Quando você chega ao laboratório DFT pela primeira vez depois de trabalhar em design lógico, há um ponto em que você fica mais confuso.
Scan, ATPG, padrão preso, padrão de transição, etc. são familiares, mas no momento em que você vai para o lado da memória, você de repente fala sobre algoritmo de março, MBIST, modelo de falha.
E mesmo os engenheiros seniores de DFT ficam por vezes confusos com isto:
"Que falhas cobre exatamente o March C-? Quais são as suas desvantagens?"
"Porque é que tem de subir e descer duas vezes?"
O objetivo deste artigo é simples.
- Para as pessoas que já estão familiarizadas com DFT/ATPG, mas testes de memória são estranhos, eu quero explicar o que é o algoritmo de março e porque ele funciona nessa ordem,
- O que o torna fundamentalmente diferente do padrão de teste lógico
- E qual o papel do padrão de tabuleiro de verificação, que é frequentemente ouvido na prática
1. Teste lógico vs. teste de memória: por que os padrões são diferentes?"
1.1 Lado lógico: o mundo do Scan + ATPG
Um bloco lógico típico é testado assim.
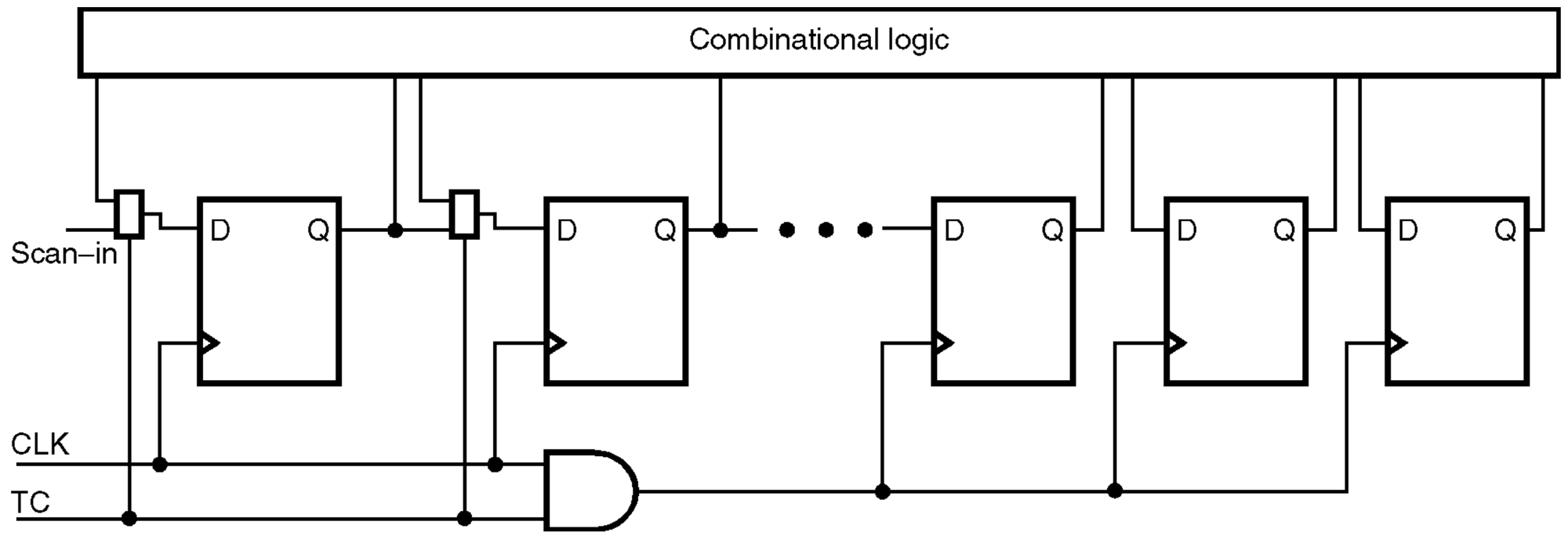
- Inserindo uma cadeia de varredura
- ferramenta ATPG nos flip-flops na falha travada, Criar um vetor de teste visando a falha de transição
- No equipamento ATE ou na placa
- injetar valores na porta de entrada + scan-in (scan shift)
- captura
- observar valores com scan-out
Há três pontos-chave.
- A falha é definida em termos de flip-flops (células de varrimento):
- Padrão de teste Um vetor estimula múltiplos nós simultaneamente.
- Ativação da falha → propagação → observação flui através de um caminho lógico combinatório.
Assim, a filosofia do teste lógico é:
"Cobrir o maior número possível de falhas com um único padrão."
O que fazemos na ATPG é mais uma implementação matemática/algorítmica dessa filosofia:
1.2 Lado da memória: A estrutura é completamente diferente
Pelo contrário, a estrutura da SRAM como memória é a seguinte:
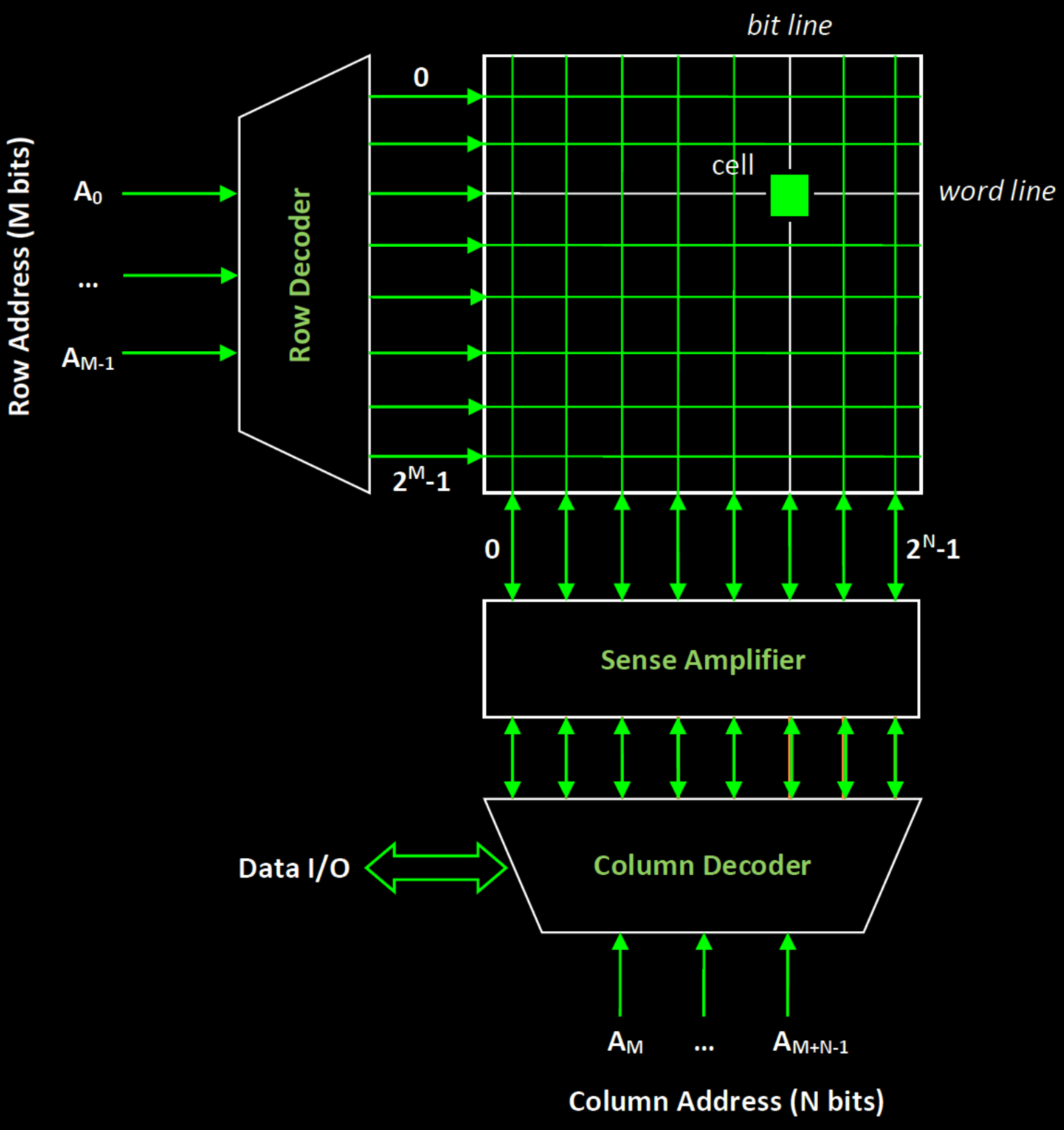
- Decodificador de endereços: ativa a linha de palavras do endereço selecionado
- Par de linhas de bits + célula: lê ou escreve os dados da célula selecionada
- geralmente, só é possível aceder a uma linha de endereços de cada vez
Esta estrutura conduz a algumas caraterísticas importantes dos testes de memória.
(1) Granularidade de acesso
- Lógica: Testar múltiplos flip-flops / nós de uma só vez
- Memória: Acesso normalmente "um endereço de cada vez"
(2) O modelo de falha em si é diferente
- Logic: gate/net-centric
- Memória:
- Falha na própria célula
- Interação entre células
- Anormalidade do descodificador de endereços
- Sensível ao padrão da célula circundante
Mesmo que se olhe para um modelo representativo de falha de memória, já é diferente.
- Defeito de acoplamento (CF)
- Defeito do descodificador de endereços (AF)
- Defeito sensível ao padrão de vizinhança (NPSF)
- Defeito destrutivo de leitura/escrita, etc.
(3) Dependência de sequência
Algumas falhas só se revelam na sequência seguinte, por exemplo.
Escreva um 1 nesta célula → escreva um 0 numa célula vizinha → leia a célula original novamente para quebrá-la.
Em outras palavras, "em que ordem e quando as células vizinhas têm quais dados" é importante.
Portanto, a memória é muito mais adequada para um algoritmo que repete uma sequência de leitura/escrita, passando por todas as células em alguma ordem, em vez de um vetor ATPG que abre vários nós de uma vez.
Esse é o algoritmo de março, literalmente, a idéia de marchar através do espaço de endereço em uma única linha de arquivo.
2. March Algorithm의 핵심 아이디어
2.1 Definição: Teste enquanto "marcha" pelos endereços
O algoritmo March pode ser resumido em uma linha.
Um algoritmo de teste que "marcha" por todos os endereços da memória numa determinada direção (↑, ↓, ou ambas), executando uma sequência pré-definida de operações de leitura/escrita em cada endereço
A notação tem normalmente o seguinte aspeto
↑: sequência de endereçamento crescente↓: sequência de endereçamento decrescente↕: crescente ou decrescente, independente da direção (cada endereço uma vez)wx: escreve o valor x (w0,w1)rx: lê & verifica o valor x (r0,r1)
Por exemplo:
↑ (w0) : escreve 0 em cada célula do endereço 0 ao MAX
↑ (r0, w1): novamente do endereço 0 ao MAX, lê se 0 (r0) e escreve 1
Esta "sequência direção + operação" é designada por elemento de marcha.
Uma sequência de vários elementos é designada por teste de marcha.

2.2 "Não pode ser apenas w0→r0, w1→r1 duas vezes?"
Para toda a memória
w0→r0 → w1→r1
Será que isto é tudo o que precisamos de testar?"
O problema é o modelo de falhas de memória:
- Algumas falhas só são reveladas pela transição 0→1, algumas falhas são reveladas pelo estado da célula vizinha.
- Algumas falhas não têm problemas na travessia de endereços na direção ascendente mas causam problemas na direção descendente.
- Por exemplo, certos caminhos de descodificadores, estruturas de acoplamento, etc.
Portanto, o algoritmo de março impõe o seguinte.
- Fazer com que cada célula experimente 0 e 1 várias vezes
- realize as transições 0→1 e 1→0
- passar pelas direcções para cima e para baixo e alterar a sua ordenação relativa com os seus vizinhos.
Existem muitos algoritmos em uso que fazem isso em uma única passagem e ainda mantêm o tempo de teste em O(N).
- Falhas de célula única
- Falhas de acoplamento de 2 células
- Falhas de decodificador de endereço
Então, quais algoritmos de março são populares na prática?
3. Se nos lembrarmos apenas de dois: March X & March C-
3.1 março X - O mais simples básico para fins didácticos
março X é um dos algoritmos mais básicos de março. Ele costuma ser escrito assim:
1) ↑ (w0)
2) ↑ (r0, w1)
3) ↑ (r1, w0)
O que isto significa:
- Inicializar todas as células para 0 (
↑(w0)) - Na volta para cima
- ler se é 0 e escrever (
r0) - 1. (
w1)
- ler se é 0 e escrever (
- Na subida mais uma vez,
- lê se é 1 e escreve (
r1) - escreve 0 (
w0)
- lê se é 1 e escreve (
É isso:
- Toda célula armazena 0 e 1 pelo menos uma vez
- Toda transição 0→1 e 1→0 é realizada
- As falhas básicas Stuck-at fault e Transition fault são mais ou menos detectáveis
As limitações são óbvias.
↓não há travessia direcional- Falhas de acoplamento, Falhas de descodificador de endereços têm cobertura limitada.
Como resultado, é frequentemente utilizado para ilustração concetual, formação e SRAMs muito simples, enquanto os MBISTs reais utilizam algoritmos mais poderosos.
3.2 March C- - O padrão mais comum na prática
March C- é o que aparece com mais frequência nos MBISTs na prática.
Na realidade, os projectistas de SRAM conceberam muitos mais algoritmos do que este, e há muitos nomes diferentes de March, mas um número significativo são famílias derivadas de March C-.
March C- é geralmente definido da seguinte forma:
1) ↕ (w0)
2) ↑ (r0, w1)
3) ↑ (r1, w0)
4) ↓ (r0, w1)
5) ↓ (r1, w0)
6) ↕ (r0)
Aqui, ↕ pode ser entendido como "cada endereço uma vez", independente da direção.
Para decompor um pouco mais:
- Escreva 0 em cada célula. (Inicializar)
- Com o endereço acima
- lê se for 0 (
r0) - escreve 1 (
w1)
- lê se for 0 (
- acima novamente. e leia (
r0) - escreva 1 (
w1) - Role para baixo novamente e leia
- 1 e escreva (
r1) - 0 (w0)
- 1 e escreva (
- Finalmente, percorra todo o conjunto uma última vez e leia
- 0 (r0)
Este conjunto contém tudo o que se segue
- Cada célula experimenta 0 e 1 múltiplas vezes
- repete a transição
- realiza travessias tanto para cima como para baixo
- cria deliberadamente situações em que o estado das células vizinhas muda imediatamente após a leitura, ou em que resta vestígios do padrão anterior
É por isso que o March C- consegue detetar bastante bem o seguinte.
- Falha de atrito (SAF)
- Falha de transição (TF)
- A maioria das falhas do descodificador de endereços (AF)
- Uma típica 2.célula Falha de acoplamento (CF)
No BIST real de memória ao nível do produto, a combinação "Marcha C- (ou variante derivada)" + fundo adicional é quase a predefinição.
4. March X vs March C- de uma perspetiva de modelo de falha
Para ter uma ideia, vamos comparar os dois de uma perspetiva de modelo de falha.)
O resumo prático é simples:
- Conceitos básicos explicados no laboratório → March X
- BIST de memória ao nível do produto no mundo real → quase March C- (ou uma variante derivada de C-)
.