현대 반도체 산업은 Moore's Law가 예측한 트랜지스터 집적도의 한계를 끊임없이 돌파하며 나아가고 있습니다. 수십억 개의 트랜지스터가 손톱만한 실리콘 Die 위에 집적되는 VLSI 시대입니다.
RTL 코드를 실제 제조 가능한 물리적 레이아웃인 GDS 파일로 변환하는 Physical Design, 통칭 P&R(Place and Route) 과정은 단순한 RTL code를 넣어서 GDS code를 받는 Code2Code 자동화를 넘어선 극한의 다변수 최적화 문제로 진화했습니다.
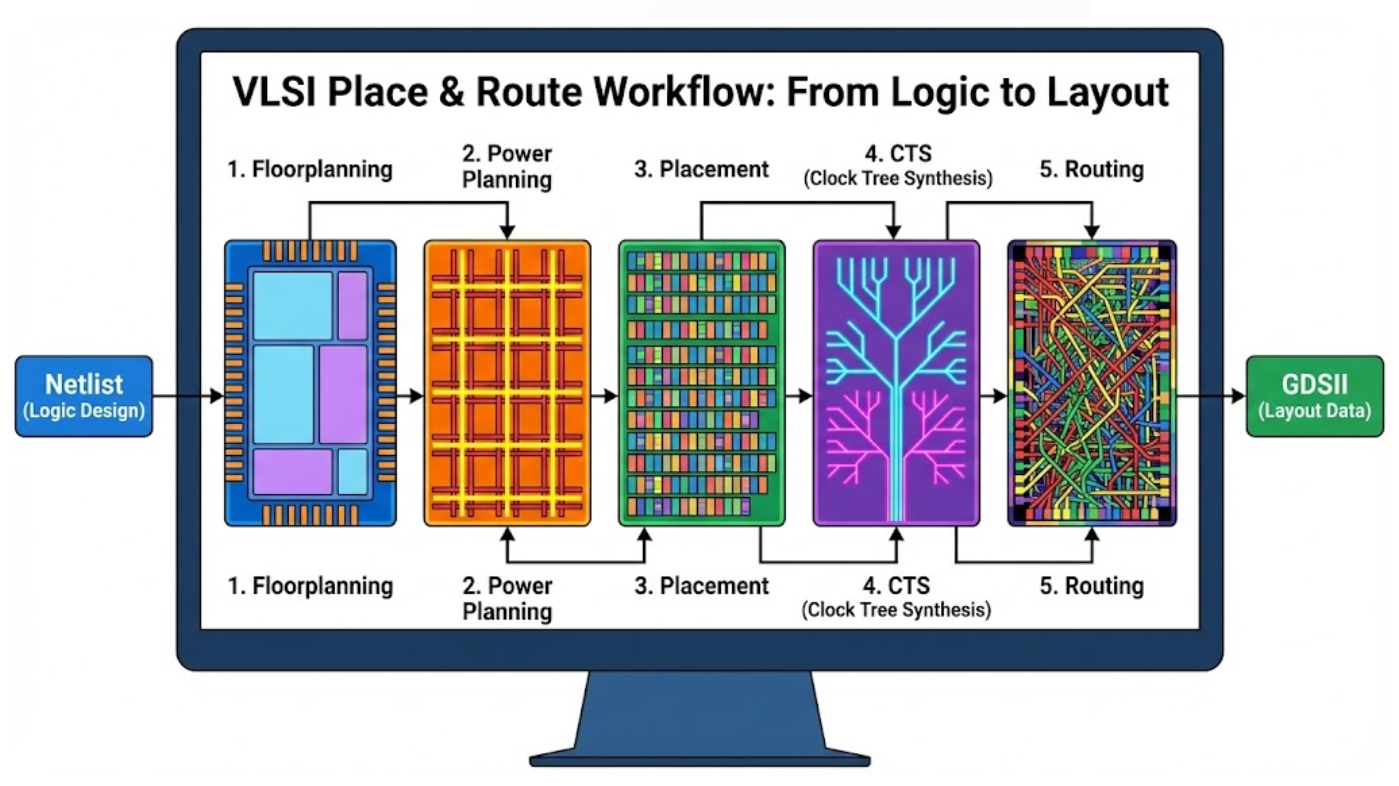
과거 µm 단위의 공정에서 P&R이 단순히 소자를 배치하고 선을 연결하는 기하학적 퍼즐이었다면, 7nm, 5nm, 그리고 3nm 이하의 FinFET 및 Gate-All-Around 공정에서의 P&R은 양자 역학적 효과, 전자기적 상호작용, 그리고 제조 공정의 물리적 한계까지 고려해야 하는 복합 물리학적 엔지니어링의 정점이라 할 수 있습니다.
P&R은 경우의 수가 너무 많은 NP-Problem입니다.
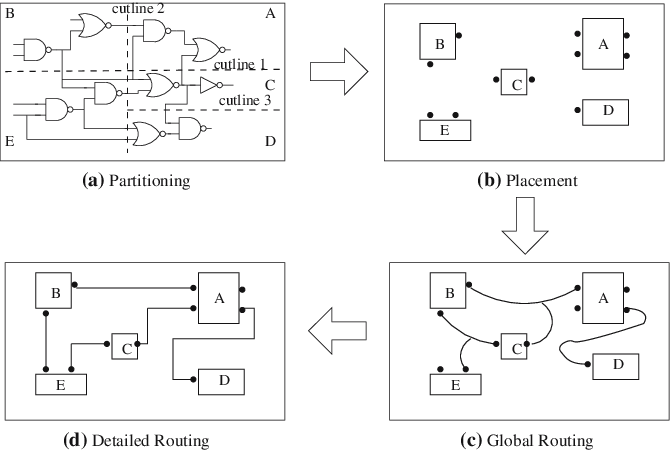
1. Design Partitioning
현대의 SoC 설계는 단일 엔지니어나 단일 CAD 툴 세션이 처리할 수 있는 범위를 넘어섰습니다. Flat design으로 처리하려 할 경우, 메모리 부족 현상이나 수주에 달하는 런타임, 그리고 수렴 불가능한 타이밍 문제에 직면하게 됩니다.
따라서 Partitioning은 물리적 설계의 첫 단추이자, 전체 프로젝트의 성공 여부를 가늠하는 전략적 아키텍처링 단계입니다.
대부분 Partitioning의 단위는 Runtime을 기준으로 잡습니다. 예를들어, "우리 Timing ECO를 하루에 1번은 할 수 있는 runtime을 갖게하자." 이런 기준들이요.
1.1 Hierarchical Design
Partitioning은 "Divide and Conquer" 원칙을 시스템 설계에 적용한 것입니다. 설계 방법론은 크게 Top-Down 방식과 Bottom-Up 방식으로 구별됩니다.
- Top-Down Partitioning
- Top-down 방식은 전체 칩을 시스템 수준에서 큰 기능 블록으로 나누고, 이를 반복적으로 더 작은 모듈로 세분화하면서, Chip Top에서 각 Subsystem을 나누고, 각 Subststem들이 사용할 PPSA를 할당합니다.
- System on Chip level에서 많이 사용됩니다.
- Bottom-Up Partitioning
- Bottom-up 방식은 작은 leaf cell이나 모듈부터 시작해 이를 Subsystem으로 만들어 마지막에 Top으로 조립합니다.
- Reuse 할 IP 설계에서 많이 사용됩니다.
2. Advanced Partitioning Methodology
최근에는 Hierarchical과 Flat 방식의 장점을 혼합한 'Pseudo-Flat' 또는 'Virtually Flat' 방식이 주목받고 있습니다.
물리적으로는 Partitioning을 통해 계층 구조를 유지하되, Timing Analysis나 CTS 단계에서는 Tool이 전체 디자인을 Flat하게 인식하게 하여 Block Boundary에서의 비효율성을 제거하는 기법입니다.
2.2 Partitioning Algorithms & Optimization Metrics
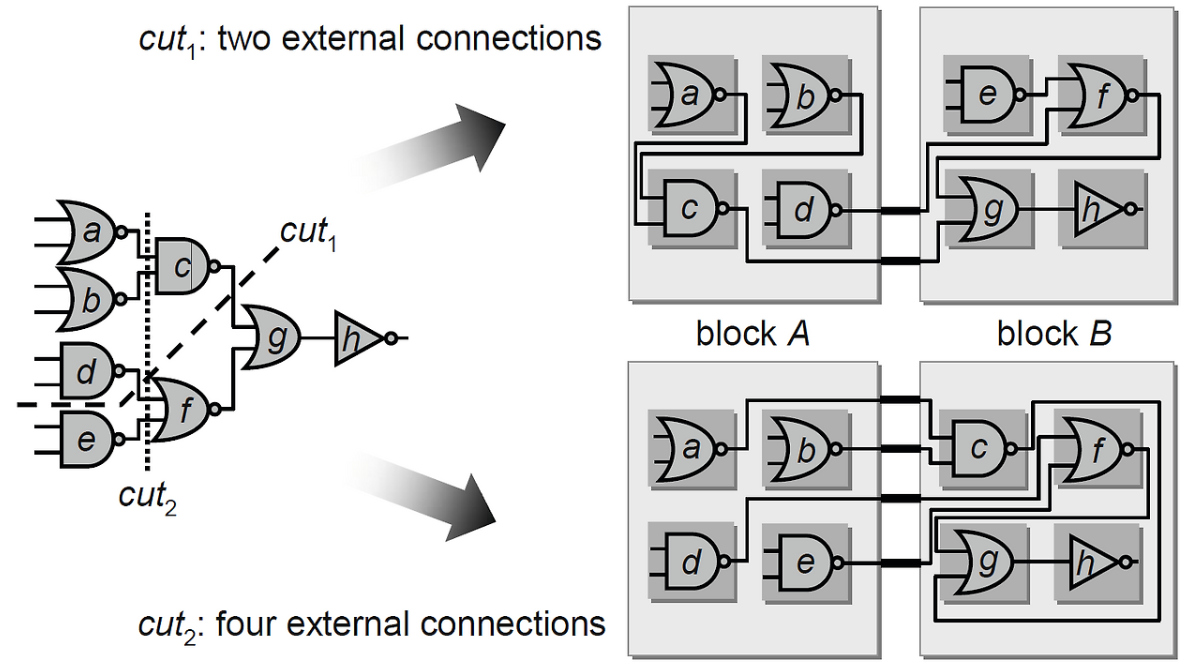
Partitioning 수행 시 Technical Constraints와 Optimization Goals를 동시에 고려해야 합니다. 가장 대표적인 알고리즘은 Kernighan-Lin Algorithm입니다. Pseudo code를 보여드릴게요.

- Min-Cut Principle: Interconnect 수를 최소화해야 합니다. 블록 간 신호는 Top Level의 Routing Resource를 소모하며, 긴 Wire length로 인해 Latency 및 Signal Integrity 문제를 야기합니다. Kernighan-Lin과 같은 Graph Partitioning Algorithm이 Cut size 최소화에 사용됩니다.
- Area Balance & Aspect Ratio: 각 Partition은 물리적 구현이 가능한 형태와 크기를 가져야 합니다. 높은 Aspect Ratio나 Rectilinear 모양은 내부 Placement & Routing 효율을 떨어뜨립니다. 통상적으로 1M ~ 3M Instances 정도가 하나의 블록으로 처리하기에 적절한 크기입니다.
- Timing Budgeting: Partitioned block은 독립적인 SDC를 가져야 합니다. Top-level path delay 중 얼마만큼을 내부 로직에 할당할지 결정하는 Budgeting 과정은 매우 정교해야 합니다. 과도한 제약은 Area/Power overhead를, 느슨한 제약은 Top-level integration 시 Timing Violation을 초래합니다.
3. Floorplanning: The Structural Foundation
Floorplanning은 칩의 물리적 골격을 세우는 과정입니다. 이 단계의 결정은 후속 공정인 Placement와 Routing에 절대적인 영향을 미치며, 잘못된 Floorplan은 복구 불가능한 PPA Loss나 Routing Congestion을 유발합니다.
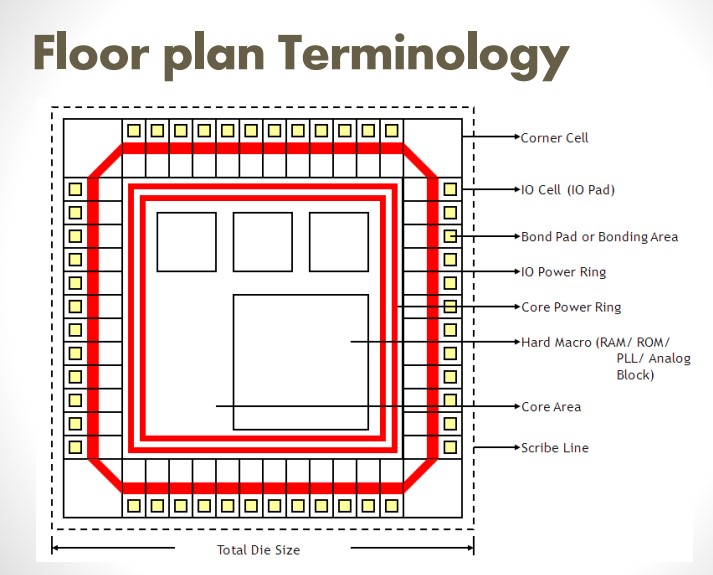
3.1 Core Area Definition & Geometry
- Aspect Ratio: Width-to-Height 비율입니다. 통상 1.0(정사각형)에 가까울수록 Horizontal/Vertical Routing Resource의 균형이 좋아 효율적입니다.
- 하지만 Packaging, PCB Footprint, Die Sawing 효율로 인해 직사각형이 강제되기도 하며, 이는 특정 방향의 Congestion을 유발할 수 있습니다. CPU, GPU, NPU 같은 High frequency의 Block들을 우선으로 1.0 ratio를 맞추고, Interface block들을 그 다음에 맞추는 방식이 선호됩니다.
- Utilization: Core Area 내에서 Standard Cell과 Macro가 차지하는 비중입니다.
- 초기 설계 시 60~70% 수준으로 설정하여 Buffer Insertion, Sizing, Routing Margin을 확보합니다. 80% 이상의 고밀도는 Routing Congestion 급증으로 Timing ECO가 매우 어려워집니다. 그리고 DFM Yield 저하의 원인이 됩니다.
3.2 Macro Placement: Data Flow Visualization
Hard Macro(SRAM, PLL, ADC/DAC) 배치는 가장 높은 숙련도를 요합니다. Macro는 거대하며 특정 Metal Layers를 점유하므로 사실상 Routing Blockage 역할을 합니다.
실제로 ASIC 설계 엔지니어들이 말하는 Project에서 가장 중요한 요소 3가지는 아래와 같습니다.
- RTL Freeze (빨리 RTL 완성을 해야 Tape-out 일정 맞춤)
- SDC Clean (False path, MCP 등 필요 없는 Path들 잘 정리하고, 각 EDA Flow에 맞는 Constraint를 잘 걸어줘야 Signoff를 안정적으로 합니다.)
- Golden Floor Planning (이걸 어떻게 하느냐에 따라 Chip의 Utilization과 Hold time, SI, DRC 문제들 난이도가 결정 됩니다.)
[Macro Placement Strategies & Guidelines]
- Flyline Analysis: Macro-to-Macro, Macro-to-StdCell 간의 가상 연결선을 분석하여 Data Flow를 최적화해야 합니다. 입력에서 출력 방향으로 데이터가 직진성을 갖도록 배치하는 것이 이상적입니다.
- Peripheral Placement: Macro를 Core Boundary나 블록 외곽에 배치하여 Center Area를 Standard Cell 및 복잡한 신호 라우팅을 위해 확보하는 것이 정석입니다. 중앙에 위치한 매크로는 Detour를 유발하여 심각한 Timing Delay를 초래합니다.
- Macro Channel & Halo: 매크로 사이에는 Power Strap이나 Clock Tree Buffer가 삽입될 Channel 공간이 필요합니다. 또한 Keepout Margin(Halo)을 설정하여 Pin Accessibility를 확보하고 국부적인 Congestion을 방지해야 합니다.
최근에는 AI를 이용한 Floor planning 방법론들도 많이 연구되고 있습니다.
2.3 I/O Planning 및 Pin Placement
외부 세계와 칩을 연결하는 I/O Pad 또는 핀의 위치 선정 또한 중요합니다. Wire-bonding 패키지를 사용하는 경우 칩 외곽에 I/O Ring을 구성하며, Flip-chip 패키지를 사용하는 경우 칩 전면에 걸쳐 Bump를 배치합니다. I/O 핀의 위치는 내부 로직의 데이터 흐름 방향을 결정짓는 Anchor 역할을 하므로, PCB 설계 팀과의 긴밀한 협의를 통해 결정되어야 합니다.
3. Power Planning: 생명을 불어넣는 혈관, PDN 설계
Power Planning은 칩 전체에 전력(VDD)과 접지(VSS)를 안정적이고 균일하게 공급하기 위한 PDN(Power Delivery Network)을 구축하는 과정입니다. 미세 공정으로 진입하면서 공급 전압은 낮아지는 반면(Threshold Voltage 감소), 소자 밀도 증가로 인한 전류 밀도는 급증하고 있습니다.
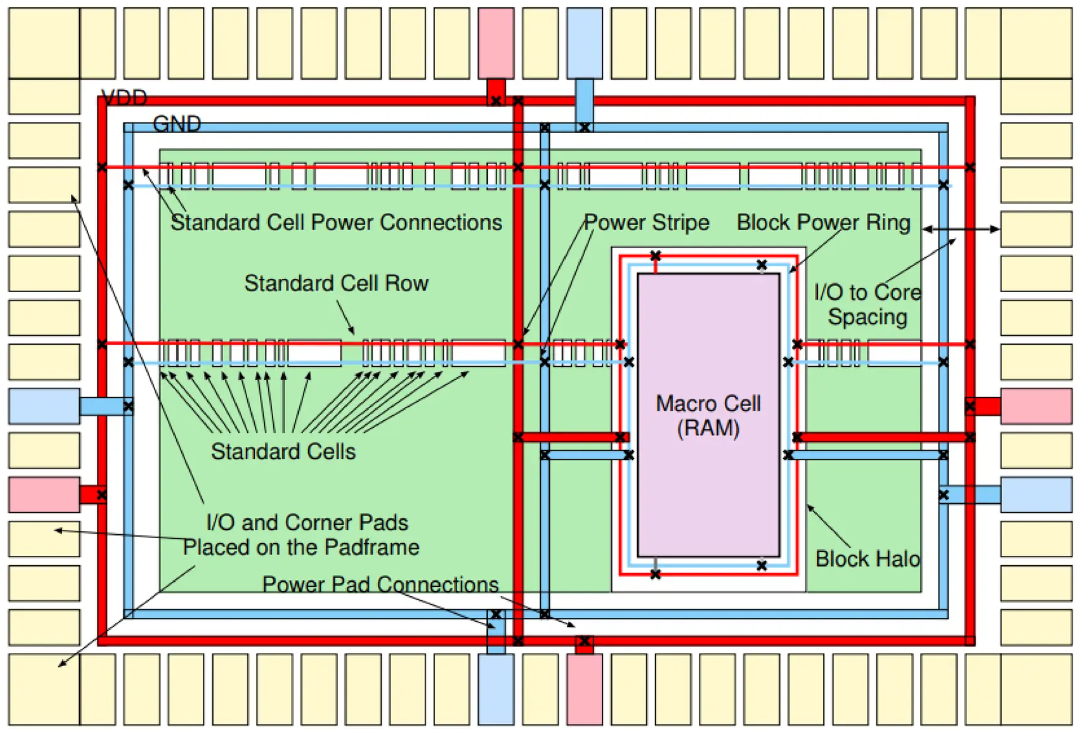
이로 인해 발생하는 IR Drop과 Electromigration(EM)문제는 칩의 신뢰성 문제와Functional Failure를 유발하는 가장 큰 위험 요소가 되었습니다.
3.1 PDN 아키텍처의 계층적 구조
효율적인 전원 공급망은 계층적인 그물망 구조를 가집니다.
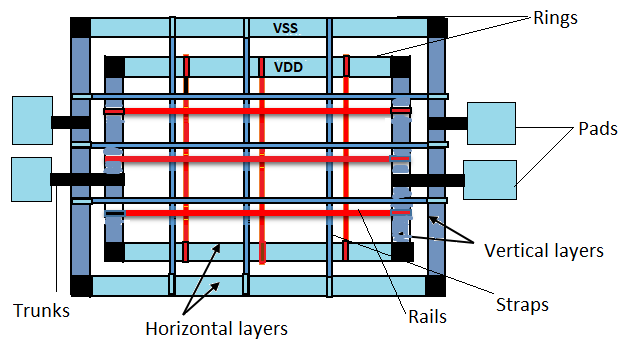
- Power Rings: 칩의 코어 외곽 전체를 감싸거나, 전력 소모가 큰 매크로 블록 주위를 둘러싸는 굵은 전원선입니다. 외부 전원이 처음 도달하는 저수지와 같은 역할을 합니다.
- Power Stripes (Trunks): 칩을 가로지르며 전류를 코어 내부 깊숙한 곳으로 전달하는 주요 간선입니다. 저항을 최소화하기 위해 가장 상위의 두꺼운 메탈 레이어(Top Metal Layers)를 사용하며, 적절한 간격(Pitch)으로 배치하여 IR Drop을 제어합니다.
- Power Rails: 표준 셀의 VDD/VSS 핀에 직접 연결되는 가장 하위 레벨의 전원선입니다. 주로 M1(Metal 1) 레이어에 형성되며, Follow-pin이라고도 불립니다. 모든 표준 셀은 이 레일에 맞물려 전원을 공급받습니다.
- Vias: 각 계층의 전원선을 수직으로 연결하는 통로입니다. 단일 비아는 저항이 크고 EM에 취약하므로, Via Array나 Bar Via를 사용하여 연결성을 강화해야 합니다.
3.2 IR Drop의 물리학과 대응 전략
IR Drop은 전원선 자체의 저항(R)으로 인해 전류(I)가 흐를 때 전압이 떨어지는 현상(V=IR)입니다.
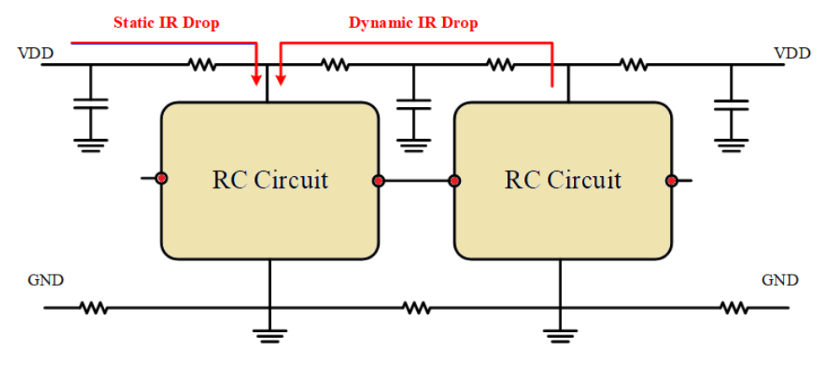
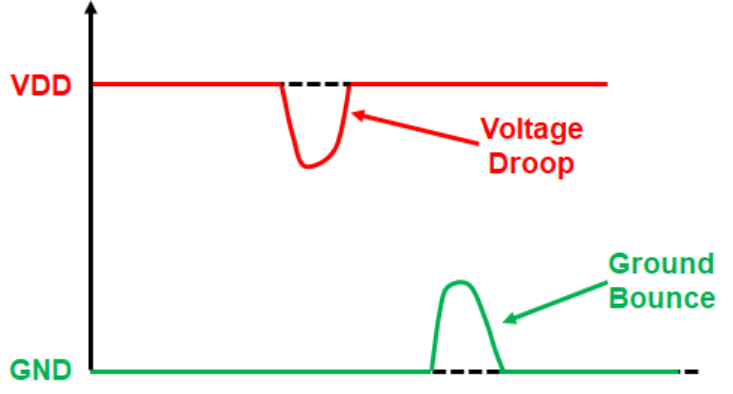
- Static IR Drop: Switching이 발생하지 않는 상태나, 평균적인 전류가 흐를 때의 전압 강하입니다.
- 해결책 - 해당 전원 Routing의 총 저항을 줄이기: Stripe의 폭을 넓히거나 개수를 늘려 병렬 저항을 감소시키거나, 아니면 이쪽에 Cell들을 줄이는 방법으로 해결 할 수 있습니다.
- Dynamic IR Drop: 주로 Clock Edge에서 수많은 플립플롭과 로직 게이트가 동시에 Switching 때 발생하는 순간적인 Transient Current에 의한 전압 강하입니다. 이는 L(di/dt) 노이즈와 결합하여 심각한 전압 출렁임을 유발하며, 타이밍 지연이나 데이터 오동작을 일으킵니다.
- 해결책 - Decoupling Capacitor (Decap): 전원 핀 근처에 Decap 셀을 배치하여 로컬 에너지 저장소 역할을 하게 합니다. 순간적인 전류 요구가 발생할 때 멀리 있는 전원 패드가 아닌 인접한 Decap에서 전하를 공급받음으로써 Dynamic IR Drop을 완화합니다.
4. Placement
Placement는 합성된 Netlist의 Logic Gates를 Floorplan에 정의된 물리적 공간 내의 구체적인 좌표 (x, y)에 할당하는 과정입니다. 목표는 단순히 셀을 배치하는 것을 넘어 Timing, Power, Area를 최적화하면서 후속 단계인 Routing이 가능한(Routable) 상태를 만드는 것입니다.
4.1 Placement Mechanism: Coarse to Fine
현대의 Placement Engine은 수백만 개의 셀을 처리하기 위해 다단계 최적화 기법을 사용합니다.
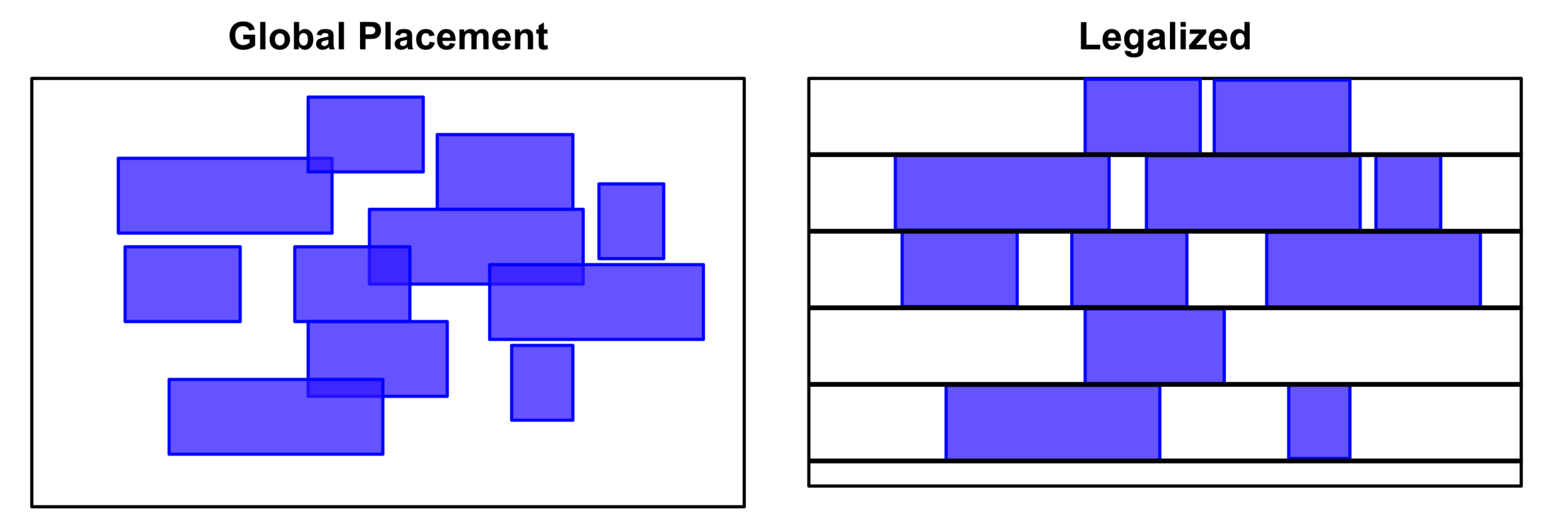
- Global Placement (Coarse Placement):
- Cell을 크기가 있는 객체가 아닌 수학적 Point로만 간주합니다.
- Analytical Placement: Quadratic 또는 Non-linear optimization 기법을 사용하여 전체 Wirelength를 최소화합니다.
- Density Penalty / Electrostatic Force Model: 셀이 뭉치는 것을 방지하기 위해 셀들을 서로 밀어내는 Charge로 모델링하여 Wirelength 최소화(인력)와 Density 균일화(척력)의 평형점을 찾습니다.
- 결과적으로 셀들은 대략적인 위치에 분포하지만, Overlap이 존재하고 Standard Cell Row에 정렬되지 않은 상태입니다.
- Legalization:
- Global Placement 결과를 바탕으로 모든 셀을 실제 제조 가능한 위치로 이동시킵니다.
- 셀들을 Standard Cell Row와 Site Grid에 정확히 정렬(Snap)시키고 Overlap을 해소합니다. 이때 Displacement를 최소화하여 이전 단계의 최적화 결과를 보존하는 것이 핵심입니다.
- Detailed Placement:
- Legalization 이후 미세 조정을 수행합니다. 인접 셀 간의 Swapping이나 빈 공간 이동을 통해 Local Wirelength를 줄이고 Pin Accessibility를 개선합니다.
4.2 Congestion Management & Cell Padding
특정 영역에 Pin Density가 과도하게 높으면 Routing 단계에서 Track이 부족해지는 Congestion이 발생하며, 이는 DRC Violation (Short/Open)의 주원인이 됩니다.
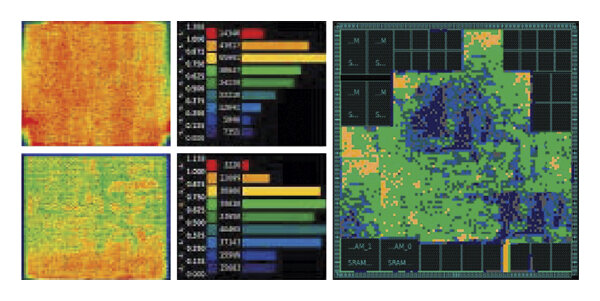
- Cell Padding (Bloating): Congestion이 예상되는 복잡한 셀 주변에 가상의 Padding을 설정합니다. 이는 물리적 거리를 확보하여 배선이 지나갈 수 있는 Porosity를 제공합니다.
- Congestion Map: Global Routing 예측 모델을 통해 칩 전체의 혼잡도를 Heatmap 형태로 분석하고, Hotspot 영역의 셀들을 흩어놓는 Cell Spreading 기법을 적용합니다.
5. Clock Tree Synthesis (CTS): Temporal Synchronization
Clock Tree Synthesis (CTS)는 클럭 신호를 칩 내부의 수많은 Sequential Elements (Flip-flops)에 동시적이고 무결하게 전달하는 과정입니다. 클럭 네트워크는 전체 Power Consumption의 30~40%를 차지하며, 그 품질은 칩의 Performance를 결정짓는 핵심 요소입니다.
5.1 Key Metrics of CTS
CTS의 목표는 다음 지표들을 정밀하게 제어하는 것입니다.
- Latency: Clock source에서 Flip-flop까지 도달하는 절대적 시간입니다. Latency가 길수록 OCV (On-Chip Variation)의 영향을 크게 받아 Timing Uncertainty가 증가하므로 가능한 짧게 유지해야 합니다.
- Skew: 클럭 소스에서 빨리 도착하는 Flip-flop과 늦게 도착하는 것들의 시간 차이. 즉 Sink pin들의 Latency 차이입니다. Global Skew는 0 Skew가 원칙이나, 인접 Register 간의 Local Skew를 조절하여 Setup/Hold Margin을 확보하는 Useful Skew 기법이 최근에는 더 많이 활용됩니다.
5.2 Clock Topology
전통적인 트리 구조에서 고성능 컴퓨팅을 위한 메쉬 구조까지 다양한 토폴로지가 존재합니다.
6. Routing: 수십억 개의 점을 잇는 미로 찾기
Routing은 배치된 셀들의 핀을 설계 규칙(DRC)을 준수하며 실제로 금속 선으로 연결하는 단계입니다. 이 과정은 수학적으로 NP-Hard 복잡도를 가지는 미로 찾기(Maze Routing) 문제의 연속입니다.
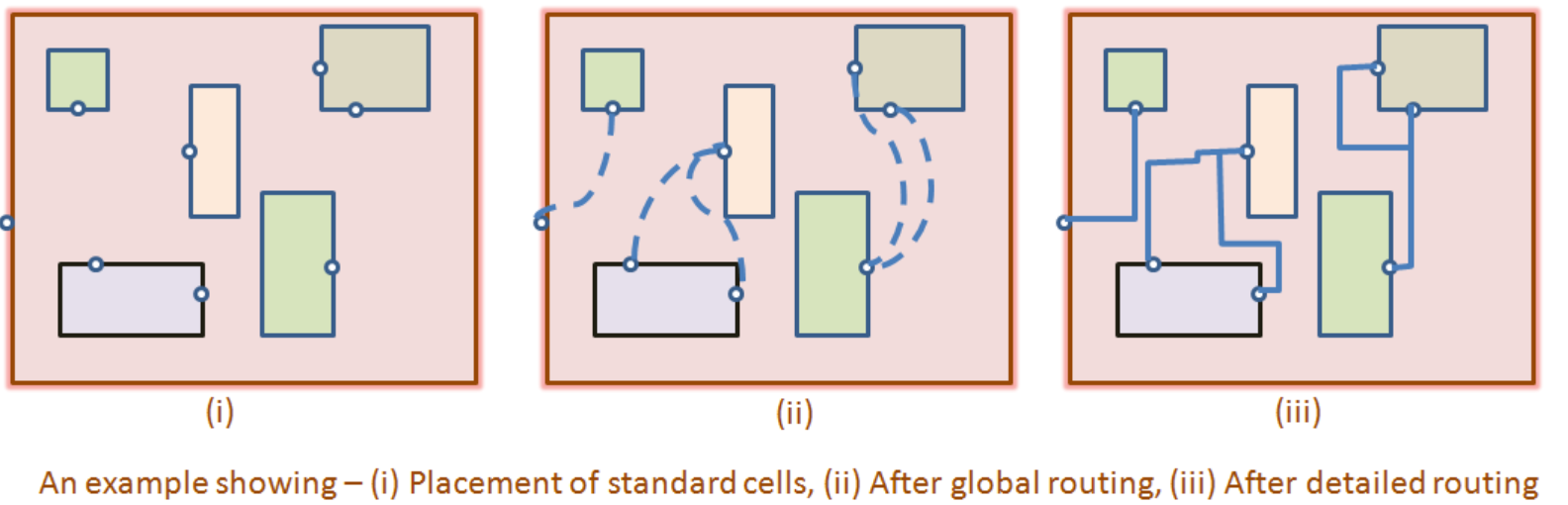
6.1 Routing Stages: From Path to Geometry
Routing 과정은 설계 복잡도를 제어하기 위해 단계별로 진행됩니다.
- Global Routing:
- 전체 칩을 GCell (Global Cell) 영역으로 분할하여 관리합니다.
- 구체적인 Track을 지정하기 전, Pin-to-Pin 연결을 위해 통과해야 할 GCell 경로를 탐색합니다.
- 주요 목표는 Congestion 관리입니다. 각 GCell Boundary의 Routing Capacity와 실제 Routing Demand를 비교하여 Detour 경로를 생성함으로써 혼잡을 분산시킵니다.
- Track Assignment:
- Global Routing 결과를 바탕으로 각 Net을 특정 Metal Layer의 구체적인 Track에 할당합니다.
- 직선 배선을 우선 배치하여 Via 사용을 최소화하고 Routing Efficiency를 높입니다.
- Detailed Routing (Nano Routing):
- 할당된 Track 내에서 실제 물리적인 Shape을 생성합니다.
- Pin Access를 위한 미세한 Jog 생성, Via 생성, 그리고 수천 가지의 DRC (Spacing, Width, Enclosure 등) 규칙 준수 여부를 확인하고 수정합니다.
6.2 Signal Integrity (SI) & Crosstalk
공정이 미세화되면서 배선의 Thickness 대비 Width 비율이 커짐에 따라, 인접 배선 간 Coupling Capacitance로 인한 Crosstalk 현상이 심화됩니다.
- Crosstalk Delay: Aggressor와 Victim 배선이 서로 반대 방향으로 Switching할 때, Coupling 효과로 인해 신호 전달 시간이 늘어나 Setup Violation을 유발합니다. 반대로 같은 방향으로 Switching하면 전달 속도가 빨라져 Hold Violation의 원인이 됩니다.
- Crosstalk Noise (Glitch): Victim 배선이 정지 상태일 때 Aggressor의 Switching으로 인해 원치 않는 전압 스파이크(Glitch)가 유도되는 현상입니다. 이는 Logic Value를 반전시켜 기능적 오류를 야기할 수 있습니다.
- Mitigation Techniques: Spacing 확보, 배선 간 Shielding 선 삽입, 또는 Aggressor Cell의 Drive Strength 조절 기법 등이 사용됩니다.
6.3 Antenna Effect & Manufacturing Issues
Manufacturing 중 Plasma Etching 단계에서 긴 금속 배선이 Antenna처럼 작용하여 전하를 수집하는 현상입니다. 축적된 전하가 연결된 트랜지스터의 Gate Oxide로 방전되면 소자가 영구적으로 파손될 수 있습니다.
- Antenna Ratio: Gate Area 대비 배선의 Area 비율을 제한하여 관리합니다.
- Solutions:
- Jumper Insertion: 배선 중간에 Layer를 바꾸는 Jumper를 삽입하여 배선 길이를 물리적으로 끊어줍니다.
- Antenna Diode: Gate 근처에 Reverse Diode를 삽입하여 축적된 전하를 Substrate로 안전하게 방전시킵니다.
실제 흐름에서는 Place 다음 Place_opt을 하고. Route 다음에는 Route_opt를 하는식으로 opt가 중간에 계속 포함됩니다.
7.Chipfinish
P&R (Place and Route) 과정의 마지막 단계인 Chip Finishing은 설계된 칩이 실제로 Fabrication 될 수 있도록 물리적인 완성도를 높이는 작업입니다.
이전 단계인 Routing까지가 '기능적인 연결'을 완성하는 것이었다면, Chip Finishing은 공정상의 오류를 방지하고 Yield를 높이기 위한 DFM (Design for Manufacturability) 성격이 강합니다.
7.1. Filler Cell Insertion (Space cell)
Standard Cell들이 배치되고 나면 셀과 셀 사이에 빈 공간이 생깁니다.
이 공간을 그대로 두면, 기판의 전위 특성이 달라집니다. 이런걸 Density 문제라고 하는데요. 논리 기능은 없고 물리적 역할만 하는 'Filler Cell'로 채워 넣어 균일한 특성을 갖게 합니다.
7.2. Metal Fill (Dummy Metal)
반도체 공정 중에는 웨이퍼 표면을 평평하게 깎아내는 CMP (Chemical Mechanical Polishing) 공정이 있습니다. 이때 칩 전체의 Metal 밀도가 균일하지 않으면, 어떤 곳은 더 많이 깎이고 어떤 곳은 덜 깎이는 현상(Dishing/Erosion)이 발생합니다.
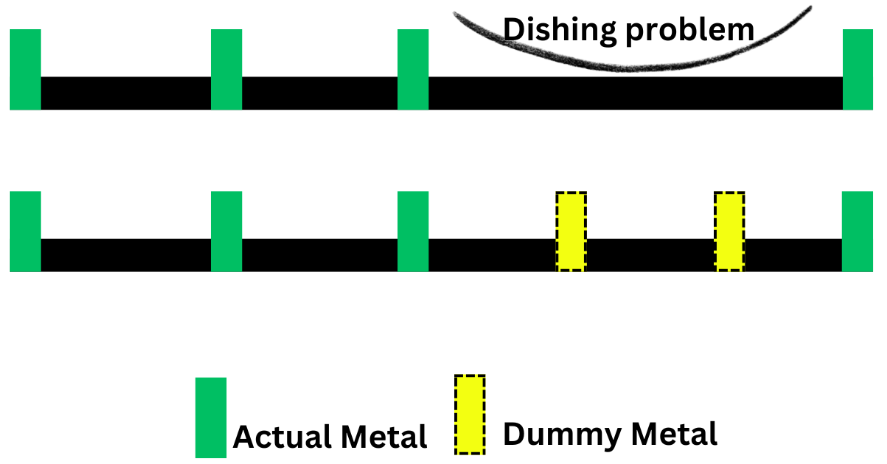
- 작업: 회로 동작과 무관한 'Dummy Metal' 조각들을 빈 공간에 채워 넣어 금속 밀도(Density)를 균일하게 맞춥니다.
- 효과: 칩의 평탄도를 확보하여 배선 불량 및 단선을 방지합니다.
3. Antenna Effect Repair
공정 중 Plasma Etching 단계에서, 긴 금속 배선이 안테나처럼 전하를 모으게 됩니다. 이 축적된 전하가 연결된 Gate Oxide로 방전되면 Gate가 파괴될 수 있습니다.
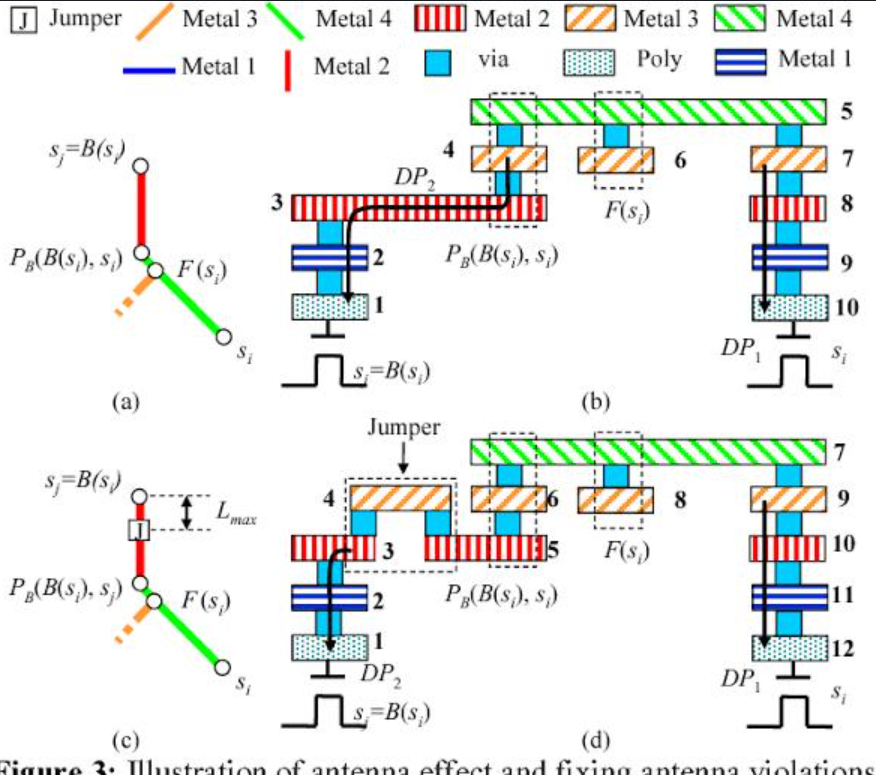
- 해결책:
- Diode Insertion: 축적된 전하를 Substrate으로 빼주는 다이오드를 게이트 근처에 삽입합니다.
- Metal Hopping (Jumping): 긴 배선을 상위 레이어의 메탈로 잠시 올려서(Jump) 제조 공정 순서상 전하가 쌓이는 길이를 물리적으로 끊어줍니다.
4. Via Optimization (Redundant Via 삽입)
배선 층간을 연결하는 구멍인 Via는 공정 중 저항이 높아지거나 끊어질 확률(Open Defect)이 가장 높은 취약점입니다.
- 작업: 공간이 허용하는 한, Single Via(비아 1개)를 Double Via(비아 2개) 또는 그 이상으로 바꿔줍니다.
- 효과: 비아 하나가 불량이 나더라도 나머지가 연결을 유지하므로 칩의 수율과 신뢰성이 대폭 향상됩니다.
5. Final Verification Preparation (최종 검증 준비)
이 단계가 끝나면 비로소 GDSII (또는 OASIS) 포맷으로 데이터를 추출(Stream Out)하여, 물리적 검증 단계(Physical Verification)로 넘길 준비를 마칩니다.
- DRC (Design Rule Check): 공정 규칙 위반 여부
- LVS (Layout Versus Schematic): 회로도와 레이아웃 일치 여부
Chip Finishing은 설계의 '기능'을 바꾸지는 않지만, 칩이 '죽지 않고 태어나도록' 만드는 결정적인 단계입니다.
결론: P&R, 첨단 공학의 총체적 집약
살펴본 바와 같이, VLSI Physical Design은 Partitioning부터 Chipfinish에 이르는 유기적이고 고도로 복잡한 엔지니어링 프로세스입니다. 넷리스트라는 논리적 설계를 GDSII라는 물리적 실체로 변환하는 과정은 단순한 변환이 아닌, 물리학적 제약(IR Drop, EM, Antenna), 전기적 제약(Timing, SI, Crosstalk), 그리고 제조 공정의 제약(DRC, DFM)을 모두 만족시키는 최적해를 찾아가는 여정입니다.
특히 FinFET 및 GAA와 같은 차세대 공정의 도입은 P&R 엔지니어에게 Quantized Cell Height, RDR, Self-heating 등 새로운 차원의 도전을 제시하고 있습니다. 따라서 현대의 P&R은 EDA 툴의 자동화 기능에만 의존해서는 결코 성공할 수 없으며, 각 단계의 기반이 되는 알고리즘적 원리와 물리적 현상에 대한 엔지니어의 깊은 통찰력이 필수적입니다.
데이터의 흐름을 읽는 Floorplan 능력, 전력 무결성을 보장하는 PDN 설계 능력, 그리고 수십 피코초(ps)의 타이밍을 맞추는 ECO 능력의 조화만이 성공적인 칩의 탄생을 보장할 수 있습니다.