현대 반도체 설계, 특히 ASIC(Application Specific Integrated Circuit) 설계 흐름에서 Logic Synthesis는 추상적인 인간의 논리(RTL 혹은 HDL)를 물리적인 실리콘의 현실(Gate-level Netlist)로 구체화하는 가장 결정적인 변환 과정입니다.
요약하면,
Logic Synthesis는 RTL을 입력 받고, Gate Level Netlist를 출력하는 것.
- RTL에는 Physical은 고려되지 않고 논리 구조만 들어있는 설계도입니다.
- Netlist는 Foundry에서 제공한 Cell library를 기반으로, Pysical 정보와 Logical 정보가 포함된 설계도입니다. (좌표 값 같은건 안 들어있음.)
- 이후 P&R, ECO 등 단계에서는 Logic synthesis에서 만들어진 회로에 좌표를 입력하여 배치하고, 연결하고, 셀 타입 약간 바꾸는 정도 수정.
- Synthesis에서 나온 PPA에 대해, 이것보다 더 높은 PPA를 달성하고싶어도 P&R에서 더 높이기가 쉽지 않음.
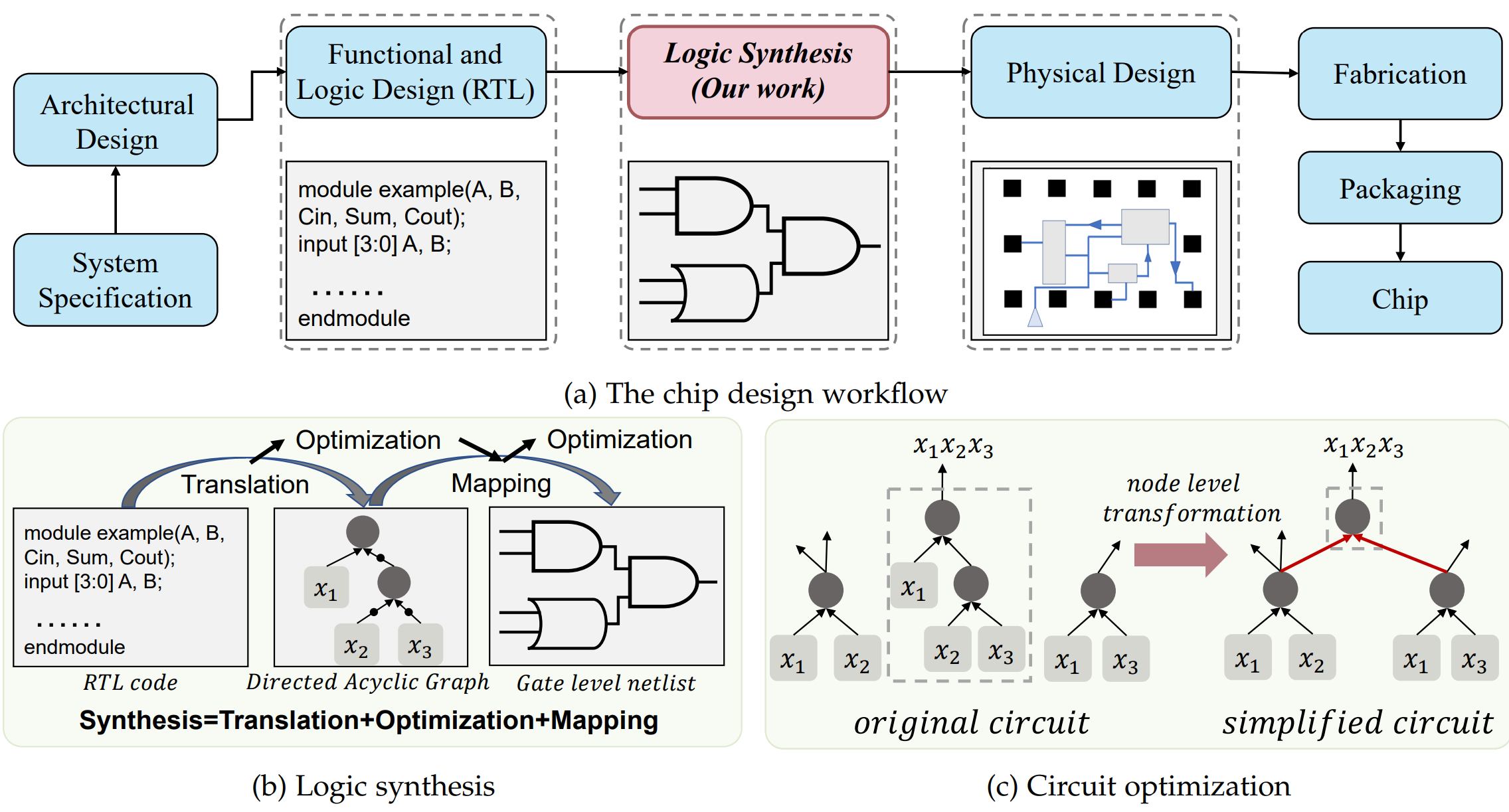
RTL에서 GDSII로 이어지는 전체 흐름에서 합성이 차지하는 비중은 절대적이다.
이 단계에서 결정된 PPA(Power, Performance, Area)의 초기 지표는 이후 Place and Route 단계의 Convergence을 좌우한다. 만약 합성 단계에서 잘못된 Constraints가 설정되거나 물리적 현실을 반영하지 못한 구조가 생성된다면, Back-end design 과정에서 엄청나게 많은 야근을 요구하게 된다.
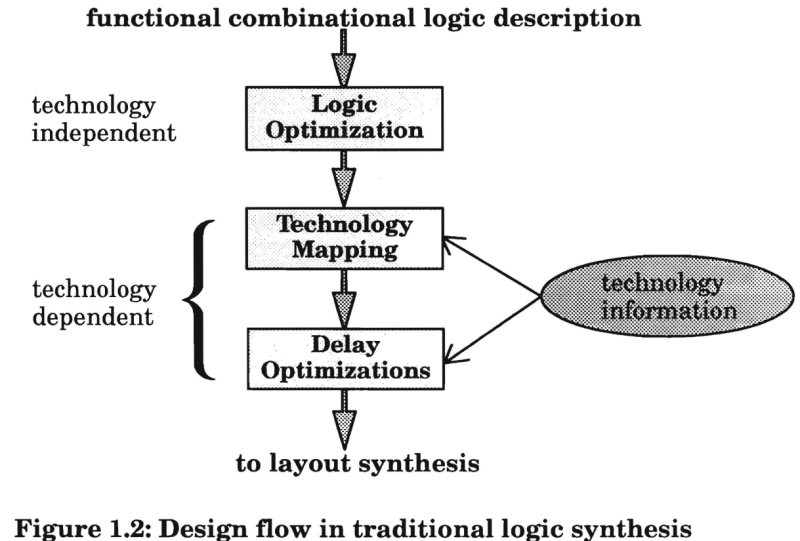
1. 변환의 수학: 추상화 레벨의 하강과 최적화의 서막
로직 합성은 본질적으로 Functional Equivalence을 유지하면서 Implementation Cost을 최소화하는 다차원 최적화 문제를 푸는 과정이다. RTL 코드는 인간이 이해하기 쉬운 상위 레벨의 추상화이다.
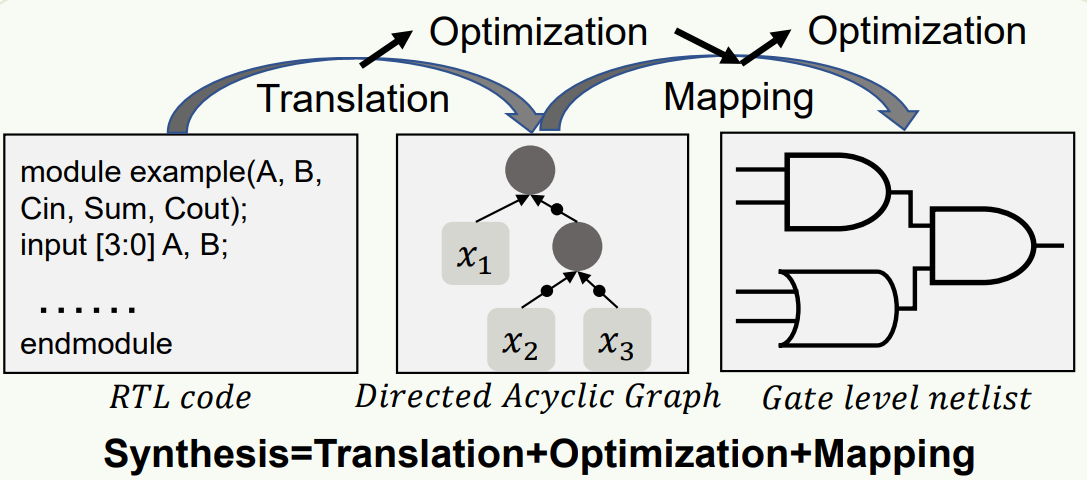
Logic synthesis는 3단계로 구성된다.
- Translation (or Elaboration)
- Optimization
- Mapping
1.1 파싱과 정교화 (Parsing & Elaboration): GTECH의 세계
합성의 첫 단계는 HDL(Verilog/VHDL) 텍스트를 툴이 이해할 수 있는 내부 데이터베이스 구조로 변환하는 것이다. 이 과정을 Elaboration라고 하며, 여기서 생성되는 초기 넷리스트는 특정 공정 기술에 종속되지 않은 GTECH(Generic Technology) 라이브러리를 사용한다.
- Parsing & Inference:
- 툴은 코드의 문법적 오류를 검사하고,
always블록이나assign문을 해석한다. 이 단계에서 가장 중요한 것은 Hardware Inference이다. - 예를 들어,
if-else구문은 멀티플렉서(MUX)로,posedge clk구문은 플립플롭(Flip-flop)으로 변환된다.
- 툴은 코드의 문법적 오류를 검사하고,
- Architectural Selection:
- RTL에서
+,*와 같은 산술 연산자는 추상적인 개념이다. Elaboration 단계에서 툴은 이 연산자들을 구현하기 위한 초기 아키텍처를 결정한다.
- RTL에서
- 예를 들어, 덧셈기를 구현할 때 면적이 작지만 속도가 느린 Ripple Carry 방식을 사용할지, 아니면 면적을 희생하더라도 고속 동작이 가능한 Carry Look-ahead 방식을 사용할지를 고민한다.
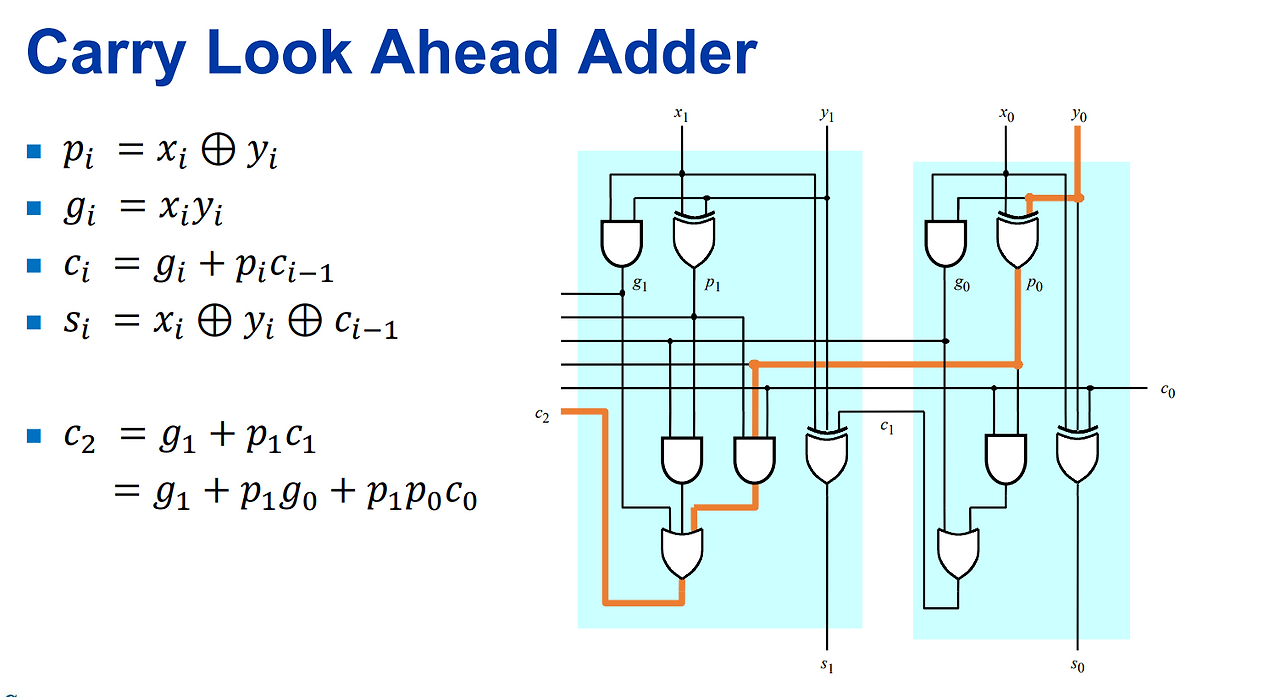
1.2 Technology Independent Optimization
GTECH 상태의 넷리스트는 Boolean Algebra의 원리를 적용하여 논리적으로 단순화된다. 이 단계는 Standard Cell와 무관하게 진행되므로 'Technology Independent'라고 불린다.
1.2.1 Boolean optimization과 Redundancy Removal
가장 기본적인 최적화는 불필요한 논리를 제거하는 것이다. 예를 들어 A & 1은 A로, A | 0은 A로 축소된다. 더 복잡하게는 회로 내부에 존재하지만 출력에 영향을 주지 않는 Redundant 연결을 찾아내어 제거하거나 상수로 대체한다.
이는 K-Map의 원리를 알고리즘적으로 확장한 것으로, 대규모 회로에서는 Espresso Algorithm과 같은 휴리스틱 방법이 사용된다.
1.2.2 Common Subexpression Elimination
툴은 Data Flow Graph를 분석하여 중복되는 연산을 찾아낸다.
F = (A * B) + C와 G = (A * B) + D가 존재할 때,
(A * B)라는 항을 별도로 계산하지 않고 한 번만 계산한 후 그 결과를 공유하도록 구조를 변경한다. 이를 통해 게이트 수를 줄이고 면적을 최적화할 수 있다.
1.2.3 AIG(And-Inverter Graph) 기반 최적화
현대의 합성 툴(특히 ABC, Genus)은 로직을 표현하기 위해 AIG(And-Inverter Graph) 구조를 적극적으로 활용한다.
AIG는 모든 논리 회로를 2-input AND 게이트와 Inverter만으로 표현하는 DAG이다. 기존의 BDD(Binary Decision Diagram)가 변수 순서에 따라 메모리 사용량이 폭발적으로 증가하는 단점이 있는 반면, AIG는 구조적으로 리소스 효율적이다.
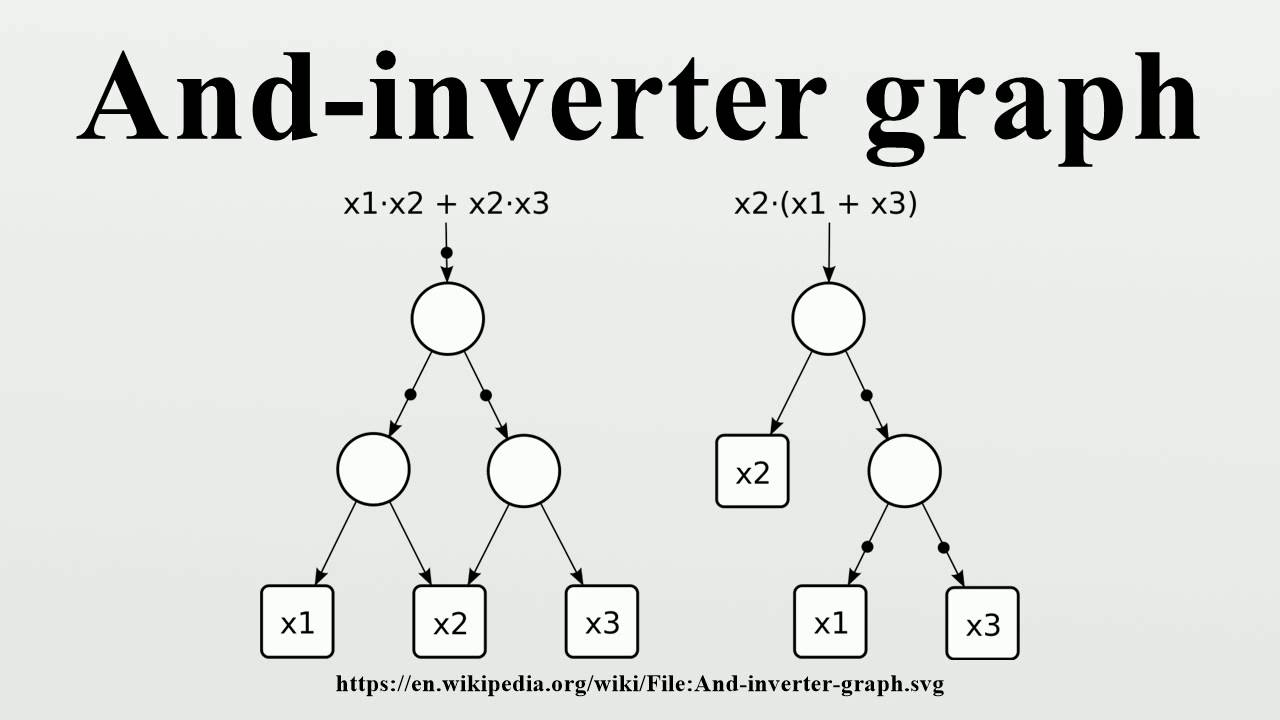
- Structural Hashing: AIG 생성 시 동일한 입력과 기능을 가진 노드가 중복 생성되지 않도록 하여 메모리를 절약하고 자연스러운 로직 공유를 유도한다.
- AIG Rewriting: AIG의 Subgrap를 추출하여 더 적은 노드를 사용하는 기능적으로 등가인 다른 구조로 대체하는 기법이다. 이는 국소적인 최적화를 반복하여 전체 그래프의 크기를 줄이는 강력한 방법이다.
2.Design Constraints (Synopsys Design Constraints, SDC)의 원리와 물리적 해석
"Garbage In, Garbage Out." EDA에서 가장 중요한 격언이다. 아무리 효율적인 최적화 엔진을 갖춘 툴이라도, 설계자가 제시하는 목표치인 Constraints이 부정확하면 엉뚱한 결과물을 내놓는다.
SDC(Synopsys Design Constraints)는 단순한 설정 파일이 아니라, 툴에게 Design Intent와 Physical Environment을 설명하는 표준 언어이다.
2.1 Clock의 정의와 모델링: 시간의 기준점
모든 동기식 디지털 회로의 기준은 클럭이다. create_clock 명령어는 Clock Frequency, Duty Cycle, Phase을 정의한다. 하지만 합성 단계에서의 클럭은 실제 물리적인 클럭 트리Clock Tree가 형성되기 전이므로 'Ideal'인 상태로 가정된다.
2.1.1 Clock Uncertainty의 필수성
Ideal Clock은 Skew나 Jitter가 없는 완벽한 구형파이지만, 실제 실리콘 환경은 그렇지 않다. 따라서 set_clock_uncertainty 명령어를 통해 레이아웃 이후 발생할 수 있는 변동성을 미리 마진(Margin)으로 확보해야 한다.
- Setup Uncertainty: 클럭 지터(Jitter) + 예상되는 클럭 스큐(Skew)의 합으로 설정한다. 이는 타이밍 분석 시 유효한 클럭 주기를 줄여서(Pessimistic) 툴이 더 타이트하게 최적화하도록 유도한다.
- Hold Uncertainty: Hold는 대개 0-cycle check이기 때문에 위상차를 고려할 필요가 없다. 주로 예상되는 클럭 스큐만 반영한다. 이는 데이터가 너무 빨리 도착하여 발생하는 위반을 막기 위한 마진으로 작용한다.
2.1.2 Virtual Clock과 I/O 제약
Chip의 Primary Ports에 대한 타이밍을 제약할 때, 외부 장치의 클럭을 모델링하기 위해 Virtual Clock을 사용한다. 가상 클럭은 칩 내부의 어떤 핀에도 물리적으로 연결되지 않지만, set_input_delay나 set_output_delay의 기준이 되는 레퍼런스 역할을 한다.
2.2 I/O Time Budgeting
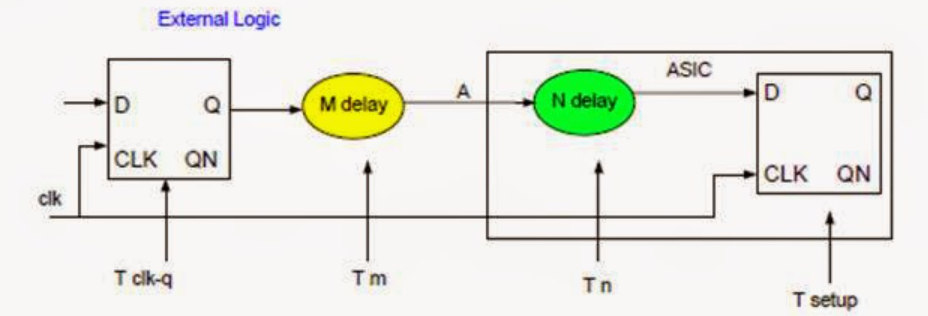
set_input_delay와 set_output_delay는 툴에게 "칩 외부에서 이미 사용된(또는 사용될) 시간"을 알려주는 명령어이다. 툴은 이 값을 전체 클럭 주기에서 뺌으로써, 칩 내부 로직이 사용할 수 있는 Time Budget을 계산한다.
- Set Input Delay: 데이터가 current_design 외부의 Timing startpoint에서 출발하여 current_design의 입력 핀에 도달하기까지 걸리는 시간이다.
- Set Output Delay: 우리 current_design의 출력 핀에서 데이터가 나가서 current_design의 Timing endpoint에 도착할 때 필요한 시간이다.
- 해석: 툴은 데이터가 출력 핀에 도달하는 시간이
Clock Period - Output Delay보다 작도록 High Drive Strength Cell을 배치하거나 Logic Depth를 줄이는 최적화를 수행한다.
- 해석: 툴은 데이터가 출력 핀에 도달하는 시간이
2.3 Timing Exceptions
모든 경로가 1-Cycle, 0-cycle 내에 동작해야 하는 것은 아니다. 예외 경로를 정확히 명시하지 않으면, 툴은 불필요한 경로를 최적화하느라 면적과 전력을 낭비하거나 정작 중요한 경로의 최적화를 놓치게 된다.
중요한 것은, 이 방법들은 "내가 Timing check에 더 여유를 줘서 볼게"이기 떄문에 매우 조심히 사용해야한다는 것이다. 이걸 안 넣고 Timing closure 할 수 있으면, 안 넣는 것이 안전하다.
2.3.1 False Path: 최적화 포기 선언
set_false_path는 논리적으로 도달 불가능하거나 타이밍이 중요하지 않은 경로를 지정한다.
2.3.2 Multicycle Path: 시간의 확장
set_multicycle_path는 곱셈기나 복잡한 산술 연산과 같이 1사이클 내에 완료하기 어려운 경로에 대해 N 사이클의 시간을 부여하는 명령어이다.
3. 최적화: Cost Function과 PPA 트레이드오프
합성 툴은 마법 상자가 아니다. 그것은 수많은 제약 조건들 사이에서 Cost Function를 최소화하는 해를 찾는 거대한 수학적 엔진이다. 이 비용 함수는 Performance, Area, Power이라는 서로 상충하는 요소들의 가중치 합으로 표현된다.
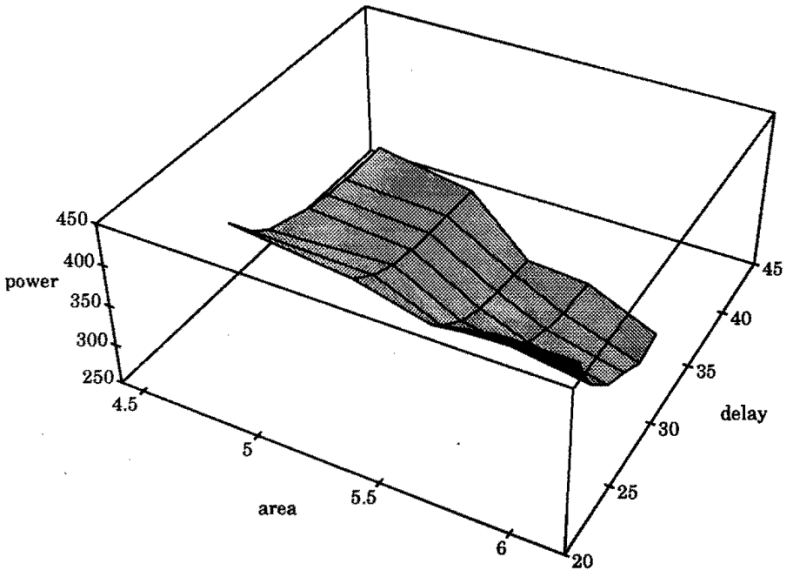
예를들어,
- Frequency를 높이면 칩은 빨리 동작한다. 대신에 switching activity가 늘어나니까 Power가 늘어난다.
- 로직을 병렬화하면 Chip의 대역폭은 높아진다. 대신에 Chip area는 더 커진다.
과거에는 Wafer 안에 얼마나 더 많은 chip을 넣는가 (싸게 양산이 가능한가?)가 중요한 지표였다.
현대에는 얼마나 더 대역폭을 더 키울 수 있는가, 수율을 얼마나 높일 수 있는가가 핵심이다.
3.1 최적화의 절대적 우선순위 (Optimization Priority)
툴은 모든 제약 조건을 동시에 만족시킬 수 없을 때, 다음과 같은 엄격한 우선순위에 따라 동작한다. 이 순서를 이해하는 것은 합성 결과를 분석하고 제약 조건을 튜닝하는 데 필수적이다.
- Design Rule Constraints (DRC): Logic Synthesis에 사용되는 Library는 아래 3가지 기준을 놓고 Library characterization을 한다. 이 값을 넘어가는 경우에는 Foundry가 특성화를 하지 않은 부분이기 때문에 부정확한 결과를 초래한다.
- Min/Max Transition
- Min/Max Capacitance
- Max Fanout
- Timing Constraints (Setup Time): 성능의 핵심
- WNS (Worst Negative Slack): 가장 위반이 심한 경로(Critical Path) 의 슬랙 값이다.
- TNS (Total Negative Slack): 모든 위반 경로 슬랙의 합이다.
- Hold Time Constraints (Min Delay):
- Logic Synthesis 단계에서는 Clock tree가 이상적이므로 Hold 위반을 완벽히 잡는 것은 불가능하고 비효율적이다.
- 과거에는 Wire Load Model이라고 해서, Gate count에 따라 Wire delay를 주는 방법으로 사용했는데, 현대에는 Clock Period에 60%를 곱해서, 40%는 Setup margin으로 주고, P&R 단계에는 Hold time closure에 집중하도록 한다.
- Power & Area Optimization (Area Recovery):
- 위의 조건들을 만족한 상태에서, 타이밍 여유(Positive Slack)가 있는 경로의 게이트 사이즈를 줄이거나(Down-sizing), 전력 소모가 적은 High-Vt 셀로 교체(LVT → HVT)하여 누설 전력(Leakage Power)과 면적을 줄인다. 이를 Area Recovery라고 한다.
3.2 Boundary Optimization와 계층 구조
합성 툴은 기본적으로 모듈 단위로 최적화를 수행하지만, compile_ultra와 같은 고급 명령어를 사용하면 모듈 간의 경계를 넘나드는 최적화를 수행한다.
- Logic Synthesis의 input인 Verilog에는 다양한 *.v 파일이 있을 것이다.
- 기본적으로 Synthesis tool은 각 *.v 파일을 순회하면서, 각각의 Optimization을 한다.
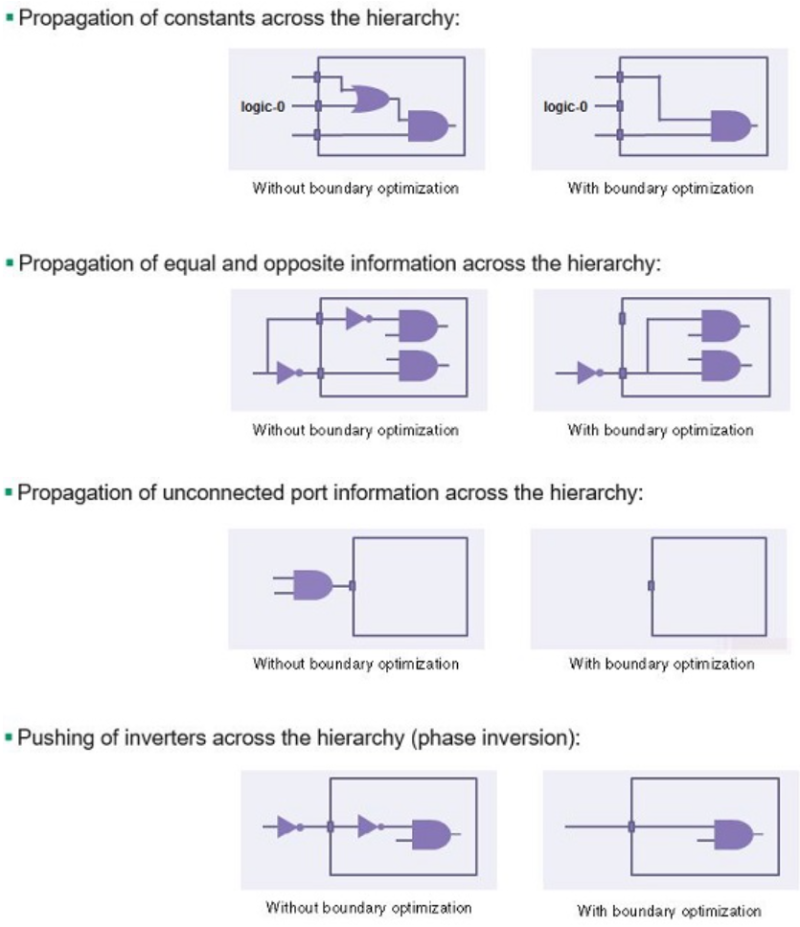
- 고급 Synthesis tool들은 모든 *.v를 위에서 한번에 보고, *.v 간 경계를 Optimization하는데, 이를 Boundary Optimization라고 한다.
- Constant Propagation: 상위 모듈에서 하위 모듈의 특정 입력 핀을
0이나1로 고정했다면, 툴은 하위 모듈 내부로 들어가 해당 신호와 관련된 로직을 모두 제거한다. 이는 불필요한 게이트를 줄이는 매우 효과적인 방법이다. - Hierarchical Pin Inversion: 타이밍 개선을 위해 인버터를 모듈 경계 안팎으로 이동시킨다. 경우에 따라서는 모듈 입력 핀의 위상을 반전시키고(Invert), 내부 로직을 드모르간의 법칙에 따라 수정함으로써 더 효율적인 매핑을 유도한다.
- Feedthrough 최적화: 모듈을 단순히 통과만 하는 신호가 있다면, 이를 감지하여 우회 경로를 생성하거나 포트를 제거하여 라우팅 혼잡도를 줄인다.
- Constant Propagation: 상위 모듈에서 하위 모듈의 특정 입력 핀을
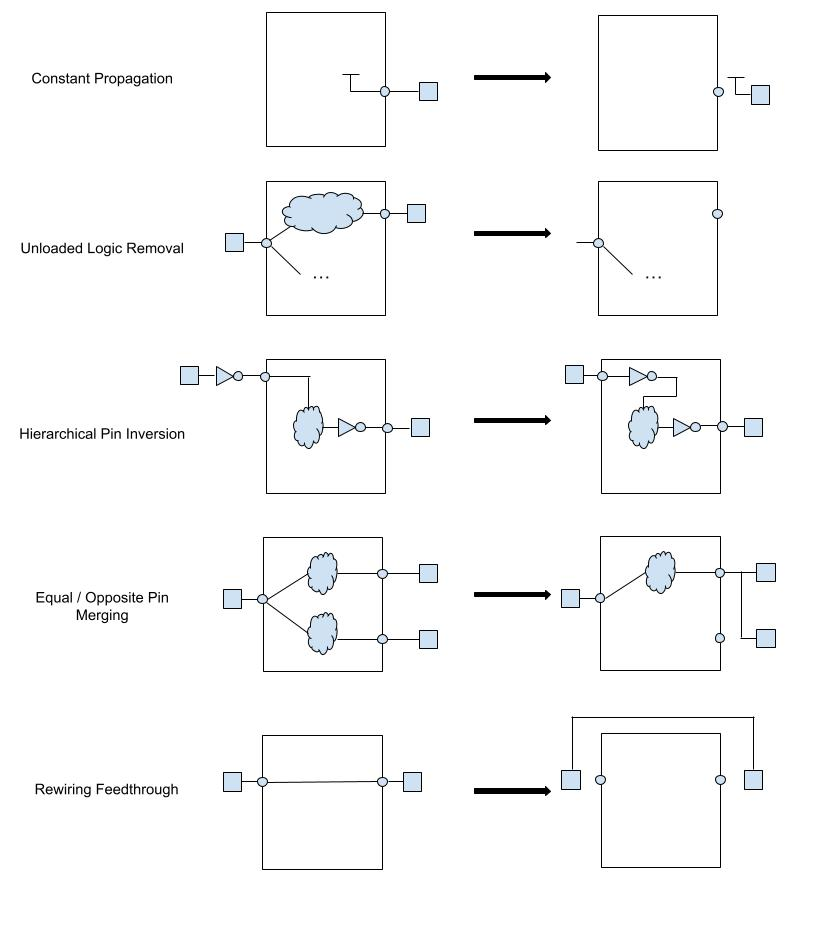
3.3 고급 최적화 기법: 리타이밍과 리소스 공유
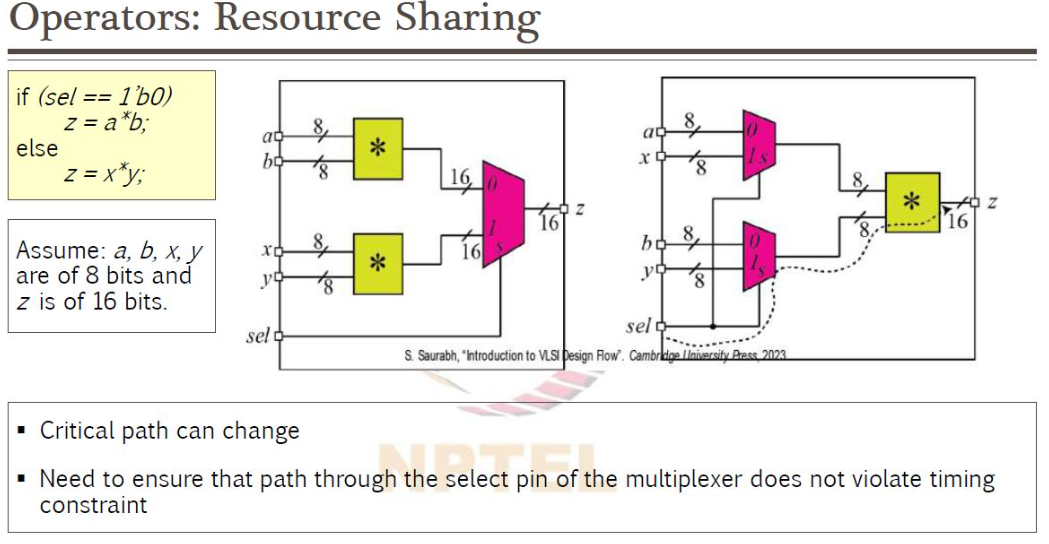
- Resource Sharing: 서로 다른 시간(예: MUX에 의해 선택되는 조건)에 동작하는 고비용 연산자(Multiplier, Adder)가 있다면, 이를 두 개 만드는 대신 하나만 만들고 MUX를 앞단에 배치하여 공유하도록 한다. 이는 면적을 획기적으로 줄이지만, 데이터 경로 앞단에 로직이 추가되어 타이밍이 악화될 수 있는 트레이드오프가 있다.
- Retiming: 파이프라인 레지스터의 위치를 조합 논리 사이로 이동시켜 경로 간의 딜레이 균형을 맞추는 기법이다. 예를 들어, 긴 조합 논리 뒤에 레지스터가 있고 그 다음 짧은 조합 논리가 있다면, 레지스터를 앞으로 이동시켜 클럭 주파수를 높일 수 있다.
optimize_registers나compile_ultra -retime옵션을 통해 활성화된다.
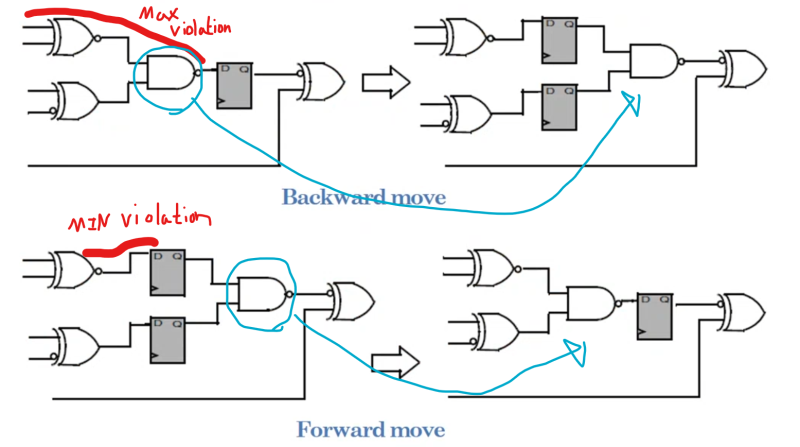
4.Technology Mapping의 미시적 원리
RTL 설계자가 작성한 assign y = a & b; 코드가 실제 실리콘 위의 NAND 게이트와 INV 게이트 조합으로 변환되는 과정은 단순한 1:1 치환이 아니다. 이는 Graph Covering이라는 고도의 알고리즘 문제를 해결하는 과정이다.
4.1 Boolean Matching
툴은 최적화된 Boolean Network를 Subject Graph라고 불리는 그래프 형태로 변환한다. 동시에 .lib에 있는 Standard Cell들을 각각의 기능을 나타내는 Pattern Graph로 변환한다. 기술 매핑은 Subject Graph를 Pattern Graph들로 빈틈없이 Covering 과정이다.
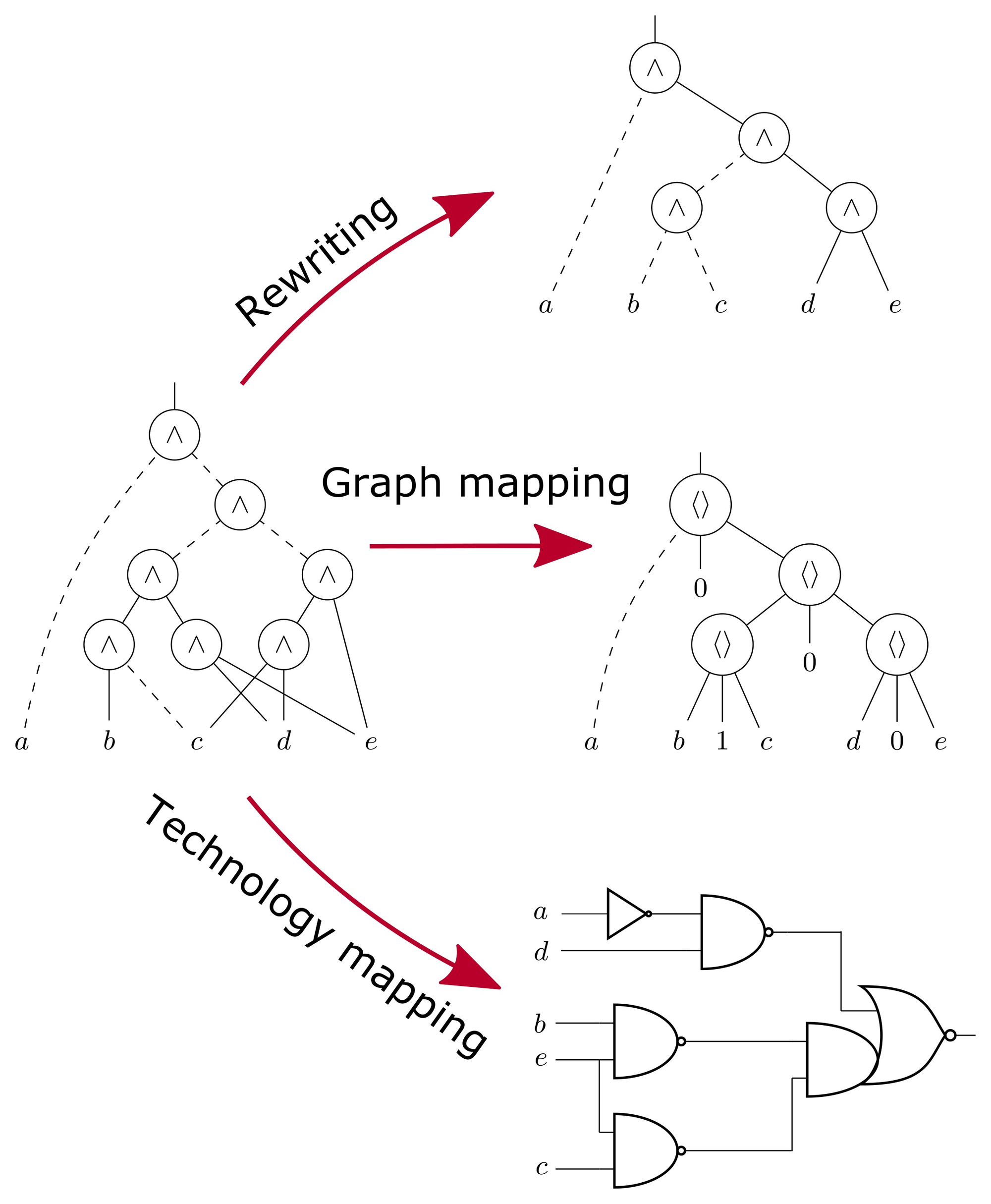
- Cut Enumeration: 그래프의 특정 노드에서 입력을 끊어(Cut) 만들 수 있는 모든 Sub-graph를 찾는다. 예를 들어, 4개의 입력을 가진 어떤 로직 덩어리를 찾아서 이를 하나의 셀로 매핑할 수 있는지 탐색한다. 이는 FPGA 합성의 LUT 매핑과 유사한 원리이다.
- Cost-based Selection: 하나의 로직을 구현하는 방법은 수없이 많다.
(A+B)를 구현하기 위해OR게이트 하나를 쓸 수도 있고,NOR게이트와INV를 쓸 수도 있다. 툴은 각 패턴 그래프(Standard Cell)가 가진 고유의 비용(PPA)을 계산하고, Dynamic Programming을 사용하여 전체 그래프를 덮는 데 필요한 총 비용이 최소가 되는 조합을 찾아낸다.
4.2 Delay Models의 진화
매핑 단계에서 비용을 정확히 계산하려면 정밀한 딜레이 예측이 필수적이다.
- NLDM (Non-Linear Delay Model): 전통적인 방식으로, Input Transition Time과 Output Load Capacitance를 축으로 하는 2차원 룩업 테이블(Look-up Table)을 사용하여 딜레이를 계산한다. 90nm 이상의 공정에서는 충분했으나, 그 이하에서는 정확도가 떨어진다.
- CCS (Composite Current Source) / ECSM: 최신 미세 공정에서는 트랜지스터의 동작을 Current Source으로 모델링하여 비선형성, Miller Effect, 낮은 전압에서의 동작 특성을 정밀하게 반영한다. 현재 대부분의 28nm 이하 공정 합성은 CCS/ECSM 모델을 기반으로 수행된다.
5. 물리적 인식 합성 (Physical Aware Synthesis): 미세 공정의 필수 조건
과거 180nm, 130nm 공정 시절에는 로직 합성이 물리적 배치(Layout) 정보를 몰라도 큰 문제가 없었다. Interconnect의 지연 시간이 게이트 지연 시간에 비해 무시할 수준이었기 때문이다. 이를 보완하기 위해 WLM(Wire Load Model)이라는 통계적 모델을 사용했다. WLM은 팬아웃(Fanout) 개수에 비례하여 배선 저항과 커패시턴스를 대략적으로 추정하는 방식이다.
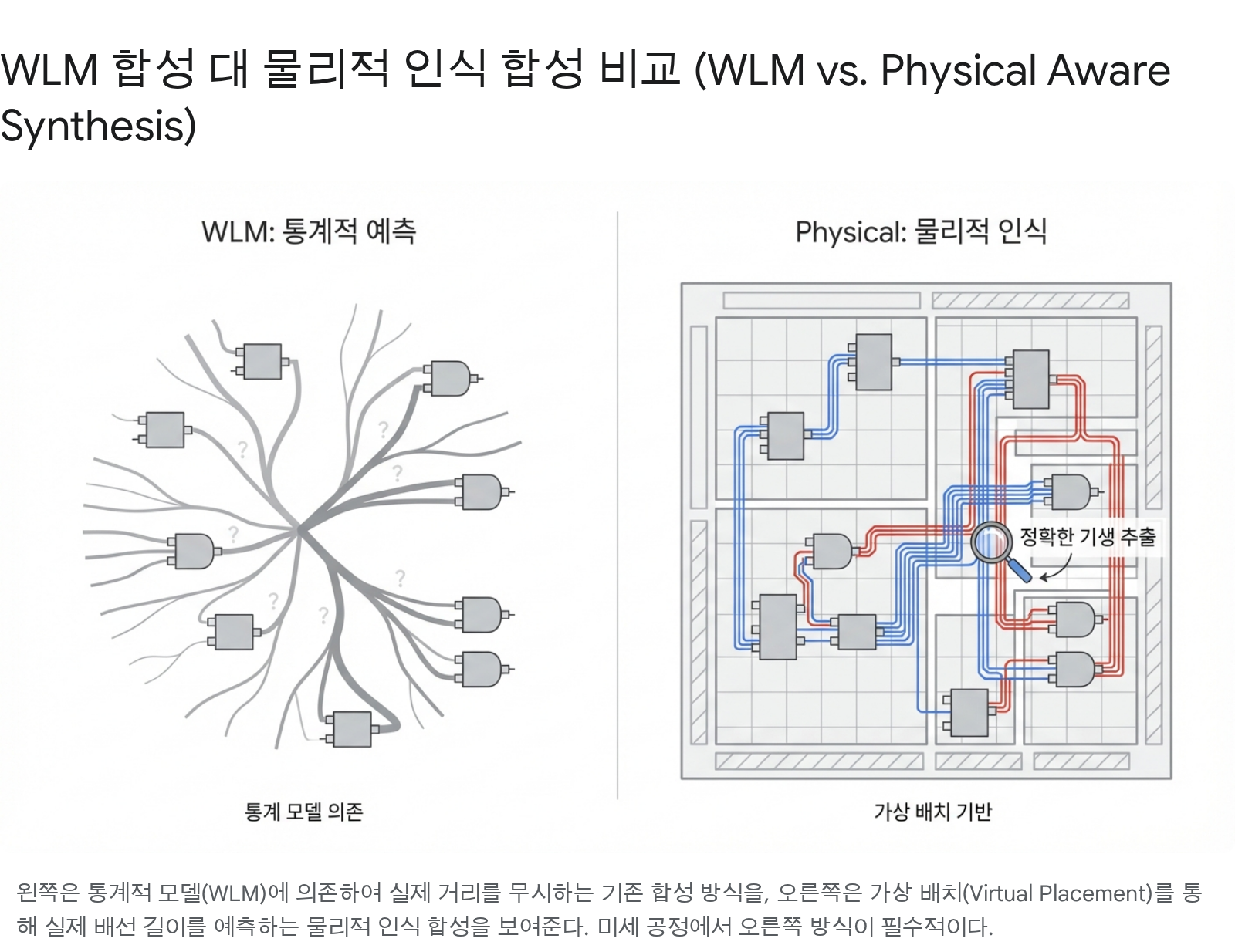
5.1 WLM의 한계와 물리 합성의 등장
그러나 65nm, 28nm, 그리고 FinFET 공정으로 넘어가면서 상황은 역전되었다. 배선 폭이 좁아지면서 Resistance 비율이 급격히 증가했고, 배선 간의 Coupling Capacitance가 전체 지연의 50% 가까이 차지하게 되었다. WLM 기반의 합성은 실제 P&R 후의 타이밍과 심각한 Correlation Issue를 보였고, 이는 끝없는 설계 Iteration을 야기했다.
이에 대한 해결책으로 Physical Aware Synthesis이 등장했다. Synopsys의 Design Compiler Graphical/NXT (compile_ultra -spg)나 Cadence의 Genus iSpatial 기술이 여기에 해당한다. 이들은 합성 엔진 내부에서 자사 P&R 엔진의 Coarse Placement와 Global Routing API를 불러서 현재 DEF 기준으로 어떻게 Routing을 할건지 Estimation하고, 그런 값들을 Logic Synthesis 단계에서 보겠다는거죠.
5.2 물리 합성의 핵심 기능
- Virtual Placement & Routing: 실제 P&R 툴(IC Compiler2, FusionCompiler, Innovus)과 동일한 배치 엔진을 사용하여 셀들의 대략적인 위치를 잡는다. 이를 통해 셀 간의 실제 거리(Manhattan Distance)를 기반으로 RC 기생 성분을 추출한다.
- Congestion 분석 및 완화: 특정 영역에 로직이 과도하게 몰려 라우팅이 불가능해지는 혼잡 현상을 합성 단계에서 미리 감지한다. 툴은 혼잡한 영역의 로직을 분산시키거나(Spread), 구조를 변경하여 DRC Violation를 사전에 방지한다.
6. 결과 분석 및 타이밍 수정 전략
합성이 완료되면 엔지니어는 수많은 Report와 Log를 분석하여 Quality of Results을 검증해야 한다. 이 단계는 다음 공정으로 데이터를 Handoff 전 마지막 품질 관문이다.
6.1 타이밍 리포트 해석과 Path Group
타이밍 리포트는 Launch Flop에서 Capture Flop까지의 여정을 보여준다. 분석의 효율성을 위해 툴은 경로를 성격에 따라 Path Group으로 분류한다.
- Reg2Reg: 플립플롭 간의 경로. 칩 성능의 핵심 지표다. Synthesis 단계에 Violation 크게 있으면, P&R 끝나고 더 좋아지기는 쉽지 않다.
- In2Reg / Reg2Out: I/O 인터페이스 경로. 앞서 설정한
set_input_delay/output_delay의 영향을 받는다. 다른 단에 여유가 있으면, 여기에서 크게 문제가 안 될 수 있다. - In2Out: 종종 이거 Constraint 안 걸리면, 여기 cell 다 삭제 될 수도 있고, 엄청나게 Buffer 추가 될 수도 있으 주의.
6.2 Setup/Hold 위반 수정 가이드
합성 단계에서의 타이밍 수정 전략은 P&R 단계와 다르다. 아직 배선이 확정되지 않았기 때문이다.
Setup Time 위반 (Max Path) 해결 전략
Setup 위반은 데이터가 너무 늦게 도착해서 발생한다.
- RTL 수정: 가장 강력하다. 파이프라인 레지스터를 추가하거나, 복잡한
if-else체인을 병렬적인case문으로 변경한다. - LVT 셀 활용:
compile_ultra옵션에서 누설 전력이 크지만 속도가 빠른 Low-Vt (LVT) 셀의 사용 비중을 높이도록 설정한다. 단, 이는 전력 소모 증가를 수반한다. - Path Group Weight:
group_path -weight명령어를 사용하여 특정 경로 그룹에 더 높은 우선순위를 부여, 툴이 면적을 희생하더라도 해당 경로를 최적화하도록 강제한다. - Logic Cloning, Retiming, Boundary optimization을 사용해서 줄이는 방법도 있다. 이런 것들은 P&R tool이 스스로 하기 어려운 것들이고, 하더라도 매우 복잡하다.
- Logic에 대해서 마지막으로 건드리는 곳이 Synthesis라고 보는게 좋다. 나중에 ECO 단계에 이런 timing violation 수정하려고 ICG Cloning 같은 것 하다 보면... Synthesis에서 몇 분 걸릴 것들이, ECO에서는 몇 시간 걸린다.
Hold Time 위반 (Min Path) 해결 전략
Hold 위반은 데이터가 너무 빨리 도착해서 발생한다.
- 원칙: 합성 단계에서는 일반적으로 Hold timing의 신뢰도는 낮다. 실제 배선 지연이 없는 상태에서 버퍼를 넣어봤자 P&R 단계에서 다시 제거되거나 부정확할 확률이 높기 때문이다.
- 그래도 큰 Hold violation 값 (디자인마다 다름.) 들은 합성 단계에서 어느 정도 잡아주는 것이 P&R 툴의 부담을 줄여준다.
7. 최신 툴 트렌드: Design Compiler vs Genus
현재 시장을 양분하고 있는 Synopsys의 Design Compiler(DC)와 Cadence의 Genus는 서로 다른 강점을 갖고있다.
- Synopsys Design Compiler: Synthesis의 업계 표준(De facto standard)으로 오랫동안 군림해 왔다. 강력한 생태계와 안정성이 장점이며, Fusion Compiler 플랫폼을 통해 P&R 과의 통합을 강화하고 있다.
- Cadence Genus: Synthesis의 후발 주자이지만, P&R Tool인 Innovus가 Physical Design engineer로부터 매우 인기가 많기 때문에, 인기가 높아지고있다.
내 주변 PD 엔지니어들을 보면, DesignCompiler와 Innovus 조합을 선호하는 경우가 많다. 중요한건, 하나의 Tool만 사용하다보면, 사람 자체가 종속되어서 다른 Tool로 넘어가기가 쉽지 않다. 이건 어쨌든 도구다.
결론: Tool을 지배하는 엔지니어가 되어야 한다
Logic Synthesis는 RTL을 게이트로 바꾸는 번역기가 아니다.
- Operator: 이들은 link_design 성공 할 때까지 이것저것 시도하고, link 되면 compile 하고, Netlist가 생성되면 그것을 P&R 엔지니어에게 전달한다.
- Expert: 이들은 RTL 코드 리뷰부터 P&R 엔지니어들과의 회의, EDA에게 신기능 개발 요청까지 모든 것을 인터페이스하고, 최고의 PPA가 나올 방법을 연구한다.
Logic Synthesis는 수천만 개의 변수를 가진 방정식을 물리적, 논리적 제약 조건 하에서 풀어내는 고도의 엔지니어링 과정이다.
툴은 완벽하지 않다. SDC를 통해 툴에게 정확한 '의도'를 전달하고, 로그와 리포트를 통해 툴의 '생각'을 읽어내며, 물리적 현상을 이해하고 RTL 구조를 '개선'할 줄 아는 엔지니어만이 최고의 PPA 결과를 얻을 수 있다.
주니어 엔지니어들은 툴의 버튼을 누르는 오퍼레이터에 머물지 말고,
"이 제약 조건이 툴의 비용 함수에 어떤 영향을 주는가?"
"이 RTL 구조가 매핑 알고리즘에 어떤 패턴으로 인식되는가?"
"이번 SNUG 논문에는 Synthesis 관련 논문은 뭐가 있지?? 다른 회사는 뭘 하고 있을까??"
를 끊임없이 질문해야 한다. 그 질문들에 대한 답이 쌓일 때, 비로소 진정한 의미의 'Architect'로 거듭날 수 있을 것이다.