최근 글로벌 인공지능 인프라 시장은 단순한 성능 경쟁을 넘어선, "어떤 회사의 하드웨어를 사용하는가? 하드웨어 독립성이 있는가?" 같은 구조적인 지각 변동을 겪고 있다.
지난 10여 년간 NVIDIA GPU가 주도해 온 범용 가속기(General-Purpose Accelerator) 시대는 거대언어모델(LLM)과 생성형 AI(Generative AI)의 폭발적인 수요 증가, 그리고 이에 따른 전력 및 비용 효율성 위기에 직면하여 중대한 전환점을 맞이했다.
모델의 파라미터 수가 조 단위(Trillion)를 넘어서고, 학습(Training) 중심의 자본 지출(CAPEX)이 대규모 추론(Inference) 서비스 운영 비용(OPEX)으로 전이됨에 따라, 시장은 '모든 워크로드를 위한 하나의 범용 Chip'에서 '워크로드별 최적화된 ASIC' 체제로 빠르게 재편되고 있다.
현재 시장의 핵심 축인 엔비디아의 차세대 Blackwell 플랫폼, 그리고 그 아성을 무너뜨리려고 하는 구글(Google)의 TPU(Tensor Processing Unit) 생태계, 아마존웹서비스(AWS)의 Trainium/Inferentia 라인업, 그리고 니치한 일부 분야에서부터 파괴적 혁신을 시도하는 스타트업들의 NPU들을 대상으로 심층적인 기술 분석과 비즈니스 타당성을 검토한다.

1.1. 학습 독점의 지속과 추론 시장의 파편화
인공지능 개발 및 배포에 가장 많은 비용은 "인공지능 학습, 인공지능 추론" 작업에 사용된다.
Mckinsey에 따르면 2030년 AI 인프라 지출의 약 절반 이상이 추론 워크로드로 전환될 것으로 전망한다.

SW가 바뀐다는 것은, HW의 선택의 기준이 바뀐다는 뜻이고, 학습용 반도체에서 추론 향으로 반도체로 바뀐다는 뜻은 중요 벤치마크가 'Peak Throughput'에서 'Cost-per-token', 'Latency), 'Performance/Watt'으로 이동함을 의미한다.
학습 영역에서는 엔비디아의 CUDA 생태계와 Blackwell 아키텍처가 제공하는 유연성이 여전히 강력한 해자를 구축하고 있으나, 비용 민감도가 높은 추론 영역에서는 구글 TPU와 AWS Trainium와 같은 클라우드 서비스 제공자의 자체 실리콘이 엔비디아의 시장 점유율을 잠식하고 있다.

특히 Meta와 같은 하이퍼스케일러들이 Llama 3와 같은 개방형 모델을 훈련시키는 데 있어 엔비디아 H100 클러스터에 수조 원을 쏟아부었으나, 이를 서비스하는 단계에서는 자체 칩이나 대안적 아키텍처를 적극적으로 도입하고 있다는 점은 시사하는 바가 크다.
1.2. Edholm's Law & Moore's Law
Edholm's law는 전기 통신 네트워크의 대역폭이 18개월마다 2배 증가, Moore's law는 24개월마다 반도체 집적도가 2배가 되는 것을 의미한다.
거대 모델의 성능 병목은 Logic 반도체의 연산 속도(FLOPS)가 아닌 Memory Bandwidth과 칩 간 통신 Interconnect에서 발생한다. NVIDIA의 NVLink, Google의 Optical Circuit Switch, AWS의 Elastic Fabric Adapter는 모두 이 병목을 해소하기 위한 각기 다른 접근법을 보여준다.

2. NVIDIA Blackwell B200: 스케일업(Scale-Up) 아키텍처의 극한
NVIDIA의 Blackwell 아키텍처는 전작인 Hopper(H100)의 성공 방정식을 계승하면서도, 물리적 한계를 돌파하기 위해 'Chiplet' 설계와 'Rack-scale' 통합이라는 과감한 수를 두었다. 이는 단순한 칩 성능 향상을 넘어, 데이터센터 전체를 하나의 거대한 GPU로 전환하려는 엔비디아의 야심을 보여준다. 물론 AMD도 하고 있다.
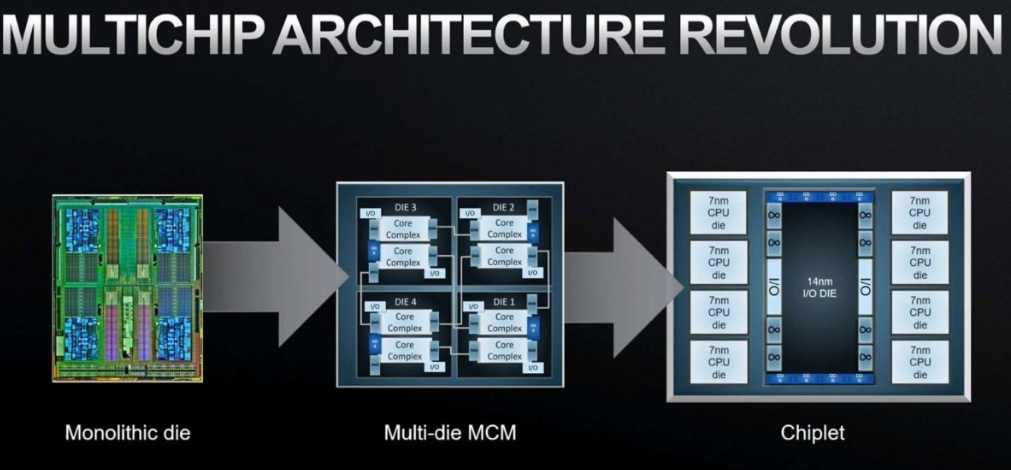
2.1. 칩렛 디자인과 NV-HBI의 기술적 함의
Blackwell B200 GPU는 Single silicon die의 Reticle Limit에 도달한 상황에서 성능을 높이기 위해, 두 개의 레티클 제한 다이를 패키징 단계에서 결합하는 방식을 채택했다.

총 2,080억 개의 트랜지스터가 집적된 이 구조의 핵심은 두 다이를 연결하는 NV-HBI(High Bandwidth Interface)다. NV-HBI는 초당 10TB의 양방향 대역폭을 제공하여, 소프트웨어 입장에서 두 개의 다이가 완벽하게 하나의 칩처럼 동작하도록 보장한다.
경쟁사들에서 발견된 이슈인, 칩렛 간 통신에서 발생할 수 있는 미세한 지연 시간이나 NUMA(Non-Uniform Memory Access) 이슈를 겪는 것과 대조적으로, 개발자에게 투명한 단일 메모리 공간을 제공함으로써 프로그래밍 복잡도를 제거했다.

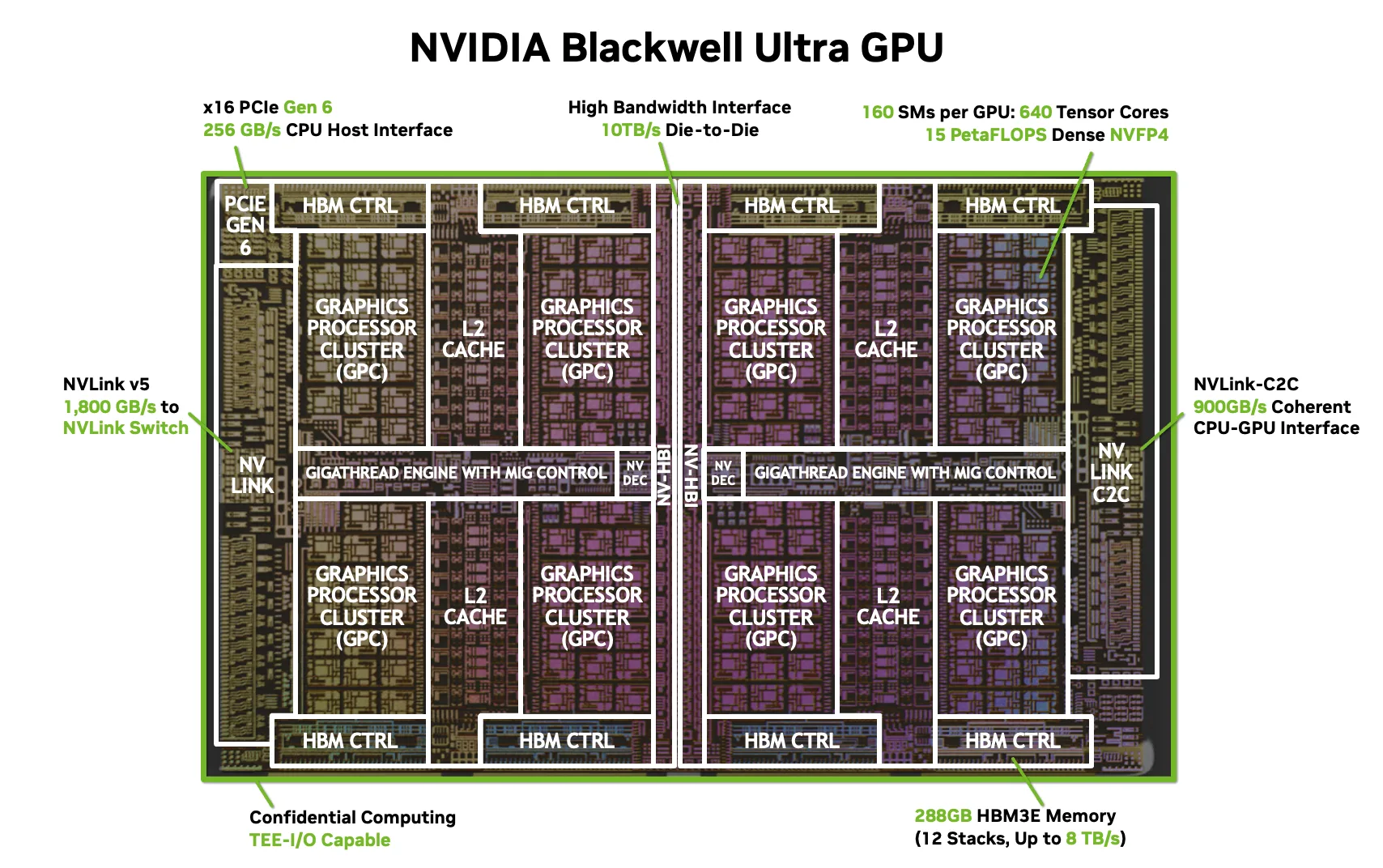
2.2. 제2세대 Transformer Engine과 FP4 정밀도 혁명
B200의 가장 파괴적인 혁신은 FP4 연산 지원이다. 기존 H100이 FP8 정밀도를 통해 FP16 대비 2배의 성능을 냈다면, B200은 FP4를 통해 다시 한번 데이터 크기를 절반으로 줄이고 연산 밀도를 2배 높였다. 이는 메모리 대역폭의 물리적 한계를 데이터 압축 기술로 우회하려는 시도다.

- 성능 수치: B200은 FP4 Tensor Core를 통해 칩당 최대 20 PFLOPS의 Sparse 연산 성능을 제공한다.
- Dense 연산 기준으로도 FP8에서 4.5 PFLOPS(B200) 및 10 PFLOPS(B200, 2-die combined effective) 수준에 달했다.
- H100(FP8 Dense 약 4 PFLOPS) 대비 비약적인 향상을 이뤘다.
- 기술적 과제: FP4와 같은 초저정밀도 연산은 모델의 Accuracy 저하를 유발할 수 있다. 엔비디아는 이를 해결하기 위해 'Micro-tensor Scaling' 기술을 도입했다. 이는 텐서 전체가 아닌 미세한 블록 단위로 스케일링 팩터를 적용하여, 정밀도 손실을 최소화하면서 Dynamic Range를 유지하는 기법이다.
2.3. GB200 NVL72: 랙 자체가 하나의 칩으로
엔비디아는 B200을 개별 서버에 탑재하는 것을 넘어, GB200 NVL72라는 랙 스케일 솔루션을 표준으로 제시했다. 이 시스템은 36개의 Grace CPU와 72개의 Blackwell GPU를 하나의 랙에 통합하고, 5세대 NVLink를 통해 모든 GPU를 All-to-All로 연결한다.
- NVLink 5.0: GPU당 1.8TB/s의 양방향 대역폭을 제공하며, NVL72 시스템 전체적으로는 130TB/s라는 천문학적인 대역폭을 달성했다. 이는 72개의 GPU가 마치 하나의 거대한 Shared Memory 공간을 가진 단일 가속기처럼 작동하게 하며, Trillion-parameter Models을 메모리에 올려 실시간으로 추론하는 것을 가능케 한다.8
- 전력 및 열 설계: B200은 최대 1,000W~1,200W의 TDP를 갖는다. NVL72 랙 하나가 최대 120kW에 달하는 전력을 소모하므로, Air Cooling 방식으로는 한계가 있다. 이에 엔비디아는 Liquid Cooling을 기본 설계에 포함시켜 데이터센터 인프라의 근본적인 변화를 강제하고 있다.
3. Google TPU v5p & Ironwood: 효율성과 스케일 아웃(Scale-Out)의 미학
구글은 엔비디아와 달리 철저하게 자사 클라우드 서비스와 AI 모델(Gemini)에 최적화된 수직 계열화 전략을 취한다. TPU 아키텍처는 범용성을 일부 희생하더라도 행렬 연산 효율과 전력 효율을 극대화하는 'Systolic Array' 구조를 기반으로 한다.
3.1. TPU v5p: 학습을 위한 최강의 스케일러빌리티
TPU v5p는 Training에 특화된 고성능 가속기다.
- 성능: 칩 당 459 TFLOPS (BF16)의 연산 성능과 95GB HBM2e 메모리, 2,765 GB/s의 메모리 대역폭을 제공한다.
- 수치상으로는 엔비디아 H100 대비 낮아 보일 수 있으나, TPU의 진정한 강점은 'Pod' 단위의 확장성에 있다.
- 3D Torus Interconnect: TPU v5p는 칩당 1,200 GB/s의 Inter-Chip Interconnect 대역폭을 가지며, 이를 통해 최대 8,960개의 칩을 3D Torus 토폴로지로 연결하여 단일 Pod를 구성한다.
- 엔비디아의 2계층 네트워크(NVLink + InfiniBand/Ethernet) 구조와 달리, 칩 간 직접 연결을 통해 통신 지연을 최소화하고 네트워크 복잡성을 제거했다.
- ICI Resiliency: 광학 링크나 OCS 장애 시 트래픽을 자동으로 우회시키는 Resiliency 기능이 기본 탑재되어, 수천 개의 칩이 장기간 학습을 수행할 때 발생하는 하드웨어 장애로 인한 중단을 방지한다.
3.2. Ironwood (TPU v7): 추론을 위한 정밀 타격
2025년 공개된 Ironwood(TPU v7)는 구글이 추론 시장을 장악하기 위해 내놓은 승부수다.
- 추론 특화 설계: Ironwood는 TPU 최초로 네이티브 FP8 연산을 지원하며, 칩당 4.6 PFLOPS의 Dense FP8 성능을 제공한다.
- 이는 엔비디아 B200(4.5 PFLOPS)과 대등한 수준으로, 구글이 추론 성능에서도 엔비디아를 정면으로 겨냥했음을 보여준다.
- 압도적인 메모리 및 통신: 칩당 192GB HBM3e 메모리와 7.4 TB/s의 대역폭을 탑재하여 대규모 모델의 KV Cache를 효율적으로 처리한다. 또한 칩 간 통신 대역폭을 9.6 Tbps (1.2 TB/s)로 대폭 늘려, 추론 시 발생하는 칩 간 데이터 교환 병목을 해소했다.
- OCS (Optical Circuit Switch): Ironwood는 MEMS 기반의 광 회로 스위치를 통해 데이터센터 내 수천 개의 칩 연결 토폴로지를 소프트웨어적으로 10나노초 이내에 재구성할 수 있다.
- 이는 워크로드 특성(학습 vs 추론, Dense vs Sparse)에 따라 최적의 네트워크 구조를 실시간으로 변경하는 구글만의 기술이다.
4. AWS Trainium & Inferentia: 클라우드 네이티브 실용주의
AWS는 하이퍼스케일러 중 가장 실용적이고 비용 효율적인 접근 방식을 취한다.
엔비디아 GPU를 대체하는 것이 아니라, 대규모 워크로드에서 비용을 절감하고자 하는 고객들에게 '합리적인 대안'을 제공하는 전략이다.
4.1. Trainium2 (Trn2) 아키텍처 및 성능
Trainium2는 2세대 학습 전용 칩으로, 전작 대비 4배의 성능 향상을 이뤘다.
- NeuronCore-v3: 칩당 8개의 NeuronCore-v3를 탑재하며, 총 1.3 PFLOPS의 Dense FP8 연산 성능(Sparse 기준 5.2 PFLOPS)을 제공한다.17 이는 엔비디아 GPU 대비 절대 성능은 낮지만, 전력 효율과 가격 경쟁력으로 승부한다.
- 메모리 서브시스템: 칩당 96GB HBM3e와 2.9 TB/s의 대역폭을 갖추고 있어 17, Llama 3 70B와 같은 모델을 효율적으로 샤딩하여 학습할 수 있다.
- UltraCluster 및 EFA: Trainium2는 AWS의 고성능 네트워크 인터페이스인 EFA(Elastic Fabric Adapter)와 긴밀히 통합되어, 최대 10만 개 이상의 칩을 연결하는 UltraCluster를 구성할 수 있다. 이는 전용 스위치(NVSwitch)가 필요한 엔비디아와 달리, 표준 이더넷 기반 기술을 활용하여 확장의 유연성을 제공한다.
5. Groq LPU: 결정론적(Deterministic) 아키텍처의 파괴적 혁신
Groq는 기존 GPU/TPU의 구조적 비효율성(메모리 계층구조로 인한 지연)을 지적하며, 완전히 새로운 아키텍처인 LPU(Language Processing Unit)를 제시했다.
5.1. TSP (Tensor Streaming Processor) 아키텍처
Groq 칩(LPU)의 가장 큰 특징은 HBM(고대역폭 메모리)이 없다는 점이다. 대신 칩 내부에 230MB의 초고속 SRAM을 탑재하고, 이를 80 TB/s라는 경이적인 대역폭으로 연결했다.20

- 메모리 병목 제거: 기존 GPU는 HBM에서 데이터를 가져오는 데 수백 사이클을 소비하지만, Groq는 온칩 SRAM에서 데이터를 즉시 공급받아 연산 유닛(ALU)을 쉬지 않고 가동한다. 이는 Batch Size가 1인 상황에서도 GPU 대비 수십 배 높은 효율을 낸다.
- 결정론적 실행: Groq 하드웨어에는 캐시 미스(Cache Miss), 분기 예측(Branch Prediction), 동적 스케줄링 로직이 없다. 모든 데이터 이동과 연산 타이밍은 컴파일러가 사전에 사이클 단위로 완벽하게 계획한다.21 이로 인해 멀티 칩 확장 시 동기화 오버헤드가 '0'에 수렴하며, 지연 시간의 불확실성(Jitter)이 제거된다.
5.2. 확장성과 한계
Groq 아키텍처의 치명적인 단점은 칩당 메모리 용량(230MB)이 작다는 것이다. Llama 3 70B 모델을 구동하기 위해서는 최소 256개 이상의 칩을 연결한 Rack 단위 시스템이 필요하다. 이는 초기 도입 비용(CAPEX)을 높이고 시스템 복잡도를 증가시키는 요인이다. 하지만 Groq는 이를 통해 초당 300~500 토큰이라는 압도적인 추론 속도를 달성하며, 실시간 음성 비서나 고빈도 트레이딩 등 지연 시간이 핵심인 시장에서 독보적인 위치를 점유하고 있다.