w1) 조합이 핵심
- 기본 개념은 March X로 잡고, 실제 실무는 March C-를 기준으로 본다.
- Checkerboard는 Algorithm이 아니라 Background다.
March C- @ solid 0/1로 cell 자체를,March C- @ checkerboard/inverse-checkerboard로 neighbor-interaction까지 보는 구조라고 이해하면 된다.
- Algorithm 선택은 MBIST 삽입 단계에서 툴 옵션으로 결정된다.
- 논문 읽고 예쁜 March 골라서 나중에 vector 만들 때 얹는 게 아니라,
- DFT architecture / MBIST insertion 시점에 test requirement, memory 특성, test time을 보고 정해진다.
이 정도를 알고 있으면,
칩 설계 회의에서 DFT 팀을 어떻게 컨트롤해야 할 지 감이오고, MBIST spec이나 foundry guideline을 읽을 때도 훨씬 편해진다.
그리고 나중에 자기만의 custom March + background를 설계해야 할 순간이 오더라도,
지금 정리한 이 프레임이 좋은 출발점이 될 거다.