![[VLSI CAD] Two-Level Logic Minimization이 어려운 이유](https://images.unsplash.com/photo-1642952469120-eed4b65104be?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fGFsZ29yaXRobXxlbnwwfHx8fDE3NjkzMzE5NjV8MA&ixlib=rb-4.1.0&q=80&w=1200)
TL;DR
- Two-Level Logic Minimization을 “정확히” 풀려면 Quine–McCluskey(QM) 흐름을 타게 된다.
- QM의 병목은 covering(minimum column cover) 단계다.
- covering은 NP-complete라서, “최적해”는 값이 아니라 증명 문제가 된다.
- SAT는 거의 큰 문제가 안 된다. 이유는 SAT가 본질적으로 decision 문제이기 때문이다.
EDA는 heuristic + pruning+ branch-and-bound로 “충분히 좋은 답”을 빠르게 만든다.
Two-Level Logic Minimization란?
상황
스위치가 3개 있다고 하자.
- A: 스위치 1
- B: 스위치 2
- C: 스위치 3
전구 F는 아래 세 가지 경우에 켜진다.
- A=0, B=0, C=1 -> A'B'C
- A=0, B=1, C=1 -> A'BC
- A=1, B=0, C=1 -> AB'C
즉, F = A'B'C + A'BC + AB'C
👉 AND 3개 + OR 1개
👉 쓸데없이 길다.
이걸 간단하게 만들어가는 과정이 최적화 과정이다.
세 식을 잘 보면:
- 전부 C = 1
- A, B는 이리저리 바뀜
즉, F = C(A'B' + A'B + AB')
안쪽을 좀 더 줄여보면,
A'B' + A'B = A'(B' + B) = A'
즉, F = C(A' + AB')
또 정리하면.
A' + AB' = A' + B'
최종 결과 (Two-Level Logic 최소화)
F = (A' + B')C
AND, OR의 수도 줄고, 식도 간단해졌다. 이게 하드웨어 레벨에서는 Cell과 Interconnect가 감소한다는 의미이다.
한 줄로 말하면
전구가 켜지는 조건을 하나하나 쓰지 말고,
공통 조건만 남기고 묶어라.
이게 Two-Level Logic Minimization이다.
좀 더 학술적으로 말해보면,
주어진 Boolean function (f)를, 최소 product terms(SOP)로 표현하라.
이때 핵심 재료는:
- minterm: truth table에서 (f=1)인 입력 조합(혹은 cube로 확장 전의 점)
- prime implicant: 더 이상 확장(merge)할 수 없는 “최대 cube”
- 목표: 모든 (f=1) minterm을 prime implicant들로 덮되(cover), 선택한 prime 수(혹은 비용)를 최소화
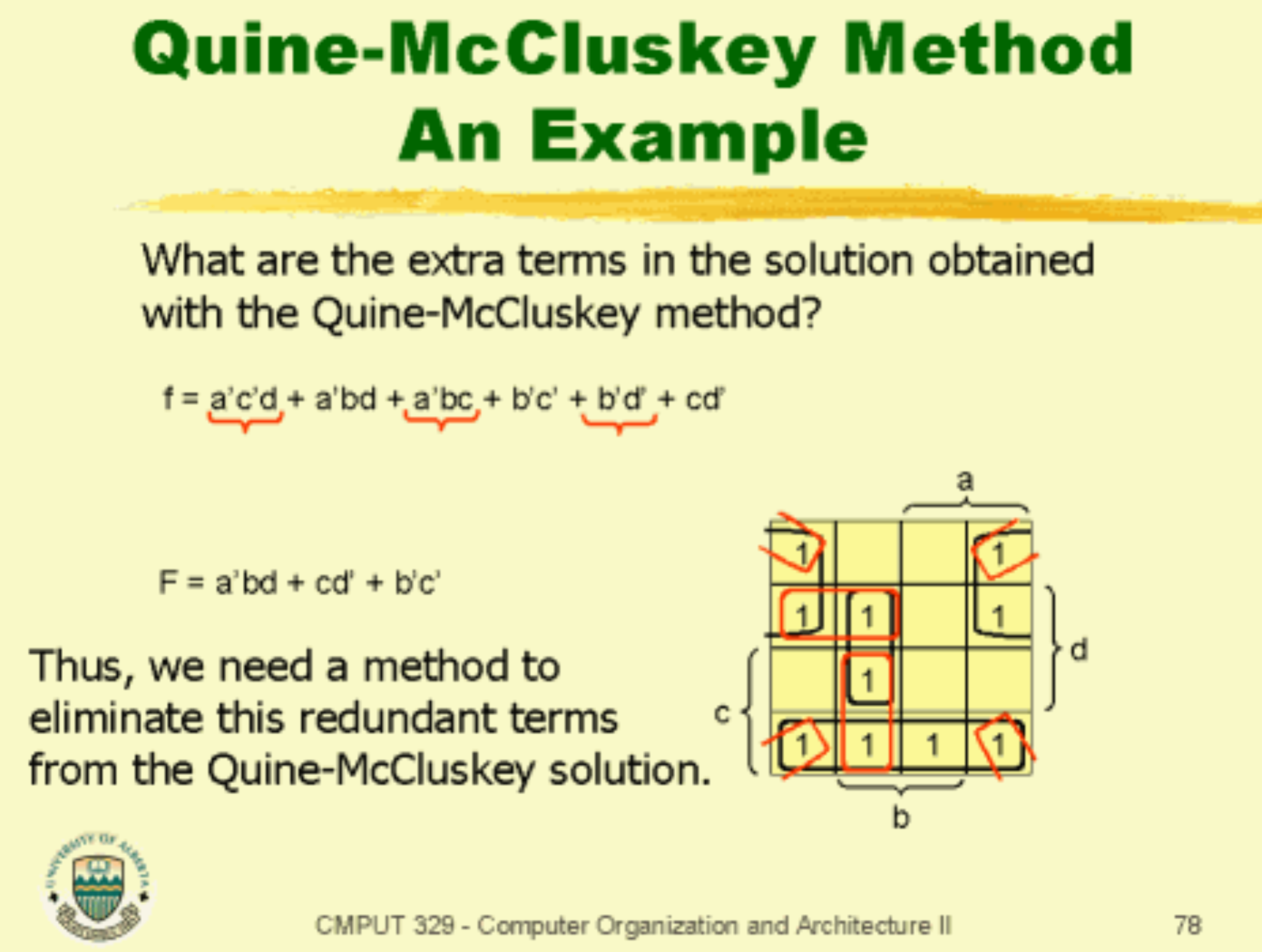
QM(Quine–McCluskey)이 하는 일 (정확해법)

위 그림에서 4번이 본체다.
Solve the minimum column coverting problem for B (unate coverting problem)
일단 QM에 대해 알아보자.
전구 문제 다시 시작
전구 F가 켜지는 경우는 딱 세 가지였다.
- A 꺼짐, B 꺼짐, C 켜짐
- A 꺼짐, B 켜짐, C 켜짐
- A 켜짐, B 꺼짐, C 켜짐
지금은 그냥 이렇게 생각하자:
“전구가 켜지는 정확한 스위치 상태 목록이 있다.”
Quine–McCluskey는 뭐냐?
컴퓨터가 규칙만 가지고 자동으로 조건을 합치는 방법이다.
규칙은 단 하나:
전구가 켜지는 두 경우가
스위치 하나만 다르면,
그 스위치는 중요하지 않다.
1️⃣ 첫 번째 합치기 (스위치 1개만 다른 경우)
경우 1 vs 경우 2
- A: 둘 다 꺼짐
- C: 둘 다 켜짐
- B만 다름
B는 중요하지 않다
“A는 꺼져 있고, C만 켜져 있으면 된다”
이 조건 하나로
- (A=0, B=0, C=1)
- (A=0, B=1, C=1)
두 경우를 한 번에 설명 가능
경우 1 vs 경우 3
- B: 둘 다 꺼짐
- C: 둘 다 켜짐
- A만 다름
A는 중요하지 않다
“B는 꺼져 있고, C만 켜져 있으면 된다”
이 조건 하나로
- (A=0, B=0, C=1)
- (A=1, B=0, C=1)
두 경우를 한 번에 설명
경우 2 vs 경우 3
- A도 다름
- B도 다름
스위치 두 개가 다르면
QM 규칙상 합치기 불가
2️⃣ 더 합칠 수 있는지 다시 본다
지금 남은 조건은 두 개:
- 조건 X: “A는 상관없고, B는 꺼져 있으며, C는 켜짐”
- 조건 Y: “A는 꺼져 있고, B는 상관없으며, C는 켜짐”
이 둘을 비교해보면:
- A도 다르고
- B도 다름
스위치 두 개가 다르므로
더 이상 합칠 수 없다
3️⃣ 최종적으로 남는 설명
그래서 전구가 켜지는 조건은:
C가 켜져 있고,
A가 꺼져 있거나
B가 꺼져 있으면 된다
즉, F = C(A' + B')
이게 Quine–McCluskey의 본질
- ✔️ 모든 “켜지는 경우”를 빠짐없이 나열
- ✔️ 딱 한 스위치만 다른 경우를 자동으로 합침
- ✔️ 더 이상 합칠 수 없으면 멈춤
- ✔️ 남은 조건이 최소 논리
전구가 켜지는 경우 중에서
스위치 하나만 바꿔도 여전히 켜지면,
그 스위치는 신경 쓸 필요 없다.
이걸 규칙으로 끝까지 밀어붙이는 방법이 Quine–McCluskey다.
Quine–McCluskey(QM)는 계산량이 “지수폭발”한다.
변수 조금만 늘어나도, 컴퓨터가 감당 못 한다.
왜냐? 경우의 수가 미쳤다
변수 개수를 n이라 하면,
- 가능한 입력 경우: 2ⁿ
- minterm 최대 개수: 2ⁿ
예:
- 6변수 → 64개
- 10변수 → 1,024개
- 15변수 → 32,768개
- 20변수 → 1,048,576개
QM은 “켜지는 경우를 전부 다룬다”
이 단계에서 이미 끝장이다
2️⃣ QM은 “모든 쌍 비교”를 한다
QM의 본질은 이거다:
“이 minterm이랑 저 minterm이랑 딱 1비트만 다른가?”
즉,
- minterm이 M개면
- 비교 횟수 ≈ M²
예:
- 1,000개 → 100만 번 비교
- 10,000개 → 1억 번 비교
- 30,000개 → 9억 번 비교
3️⃣ 진짜 지옥은 “Prime Implicant 선택”
QM의 최악 파트는 마지막이다.
- Prime implicant 수가 많아짐
- “이걸로 모든 minterm을 덮을 수 있나?”를 탐색
- 이건 Set Cover 문제
NP-hard, 경우의 수를 다 봐야 답이 나온다
SAT란?
SAT(Boolean Satisfiability)는 딱 이 질문이다.
“이 논리식이 TRUE가 되게 만드는 입력 assignment가 하나라도 존재하나?”
있으면 SAT, 없으면 UNSAT.
핵심은 Yes/No(존재) 문제라는 점.
왜 SAT는 실무에서 잘 되는데, Optimization은 계속 힘든가?
여기서부터가 많은 사람이 헷갈리는 지점인데, 결론은 간단하다.
(1) SAT는 decision(존재)라서 “하나 찾으면 끝”
- SAT solver는 해 하나만 찾으면 종료한다.
- UNSAT이면 “불가능”을 보여주는 증명(실무에선 conflict-driven 학습)이 쌓이면서 가지치기가 강해진다.
- 그래서 전체 경우의 수를 보지 않더라도, early exit가 자주 일어난다.
(2) Optimization은 “최적성 증명”이 필요해서 끝이 안 난다
Optimization의 진짜 요구는 이거다.
“더 좋은 해가 존재하지 않음을 증명하라.”
즉,
- 처음보다 괜찮은 해를 찾는 건 시작일 뿐
- 그보다 더 좋은 해가 없다는 것을 보여야 “global optimal”이라고 말할 수 있다
이게 어려운 이유는, 결국 조합 공간을 광범위하게 배제해야 하기 때문.
우리가 아까 본 3개의 전구 예시만으로도, 여러번의 계산이 나왔다. 그런데 2020년 이후 설계되고 있는 스마트폰 반도체를 보면, 100억개가 넘는 Transistor가 들어간다.
(3) SAT로 Optimization을 푸는 표준 트릭이 있는데, 그게 바로 “반복”이라 무겁다
Optimization을 SAT로 바꾸는 전형적 방식:
- “cost ≤ k” 같은 bound를 걸고 SAT를 푼다
- 되면 k를 더 줄여서 다시 SAT
- 안 되면 k를 늘리거나 멈춘다 (= binary search/iterative tightening)
즉, SAT를 한 번 푸는 게 아니라 여러 번 푼다. 게다가 k가 작아질수록 constraint가 빡세져서 더 어려워지는 경우가 많다.
(4) EDA는 보통 single-objective가 아니라 더 더럽다
실무 EDA는 대개:
- Timing / Area / Power / Congestion / Routability … 같이 multi-objective
- constraint도 corner/mode 등으로 다중 조건
- 비용함수도 연속이 아니라 “툭툭” 바뀌는 rugged landscape
그래서 “최적”이라는 단어는 더 위험해진다.
대부분은 “best-found / improved over baseline”이 정직한 표현이다.
“Enumeration vs Optimization”의 차이
- SAT(존재 문제): “만족하는 해가 하나라도 있나?” → 하나 찾으면 종료 가능
- Optimization(최적화 문제): “최소/최대가 맞나?” → 더 좋은 해가 “없음”을 증명해야 끝
즉,
최적화는 값 찾기가 아니라 부재 증명(no better solution)을 요구한다.
QM은 covering table의 크기가 너무 크다.
- minterms 수가 대략 ~ (2^n) (rows)
- primes 수가 대략 ~ (3^n/n) (columns)
- 그리고 minimum covering은 NP-complete
여기서 무슨 일이 생기냐면:
- 경우의 수가 많다
- 그 많은 prime 중에서 “최소 조합”을 고르는 순간 조합 폭발이 시작된다
그래서 QM은 “정확한 최소”를 주는 대신, 스케일이 올라가면 산업 현장에서 쓰기 어렵다.
그래서 산업 현장에서는 heuristic: “최적” 대신 “충분히 좋고 안정적인” 해
- 공짜로 확정되는 경우의 수부터 고정: essential prime
- 경우의 수 테이블 자체를 줄인다: dominance / equality
- 끝까지 남는 핵심 경우의 수: cyclic core
다 줄이고도 남는 “고리”가 cyclic core다.
여기부터는 대개:
- branch-and-bound
- “좋은 bound”를 만드는 heuristic으로 푼다.
휴리스틱 품질은 “50%” 같은 숫자로 말하기 어렵다
Global optimal을 모르면 “optimal 대비 50%”가 성립하지 않는다.
대신 실무 EDA는 보통 아래로 평가한다.
- PPA: Area/Power/Timing(WNS/TNS 등) 절대 값이 현대 방법론 대비 좋아졌나?
- Baseline(As Is v.s. To be) 대비 개선: 이전 run/옵션/툴 대비 얼마나 나아졌나
- Robustness: seed/corner 변경에도 결과가 안정적인가
- Runtime 대비 효율
반도체 설계 평가를 할 때 가져야 할 기본 태도: 의심
논문에서 “global optimum”, “optimal solution”를 보면, 아래 체크리스트를 확인해야한다.
체크리스트:
- 최적성 보장 증명이 실제로 있나?
- 문제 크기 (n)이 얼마인가?
- 비교가 heuristic baseline 대비인가, “optimal” 대비인가?
- objective가 뭔가? (Timing만? Area만? Power만?)
- seed 반복/분산이 있는가? (robustness 확인)
- 그래서 재현 가능한가?
결론: EDA에서 어려운 건 “계산”이 아니라 “최적성 증명”
Two-Level Logic Minimization은 좋은 교육용 예제다.
왜냐면 NP-complete covering 한 방으로, EDA 전반(placement / routing / scheduling / …)의 현실을 쉽게 유도해볼 수 있으니까.
EDA는 공학이다.
목표는 “빠르고, 안정적이며, 지표 개선”.