반도체 품질 보증과 DFT의 진화
현대 반도체 산업, 특히 System on Chip 설계 분야에서 Design for Testability, 이하 DFT는 제조 후 검증을 위한 설계를 넘어, 전체 제품의 생명 주기와 경제성을 결정짓는 핵심 공학 분야로 자리 잡았습니다.

무어의 법칙에 따른 트랜지스터 집적도의 기하급수적 증가는 필연적으로 Manufacturing Defects의 발생 확률을 높였으며, 7nm, 5nm, 3nm로 이어지는 초미세 공정 노드에서는 기존의 단순한 Stuck-at Fault 모델로는 설명할 수 없는 복잡한 결함 메커니즘이 등장하고 있습니다.
DFT의 주된 목적은 크게 세 가지로 요약됩니다.
- 첫째는 Fault Coverage의 극대화를 통한 품질 보증입니다. Automotive, 항공우주, 의료 기기 등 Functional Safety이 필수적인 분야에서는 DPPM(Defective Parts Per Million)을 0에 가깝게 유지하는 것이 필수적입니다.
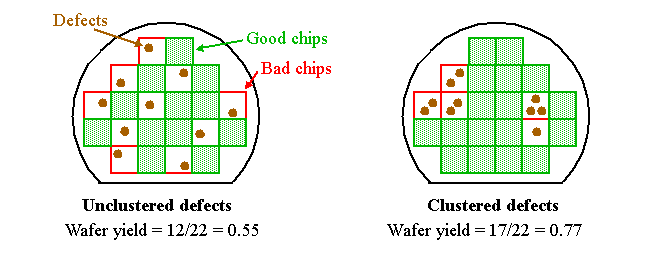
- 둘째는 Test Cost의 절감입니다. 테스트 시간은 칩의 생산 단가와 직결되므로, 최소한의 패턴과 시간으로 최대한의 결함을 검출하는 효율적인 아키텍처가 요구됩니다.
- 세번째는 Yield입니다. 결함을 고려하여, Redundancy 설계를 하는 방법이나, 결함이 있는 core를 사용하지 않도록 on/off를 할 수 있는 설계들입니다. (High speed CPU 설계에 이런 것들이 많이 사용됩니다.)
Scan Architecture: DFT의 첫 걸음.
디지털 로직 테스트의 난제는 수백만 개의 플립플롭이 존재하는 Sequential Circuit의 상태를 외부에서 제어하고 관측하는 것이 불가능에 가깝다는 점입니다.
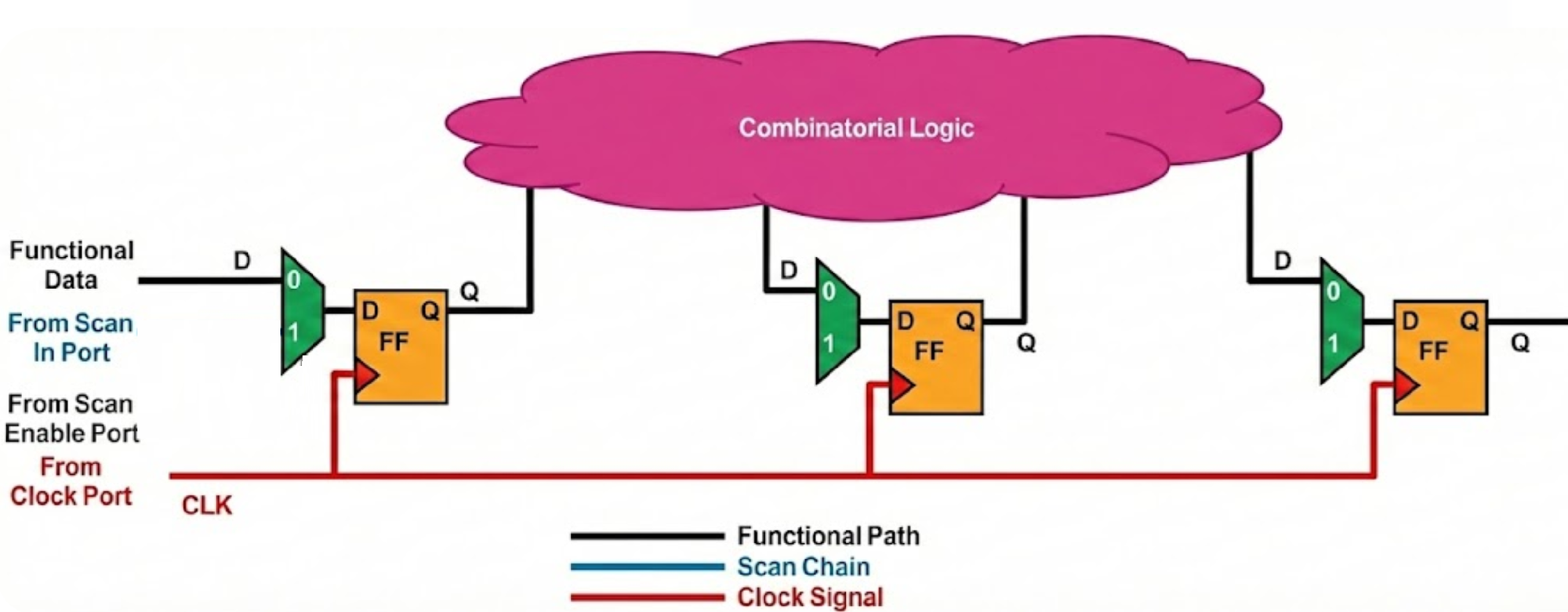
현대 반도체 칩에는 아래같은 회로가 수억 수십억개 이상 있습니다. 칩 내에 모든 Flipflop이 잘 동작하는지를 확인하기 위해 DFT가 사용되고, 특히 이러한 Sequentail circuit test에는 SCAN 설계가 주로 사용됩니다.
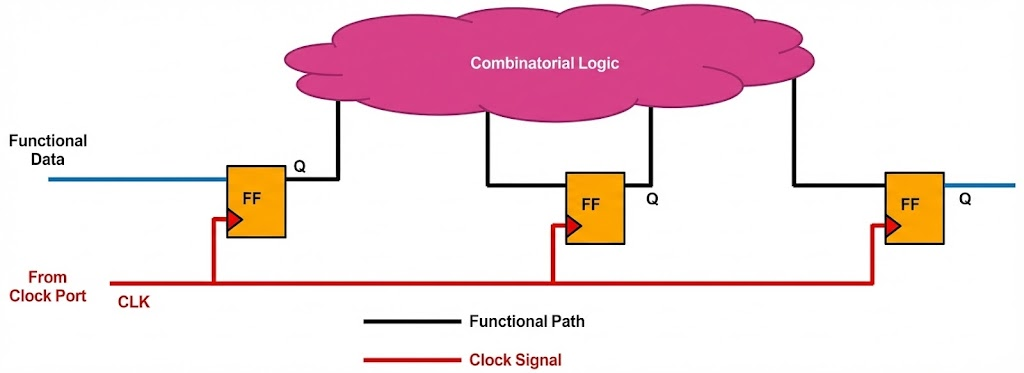
스캔 아키텍처는 이러한 순차 회로를 테스트 모드에서 거대한 Shift Register로 변환함으로써, Controllability과 Observability을 확보하는 가장 근본적인 해결책입니다.
2.1 스캔 셀(Scan Cell)의 구조와 동작 원리
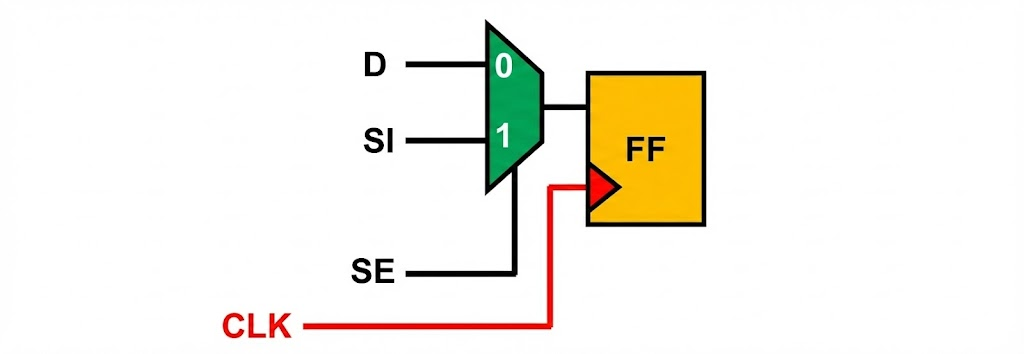
RTL 합성(Synthesis) 과정에서 DFT 컴파일러는 디자인 내의 일반적인 D 플립플롭(D-FF)을 스캔 기능이 포함된 특수 셀로 치환합니다. 업계 표준으로 가장 널리 사용되는 방식은 Mux-D 스캔(Multiplexed Scan Flip-Flop) 스타일입니다.
2.1.1 SCAN D FlipFlop의 내부 메커니즘
Mux-D 스캔 셀은 기능적 데이터 입력(D) 외에 테스트용 Scan Input (SI)과 이를 선택하기 위한 Scan Enable (SE) 신호를 포함합니다. 이 구조는 입력단에 2:1 멀티플렉서(MUX)를 추가하는 형태로 구현됩니다.
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
q <= 1'b0;
end else begin
if (se)
q <= si;
else
q <= d;
end
endendmodule
- if {SE =0} : MUX는 시스템 데이터 입력(D)을 선택하여 플립플롭으로 전달합니다. 이때 칩은 원래의 기능모드로 동작합니다.
- else: SI의 데이터를 받습니다.
2.1.1 SCAN D FlipFlop의 내부 메커니즘
이러한 치환 과정은 넷리스트 상에서 자동으로 이루어지며, 추가된 MUX로 인해 데이터 경로에 약간의 Delay가 발생할 수 있습니다. 따라서 DFT 엔지니어는 SCAN Insertion 후 Timing Constraints을 업데이트하고, 기능적 경로의 타이밍 마진(Setup/Hold margin)에 미치는 영향을 분석해야 합니다.
아까 우리 회로를 다시보면 이렇게 생겼습니다.
2.2 SCAN Insertion
Synthesis Tool 예를들어 DesignCompiler의 경우 compile -scan을 사용하면, SCAN Cell로 변경합니다. Synthesis tool은 Cell 변경만 합니다.
2.2 스캔 스티칭(Scan Stitching)과 체인 최적화
스캔 셀로의 치환이 완료되면, DFT Tool이 이들을 연결하는 Stitching 과정이 수행됩니다. 수백만 개의 플립플롭을 단일 체인으로 구성하면 테스트 시간이 기하급수적으로 늘어나므로, 실제 구현에서는 다수의 병렬 스캔 체인으로 분할합니다.
핵심은,
- SCAN Shift mode: Scan Enable이 0일때, 기본 RTL의 function mode 동작
- SCAN Capture mode: Scan Enable이 1일때, Scan In Port의 Signal이 Combinational Logic을 거치지 않고 Scan Flipflop들을 따라 Signal shifting만 되는 것입니다.
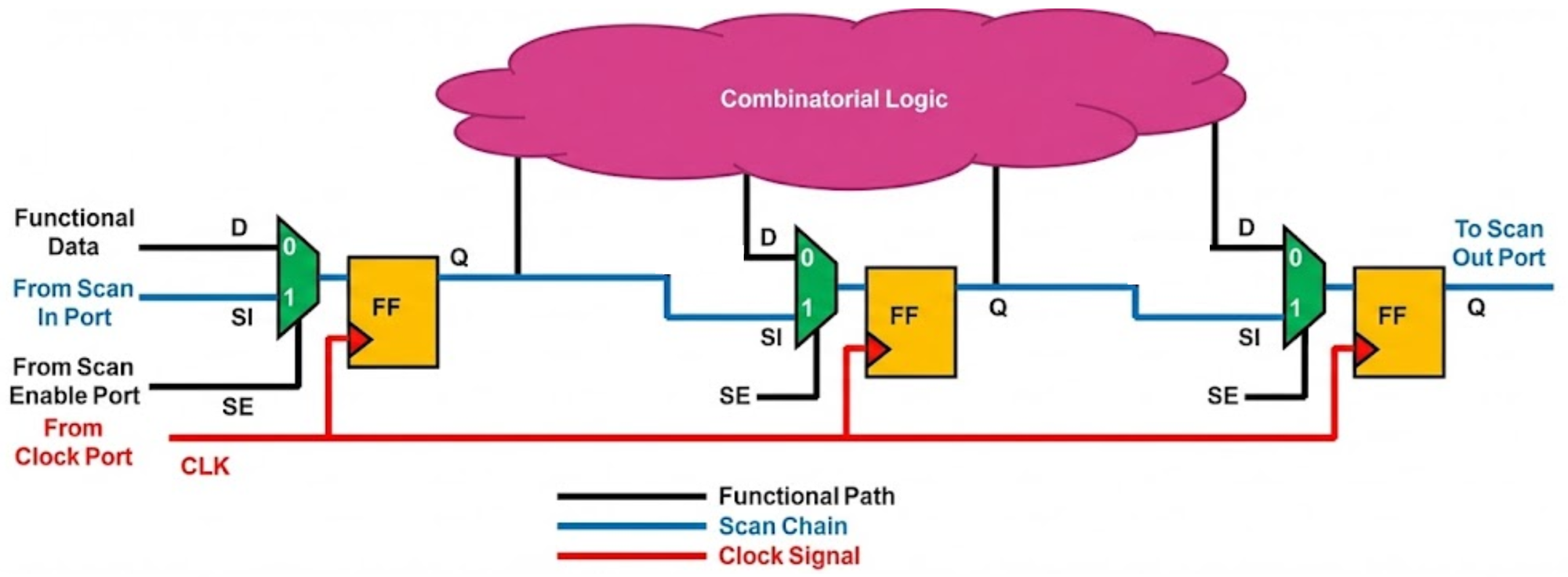
2.2.1 Scan Chain Input Output Budgetting
ATE의 메모리 효율과 테스트 시간을 최적화하기 위해서는 모든 스캔 체인의 길이를 비슷하게 맞추는 것이 중요합니다. 이를 Chain balancing이라 합니다. 예를 들어, 전체 플립플롭이 10,000개이고 100개의 스캔 채널을 사용할 수 있다면, 각 체인은 100개의 플립플롭으로 구성됩니다.
만약 체인 간 길이에 불균형이 발생하면, 가장 긴 체인의 시프트가 완료될 때까지 짧은 체인들은 대기해야 하므로 불필요한 Padding 데이터가 발생하고 테스트 시간이 낭비됩니다.
Foundry는 이러한 것들을 고려하여 Flip flop count 별 추천 SCAN I/O budgetting table을 공유합니다.
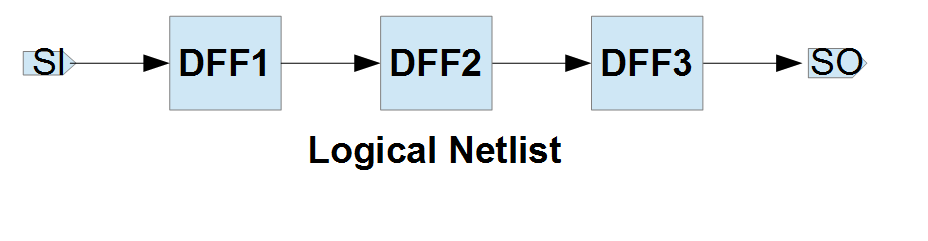
2.2.2 SCAN Chain Reordering
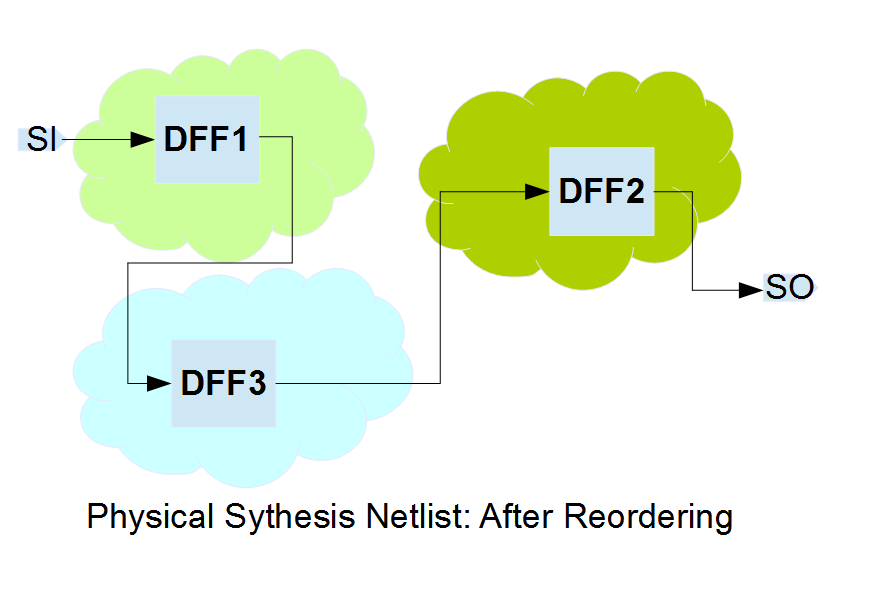
SCAN stitching 단계에서의 스캔 체인 연결은 Cell들의 기하학적 좌표를 고려하지는 않습니다. 이는 Place & Route 단계에서 심각한 Routing Congestion을 유발할 수 있습니다. 물리적으로 멀리 떨어진 셀들이 체인 상에서 인접하게 연결되면 긴 배선이 칩 전체를 가로지르게 됩니다.
After P&R:
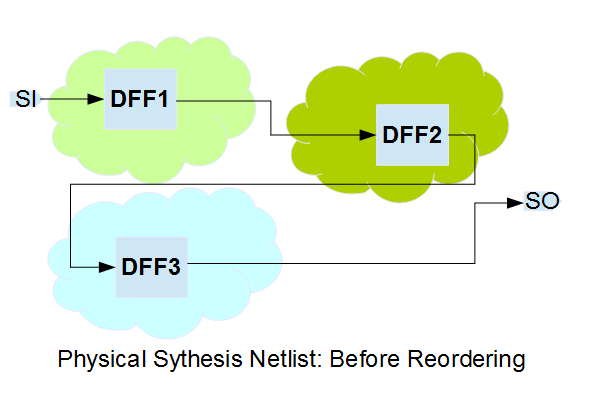
이를 해결하기 위해 P&R 도구는 Scan Reordering 기능을 수행합니다. 셀들의 물리적 배치 위치가 확정된 후, 도구는 배선 길이를 최소화하는 경로를 찾아 스캔 체인의 연결 순서를 동적으로 변경합니다. 이는 타이밍 마진 확보와 칩 면적 절감에 필수적인 과정입니다.
After Scan Reordering:
2.3 Lockup Latch: Clock Skew 관리와 Hold time violation 방지
대규모 SoC에서는 스캔 체인이 서로 다른 Clock Domain을 가로지르거나, 단일 클럭 도메인 내에서도 물리적으로 매우 먼 거리를 이동해야 하는 경우가 빈번합니다. 이때 발생하는 Clock Skew는 시프트 동작 중 치명적인 Hold 타이밍 위반을 야기할 수 있습니다.
2.3.1 Hold Violation:
- 스캔 체인 내에서 데이터를 보내는 Launch Flop의 Clock이 Capture Flop의 Clock보다 늦게 도착한다고 가정해 봅시다.
- Launch Flop이 새로운 데이터를 출력할 때 Capture Flop은 여전히 이전 데이터를 캡처하지 못한 상태일 수 있습니다.
- Hold time violation이 발생합니다.
2.3.2 락업 래치의 역할과 배치
이러한 문제를 해결하기 위해 Clock domain 바뀌는 지점이나 Skew가 큰 구간에 Lockup Latch를 삽입합니다.
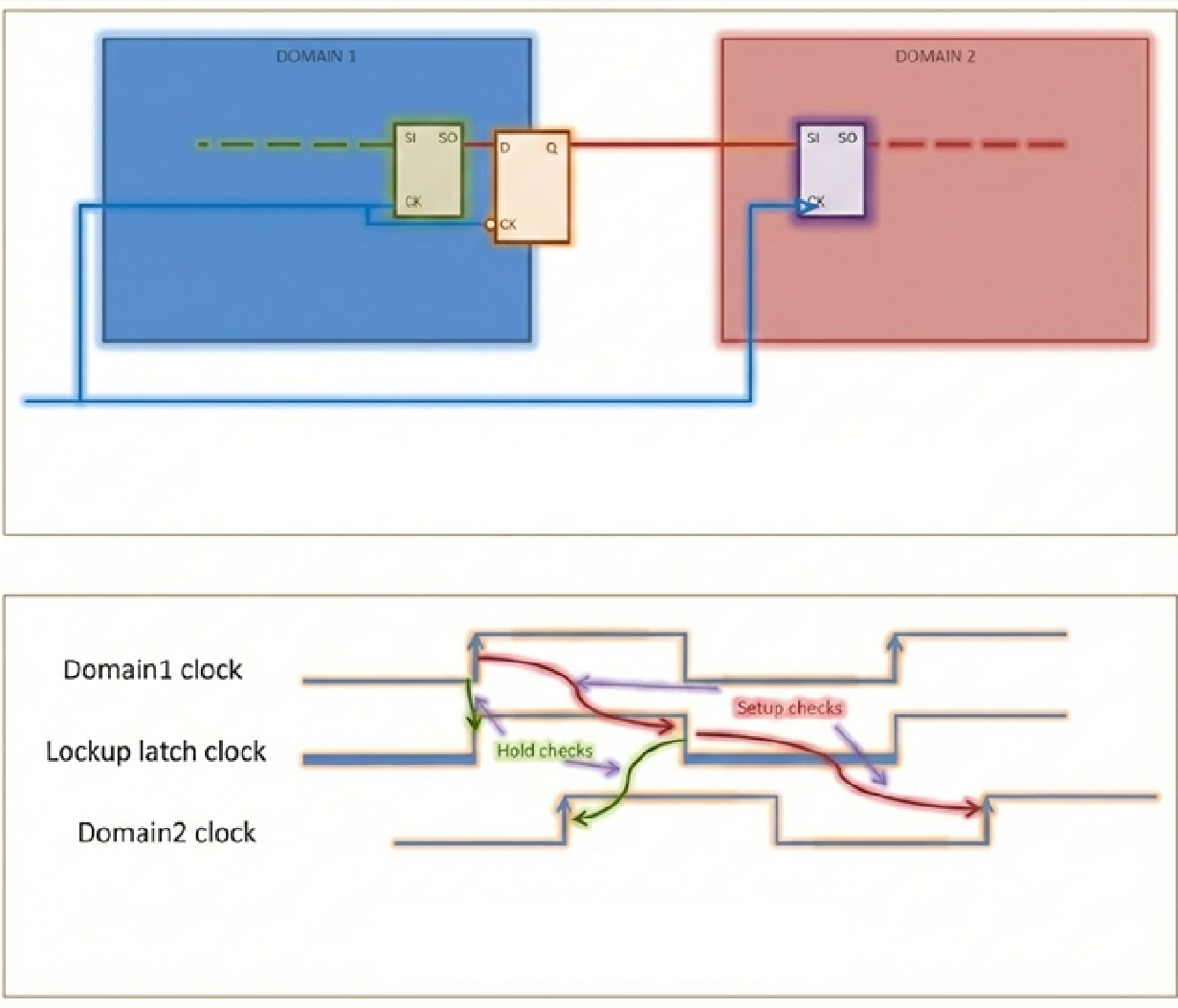
- Domain1 끝단에 Lockup latch를 넣습니다. 이 때 Lockup latch는 Flipflop과 반대 clock 에서 동작하도록 Negative Lockup latch를 넣는게 포인트입니다.
- Domain1 끝단에서 Clock Level이 0 -> 1(rising edge)일 때 Data가 Domain2로 가는게 아니라 Lockup D까지만 전파됩니다.
- Clock이 Low-level로 접어들면, Lockup latch는 그때서야 Domain2로 전파시킵니다.
그러면 Clock Period의 Half Cycle만큼 늦게 Domain2에 도달하게 됩니다.
결국 Hold Time을 만족시키기 유리해지는거죠.
3. ATPG (Automatic Test Pattern Generation): 결함 검출의 엔진
설계의 구조적인 테스트가 준비되면, 실제 결함을 검출하기 위한 "Test input pattern과 정답 Output Vector"를 출력해야합니다.
예를들면, "자판기의 콜라 버튼을 눌렀을 때, 콜라가 출력 되어야 한다. 그렇지 않으면 결함이다." 이런 것이 테스트 패턴입니다.
3.1 결함 모델(Fault Models)의 고도화
공정 기술의 발전에 따라 결함의 양상이 변화했으므로, 이를 모델링하는 방식 또한 진화해 왔습니다.
3.1.1 Stuck-at Fault
가장 고전적이고 널리 사용되는 모델입니다. Routing이 중간에 끊어지거나, 아니면 VDD에 붙어버려서 회로의 특정 노드가 논리값 '0'(Stuck-at-0) 또는 '1'(Stuck-at-1)로 영구적으로 고정된 상태를 가정합니다.
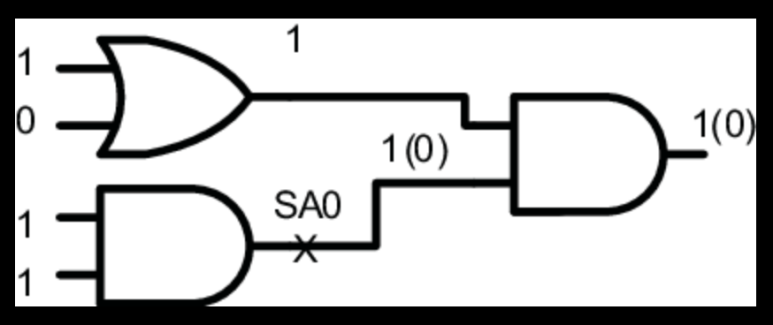
- 테스트 방식: 예를 들어 AND 게이트 출력의 Stuck-at-0 결함을 검출하려면, 출력을 '1'로 만들 수 있는 입력 패턴을 인가하고, 출력이 기대 값으로 나오는지 관측합니다.
- 한계: 저속에서 동작하는 정적(Static) 결함만을 검출할 수 있으며, 타이밍 관련 결함은 잡아낼 수 없습니다.
이런 Test pattern들을 만드는 것이 ATPG입니다.
D-Algorithm, PODEM 등 ATPG Algorithm를 찾아보시면, 디지털 공학에 되한 자료가 많이 나옵니다.
3.1.2 Transition Fault와 Delay fault
Routing이 끊어지지는 않았으나, Routing이 너무 굵게 공정이 되거나, 얇게 공정이 되면 Net의 RC 값이 변화하게 되고, 이는 속도가 달라지는 현상이 발생합니다.
- Slow-to-Rise: 0에서 1로 변하는 시간이 너무 오래 걸림.
- Slow-to-Fall: 1에서 0으로 변하는 시간이 너무 오래 걸림.
- Path Delay Fault: 개별 게이트의 지연이 아닌, 회로 내의 전체 경로(Path)의 누적 지연을 테스트합니다.
3.2 At-Speed Test와 Clocking
지연 결함을 검출하기 위해서는 칩을 실제 Chip function frequency로 구동하는 At-Speed 테스트가 필수적입니다. 그런데 외부에서 인가 가능한 Clock frequency는 매우 느린 Clock만 가능합니다.
이를 위해서는 On Chip Clock Controller 같은 IP가 필요합니다.
3.3 Test Compression
Chip size가 커지면서 스캔 체인이 길어지고, At-Speed 테스트를 위한 패턴 수가 증가함에 따라 테스트 데이터의 Volume과 Test Time이 폭증하는 문제가 발생했습니다. 이를 해결하기 위해 스캔 압축 기술이 도입되었습니다.
3.3.1 Compressor, MISR와 Embedded Deterministic Test
Compressor는 Synopsys의 기술, EDT는 Mentor(현 지멘스 EDA)에 의해 대중화된 기술로, 칩 내부에 하드웨어 로직을 추가하여 압축을 수행합니다.
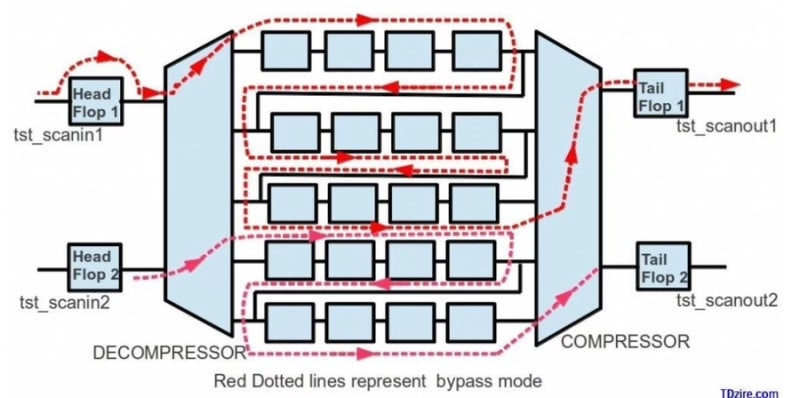
- Decompressor: Chip의 입력단에 위치하며, ATE로부터 적은 수의 채널로 압축된 데이터를 받아 칩 내부의 수많은 짧은 스캔 체인으로 Broadcasting합니다. Ring Generator와 Phase Shifter를 사용하여 상관관계가 낮은 난수 패턴을 공급합니다.
- Compactor: 스캔 체인의 출력단에 위치하며, 수많은 내부 체인의 결과를 XOR 트리나 Spatial Compactor를 통해 소수의 채널로 압축하여 ATE로 보냅니다.
- X-Masking: 압축 과정에서 초기화되지 않은 값(Unknown 'X')이 압축된 Signature을 오염시키는 것을 막기 위해, X 값을 마스킹하는 로직이 필수적으로 포함됩니다.
- MISR: 출력을 매 사이클 비교하는 대신 Multiple Input Signature Register를 사용하여 전체 패턴의 결과를 하나의 Signature으로 축적한 후, 테스트의 마지막에 한 번만 비교하는 방식입니다.
SCAN은 보다시피, 설계 영역입니다. ATPG는 Tape-out 후에도 할 수 있는 테스트 영역입니다.
그리고 보시다시피, Chip은 사실 Chip 목적에 맞는 동작이 중요한데, 테스트에 엄청난 비용(설계도 복잡하고, Test를 위해 추가적인 Area와 Port)이 들어갑니다.
예를들어, SCAN Shift는 엄청나게 높은 Signal switching activity를 발생시키고, 이는 엄청나게 큰 Power 소모, 발열이 발생하며, HCI, BTI, IR, EM까지 발생하게 됩니다. 그래서 DFT 분야도 꽤 연구 주제가 다양한 분야입니다.
4. MBIST (Memory Built-In Self-Test)
현대 SoC 면적의 절반 가까이 차지하는 메모리는 로직보다 트랜지스터 밀도가 훨씬 높아 제조 결함에 더욱 취약합니다.
스캔 테스트는 플립플롭과 로직 게이트를 테스트하는 데 최적화되어 있어, 메모리 셀 내부의 미세한 용량성 결함이나 인접 셀 간의 간섭을 검출하기에는 부적합합니다. 따라서 메모리 전용 테스트 엔진인 MBIST가 필수적으로 사용됩니다.
4.1 March 알고리즘
MBIST 컨트롤러는 칩 내부에 내장되어, 외부 장비의 도움 없이 스스로 메모리에 데이터를 쓰고 읽으며 동작을 검증합니다. 이때 사용되는 표준 알고리즘이 March 알고리즘입니다. March 알고리즘은 메모리 주소 공간을 순차적으로 Marching하며 일련의 읽기/쓰기 동작을 수행합니다.
4.2 Built-In Self-Repair, BISR
메모리는 수율 저하의 주범이므로, 결함이 발견되었다고 해서 칩 전체를 버리는 것은 경제적으로 큰 손실입니다. 이를 방지하기 위해 BISR 기술이 적용됩니다.
- Redundancy: 메모리 설계 시 Redundancy의 Row과 Column을 미리 배치합니다.
- Repair Process: MBIST 테스트 도중 결함 셀이 발견되면, 컨트롤러는 해당 주소 정보를 저장합니다. 테스트가 끝난 후, 이 정보는 칩 내부의 eFuse(Electrical Fuse)에 영구적으로 기록됩니다.
- Remapping: Chip이 booting될 때, HW Logic이 퓨즈 정보를 읽어 결함이 있는 주소를 여분의 행/열로 물리적으로 Remapping합니다. 이 과정은 사용자에게는 보이지 않으며, 칩은 결함이 없는 것처럼 정상 동작하게 됩니다.
5. LBIST (Logic Built-In Self-Test)
LBIST는 로직 회로를 스스로 테스트하는 기술로, ATE 없이 칩 자체적으로 결함을 검출할 수 있게 합니다. 이는 칩 제조 단계뿐만 아니라, 자동차의 시동을 걸 때(Power-On Self-Test)나 동작 중(Run-Time Test)에 칩의 무결성을 확인해야 하는 ISO 26262 기능 안전 규격 준수에 핵심적인 역할을 합니다.
5.1 STUMPS 아키텍처와 구성 요소
LBIST는 STUMPS (Self-Test Using MISR and Parallel Shift register sequence generator) 아키텍처를 기반으로 구현됩니다.
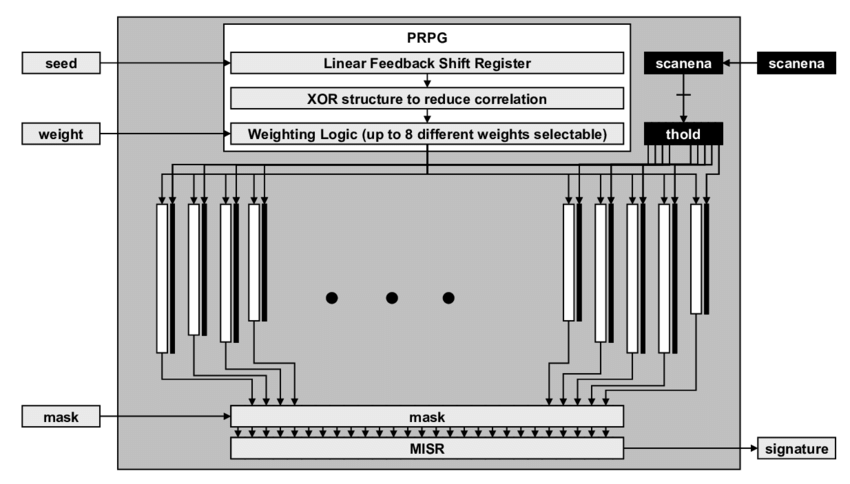
- PRPG (Pseudo-Random Pattern Generator): ATPG처럼 저장된 패턴을 사용하는 대신, LFSR (Linear Feedback Shift Register)을 사용하여 매 사이클 Pseudo-random 패턴을 생성합니다. 이는 별도의 메모리 없이 매우 큰 패턴을 생성할 수 있게 합니다.
- Phase Shifter: LFSR의 출력은 Structural Dependency를 가질 수 있습니다. 위상 시프터는 XOR 네트워크를 통해 이를 섞어주어, 인접한 스캔 체인에 들어가는 데이터의 상관성을 제거하고 패턴의 무작위성을 높입니다.
- MISR (Multiple Input Signature Register): 수천 개의 스캔 체인에서 나오는 출력 결과를 저장할 수 없으므로, 이를 압축하여 고정된 길이의 Signature로 변환합니다. 다항식 나눗셈 연산을 수행하는 LFSR의 역구조와 유사합니다.
- BIST Controller: 테스트의 시작, 정지, 패턴 수, 클럭 속도 등을 제어하는 상태 머신입니다.
5.2 Golden Signature와 X-Pounding 문제
LBIST의 검증은 테스트 완료 후 생성된 최종 서명을, 시뮬레이션을 통해 미리 계산된 Golden Signature와 비교하는 방식으로 이루어집니다. 두 값이 일치하면 Pass, 하나라도 다르면 Fail입니다.
이 과정에서 가장 큰 난관은 'X' (Unknown) 값의 처리입니다. 회로 내에 초기화되지 않은 메모리, 아날로그 블록의 출력, 플로팅 노드 등이 존재하면 시뮬레이션에서는 'X'로 나타납니다.
ATPG에서는 이를 무시할 수 있지만, LBIST의 MISR는 이 'X' 값이 들어오는 순간 전체 Signature를 Corruption시켜 예측 불가능한 값으로 만들어 버립니다. 이를 막기 위해 설계 단계에서 'X' 발생 원인을 제거하거나, X-Blocking 로직을 추가하여 MISR로 들어가는 경로를 차단해야 합니다.
6. 표준 인터페이스: 칩과 외부 세계의 연결
SoC는 수많은 IP 코어(CPU, GPU, DSP, Memory Controller 등)로 구성된 복잡한 시스템입니다. 이들을 개별적으로 제어하고 테스트하기 위해 국제적으로 표준화된 인터페이스가 사용됩니다.
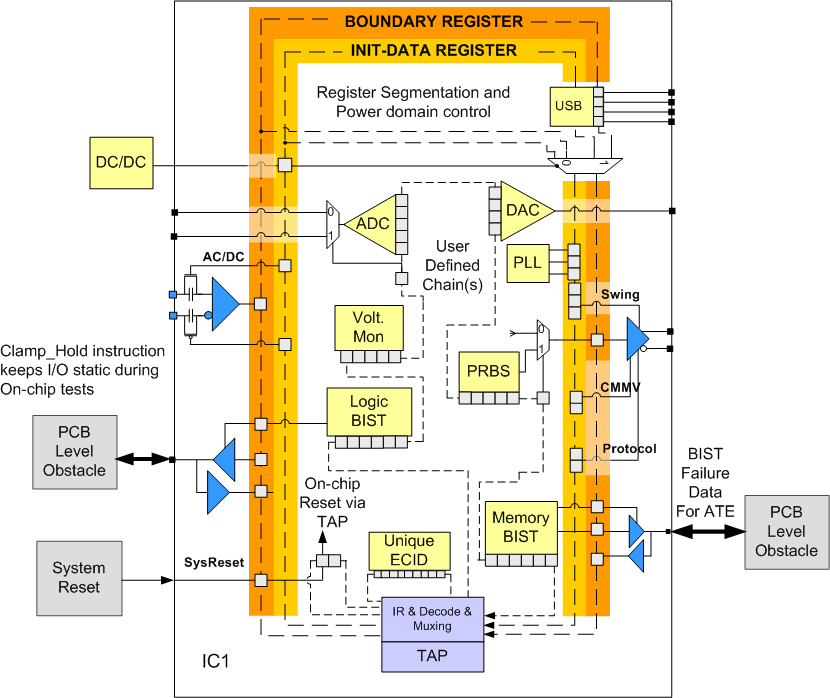
IEEE1149, 1500, 1687까지 자주 사용하고, 3D-IC 시대에는 1838도 많이 사용하게 될 것 같습니다.
결론: DFT 기술의 미래 전망
지금까지 살펴본 바와 같이, DFT는 반도체 설계의 단순한 부가 기능이 아니라 칩의 수율, 비용, 품질, 안전을 책임지는 핵심 아키텍처입니다.
향후 DFT 기술은 다음과 같은 방향으로 진화할 것으로 전망됩니다.
- AI 기반 DFT & ATPG
- 3D-IC, HBM 및 칩렛 테스트
- 고속 I/O Loopback test:
결론적으로, 공정이 미세화되고 칩이 복잡해질수록 DFT의 중요성은 더욱 커질 것이며, 설계 초기 단계부터 DFT를 고려하는 'DFT-First' 방법론이 반도체 성공의 필수 조건이 될 것입니다.