Antigamente, "quantos nanos de processo, quantos núcleos" pareciam descrever a maior parte do desempenho dos semicondutores.
Atualmente, palavras como chiplet, 2,5D, 3D IC e UCIe são as primeiras palavras que vêm à mente.
Não é só porque são palavras da moda.
Não é só porque são palavras da moda, mas porque as interconexões entre a matriz e a matriz agora determinam o desempenho, a potência e o custo de todo o chip, e não apenas o interior da matriz.
Uma startup superou a Nvidia, mas... Nenhum outro semicondutor pode superar o desempenho + potência + onipresença + rendimentos de produção em massa da Nvidia no mercado mais amplo.
O gráfico abaixo foi compilado por Amir do riselab.
O eixo x é o ano e o eixo y é o desempenho.
O preto é a inclinação da melhoria do desempenho para semicondutores de sistema > Semicondutores de memória > Interligações > Inclinação da melhoria do desempenho
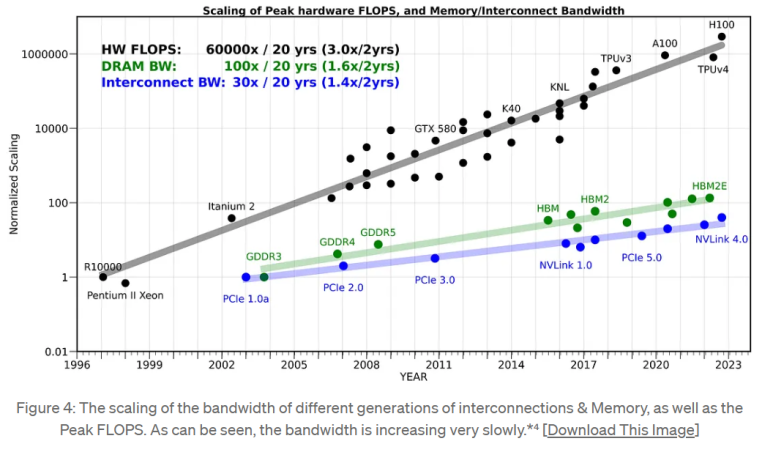
Ao nível da placa, acaba-se por utilizar as três, mas por mais rápidas que sejam as GPUs, elas são o estrangulamento para outros semicondutores devido à sua pequena largura de banda.
Assim, tornou-se um grande desafio para as empresas de semicondutores de IA adquirir o maior número possível de HBMs com a maior largura de banda de memória."
Os HBMs têm feito subir os preços das acções da SK Hynix (a maior empresa de tecnologia do mundo), da Samsung Electronics (a maior empresa de produção do mundo) e da Micron (a maior empresa de memórias dos EUA).
Mas... Mais lento do que a memória é a interconexão.
Eu costumava pensar que "Chiplet = chip grande dividido e colado", mas quanto mais eu olho para ele, mais eu acho que o próximo jogo de semicondutores será ganho ou perdido pela interconexão.
O processo é melhor, então por que dividir o chip
Para falar sobre Chiplet, precisamos começar com "por que abandonamos os SoCs monolíticos?"
Primeiro, Limitação do tamanho do retículo.
Desenhamos uma máscara esquemática com uma máquina de exposição (ASML), e há uma área máxima que esta máquina pode desenhar um circuito. Se desenharmos uma CPU, uma GPU e um acelerador de IA de alto desempenho numa única matriz gigante, estaremos perto deste limite. Para além deste ponto, a própria conceção torna-se mais complexa e os rendimentos diminuem drasticamente.
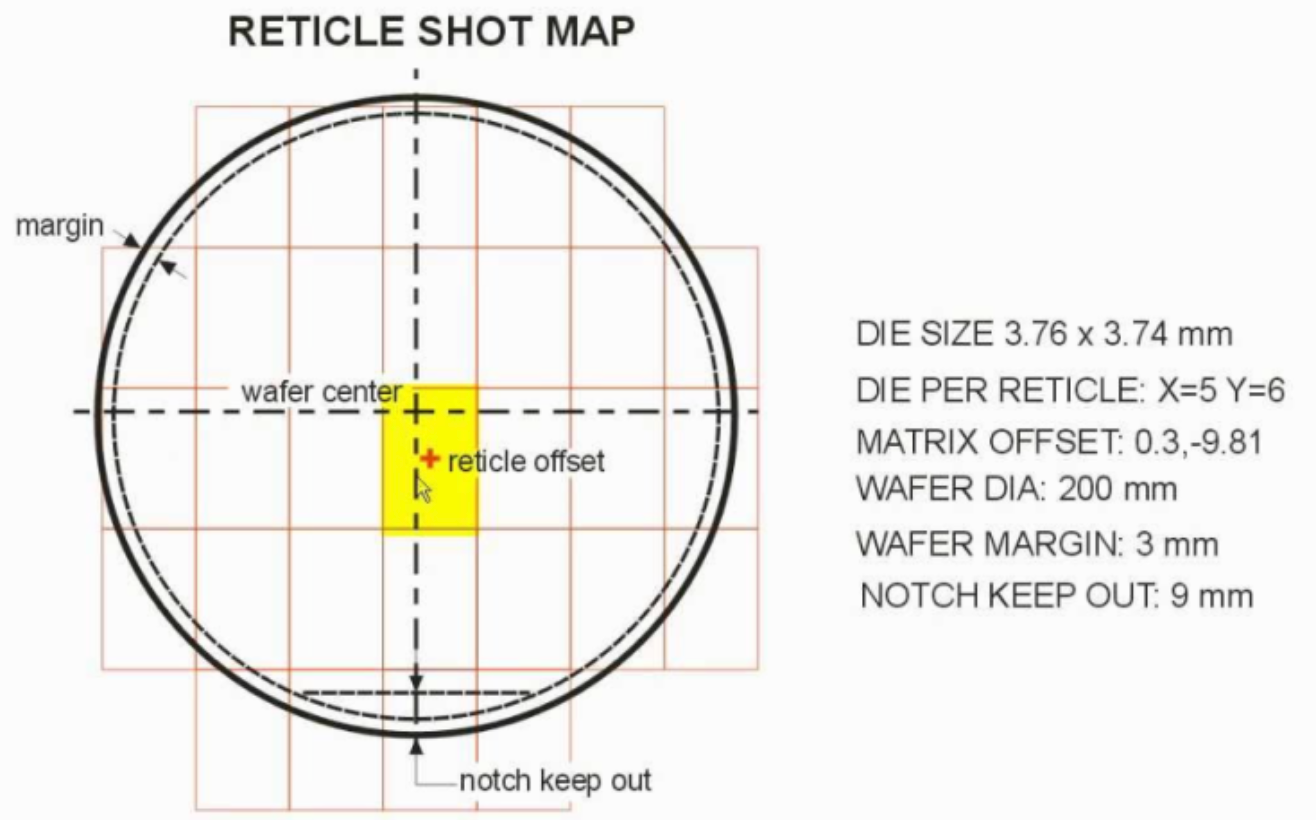
Segundo, rendimento e estrutura de custos.
Quanto maior for a área, maior será a perda de "um mau exemplar". Se tivermos uma matriz de 800 mm² e um pedaço de pó ficar preso, toda a pastilha está estragada e temos de a deitar fora, ao passo que se tivermos quatro peças de 200 mm², se uma peça estiver estragada, as outras três podem ser utilizadas para outras combinações. Estatisticamente, a estrutura das pastilhas é muito mais favorável. Quanto mais fino for o processo, mais elevado é o preço de um dado, pelo que a diferença se faz sentir mais fortemente.
https://semiengineering.com/designs-beyond-the-reticle-limit/
Terceiro, integração heterogénea.
Os SoCs actuais têm CPU, NPU, GPU, SerDes de alta velocidade, DDR/LPDDR/PHY, analógico, RF, gestão de energia e muito mais. Nem sempre é melhor implementar todos os blocos no mais recente processo FinFET/GAA. A lógica digital beneficia de processos de ponta, mas a analógica e a E/S são mais fiáveis e mais baratas em processos maduros."
O resultado final é "fazer cada bloco no melhor processo e depois combiná-los num pacote". As palavras-chave aqui são 2,5D, ICs 3D e chiplets.
Resumindo, os chiplets são "uma estrutura para contornar as limitações do processo, controlar o rendimento e o custo e misturar diferentes processos num único pacote". O problema é que, uma vez que você o dividiu, é muito mais difícil descobrir como conectar os pontos.
Mas... Chiplet parece bom por causa do rendimento e da estrutura de custos,
mas o processo de fabricação de CIs 2.5D e CIs 3D é complicado, então o rendimento pode ser baixo, e você precisa gastar muito dinheiro para compensar isso, então você pode acabar com uma barriga maior do que seu estômago.
É por isso que ainda não se vê muita produção em massa.
On-Die Wire to Die-to-Die Link
Num SoC monolítico, a maior parte dos dados flui por cima da camada metálica on-die. Até mesmo os fios globais ainda são fios no silício, enviando e recebendo sinais com centenas de ps a alguns ns de atraso e energia relativamente baixa.
Por mais importante que seja o projeto de rede no chip (NoC), o roteamento físico em si é mais um problema "no chip".
Assim que você chega à estrutura do chiplet, você tem dados críticos saindo do dado e voltando. Em outras palavras, o caminho muda da seguinte forma:
Core → On-Die NoC → Die Edge → Micro Bump → Interposer ou RDL → Micro Bump em outro die → On-Die NoC → Core
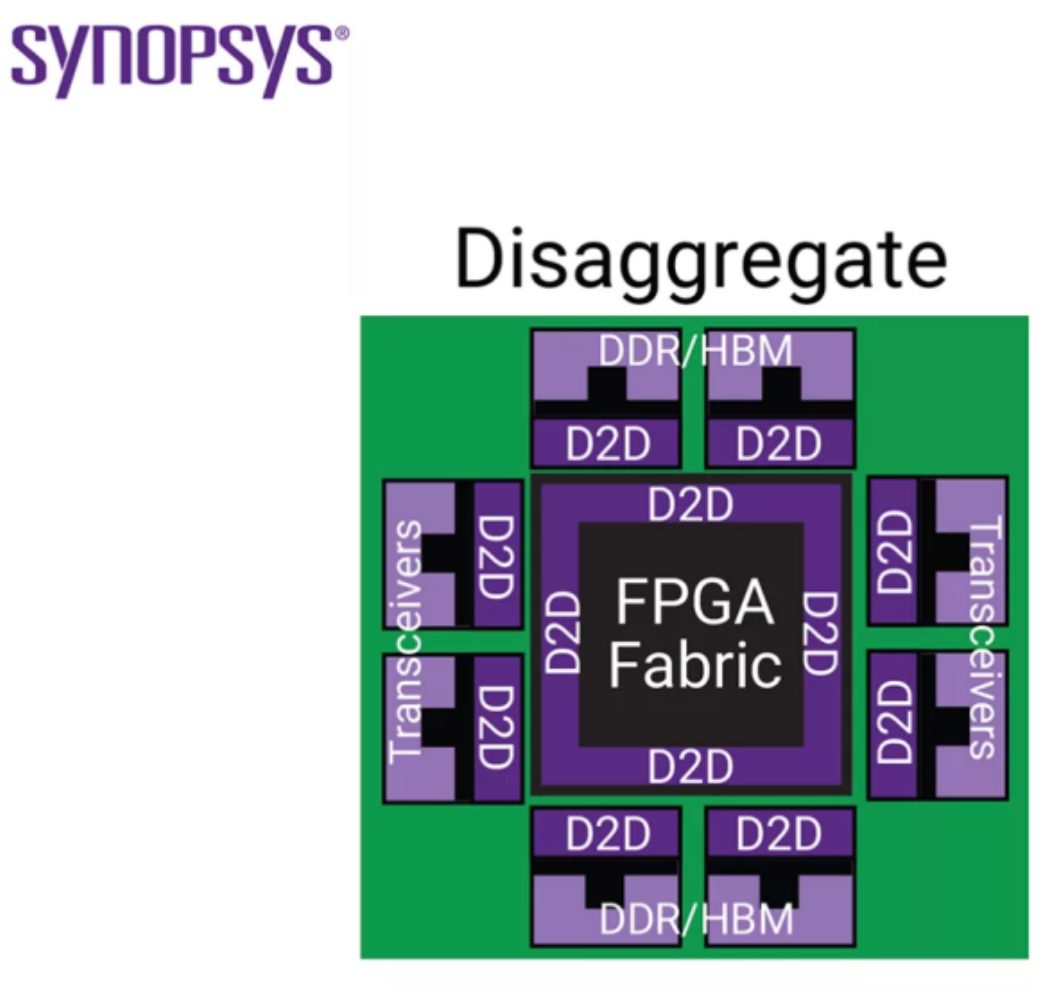
De uma perspetiva física, algumas coisas mudam.
O meio da cablagem muda
Agora não estamos apenas a lidar com uma camada metálica sobre silício, mas estamos a passar por uma variedade de meios, incluindo micro saliências, TSVs, interpositores de silício, RDLs fan-out e substratos orgânicos.
Comprimento e mudança de ambiente
É muito mais comprido do que o fio no disco, e a impedância é mais complexa. As questões de integridade do sinal entram em jogo. O "muro" entre o pacote tradicional SerDes e o fio on-die é quebrado, e as preocupações muito avançadas ao nível do design SerDes entram no pacote.
O preço da energia e da área muda
O custo de adicionar mais um fio on-die não é o mesmo que o custo de adicionar mais uma ligação die-to-die. O comprimento da borda da matriz é limitado e o passo da colisão é limitado. À medida que se aumenta o número de ligações, a área do perímetro da matriz, a área da célula PHY, o roteamento e a potência são afetados.
Roteamento e potência
O que costumava ser um projeto do tipo "podemos usar um pouco mais de fio" agora é um projeto do tipo "essa ligação realmente vale a largura de banda?
A partir deste ponto, a interconexão não é mais apenas uma fiação física, mas um recurso fundamental que determina a arquitetura de todo o sistema Chiplet.
A interconexão Chiplet de uma perspetiva PPA
No final das contas, todo projeto se resume a PPA (potência, desempenho, área) e custo. A Chiplet Interconnect está profundamente envolvida em todos os quatro pilares.
Desempenho: Largura de banda e latência
Há uma enorme quantidade de dados fluindo entre aceleradores de IA, GPUs, CPUs de alto desempenho e memórias de alta largura de banda, como HBMs. Quando esses dados fluem por um link die-to-die, em vez de on-die, a densidade da largura de banda e a latência de ida e volta do link determinam o limite superior do desempenho do sistema.
Se não houver largura de banda suficiente, não importa quantos núcleos você adicione, você atingirá uma "parede de memória". E se a latência for demasiado elevada, a colaboração de grão fino torna-se difícil e a arquitetura tem de ser concebida com grão grosso. Por exemplo, se o cache L3 for separado em chiplets e a latência for muito grande, ele se tornará quase como uma memória fora do chip.
Potência: lutando por pJ/bit
Os fios on-die podem comprimir a potência até dezenas de fJ/bit, mas os SerDes baseados em pacotes custam frequentemente vários pJ/bit. Os PHYs de curto alcance e ultrabaixo consumo de energia para chiplets também têm como objetivo sub-pJ/bit, mas continuam a ser mais caros do que os on-die."
No final do dia, como arquiteto de sistemas, temos de nos perguntar: "Quero mesmo enviar estes dados através do die, ou quero computá-los mais uma vez no die e comprimi-los?"
E o preço da energia da interligação não é o mesmo. À medida que o preço da energia da interconexão muda, o trade-off computação x comunicação também muda.
Area: Die Edge and PHY Area
A interconexão de chiplets é "centrada na borda". O Bump e o PHY são colocados ao longo do perímetro da matriz. Aumentar o tamanho da matriz aumenta não só a área do núcleo, mas também o comprimento da borda, mas a eficiência com que a borda é alocada à interconexão afeta diretamente o PPA.
Particularmente ao usar uma interface padronizada de matriz para matriz, como a UCIe, a área ocupada pelo PHY, controlador e pilha de protocolos não pode ser ignorada. Reduzir a área e a potência necessárias aqui é a vantagem competitiva do design de chiplets.
Cost: Combinação de processos e complexidade do pacote
Com uma estrutura de chiplet, é possível reduzir o custo unitário da matriz dividindo a lógica em processos de ponta e a E/S em processos maduros. O problema é o custo da embalagem. Os interpositores de silício, o RDL de alta densidade e os bumps de passo fino são muito caros. Os requisitos excessivos de interconexão complicam a estrutura do pacote e aumentam o custo global."
Assim, a interconexão torna-se o barómetro que determina "esta arquitetura chiplet faz sentido em termos económicos?
UCIe, e a normalização das interfaces Die-to-Die
Uma das palavras-chave mais faladas atualmente é UCIe (Universal Chiplet Interconnect Express). Embora o nome tenha um toque de PCIe, o seu objetivo é, na verdade, proporcionar compatibilidade com protocolos existentes, como PCIe/CXL, bem como PHYs especializados para ambientes die-to-die.
A razão para a UCIe é clara. Os chiplets de diferentes empresas podem ser combinados
O ecossistema de chiplets nunca cresceria se cada empresa se mantivesse fiel à sua própria interface proprietária de matriz para matriz. Só quando existe uma "interface padrão que qualquer pessoa pode combinar" é que se pode realmente ter projetos "pré-fabricados" no nível do SoC.
Os benefícios da padronização são óbvios: por exemplo, uma empresa pode fazer um chiplet de CPU, outra um chiplet de NPU, outra um chiplet SerDes/IO, e uma empresa de sistemas pode combiná-los em um pacote. Na realidade, é claro, não é assim tão simples devido a questões de propriedade intelectual, validação e responsabilidade. Mas o fato de ser um "cenário possível" é uma grande mudança.
EDA e Design Flow são limpos
Em vez de ter que modelar novos PHYs e protocolos proprietários todas as vezes, os modelos de canal e link baseados em UCIe podem ser usados como uma base comum. Existe um denominador comum para STA, SI, PD e Package Co-Design Flow.
Por outro lado, ter um padrão também significa que "a própria interconexão se torna um ponto de competição". A empresa com o IP PHY, a estrutura do pacote e a tecnologia de co-otimização que pode fornecer melhor potência/largura de banda/latência/área ganhará o mercado.
A indefinição entre o design do pacote e do chip
Outra razão pela qual a interconexão de chiplets é tão importante é o facto de quebrar as "fronteiras do design".
No passado, a divisão era mais ou menos a seguinte:
In-die: Design Lógico, Design Físico, STA, SI On-Die
Pacote: Concebido pela equipa PCB/Pacote separadamente e a velocidades muito mais baixas
Numa estrutura chiplet, os dois são completamente indivisíveis. Os canais no Die-to-Die Link olham para as estruturas de borda do pacote e da matriz simultaneamente. A colocação do molde, o mapeamento de bump, o roteamento do interposer, o empilhamento do pacote e a colocação do PHY dentro do molde precisam ser abordados de uma só vez."
No final do dia, essas questões se juntam como uma equipe.
A que distância os chiplets A e B devem ser colocados
Quanto comprimento de canal pode ser permitido no interpositor
Em que ordem as saliências devem ser colocadas na borda do dado
Onde o NoC no dado e o link entre os dados devem ser limitados
É aqui que o engenheiro de pacotes, o engenheiro de PD, o engenheiro de SI, o arquiteto de sistemas e o fornecedor de ferramentas de EDA se sentam à mesma mesa.
À medida que os chiplets se generalizam, as perspectivas exigidas dos projetistas mudarão:
Não apenas "entender alguns nanos do processo"
A capacidade de entender as camadas física, lógica e de protocolo da interconexão em conjunto
A visão em nível de sistema da NoC on-die e da malha off-die como um todo integrado
A capacidade de analisar os trade-offs de ponta a ponta, incluindo potência/área/custo
Estas três coisas se tornarão cada vez mais importantes.
Pode estar a pensar: "Ainda há muito a fazer com transístores, lógica, PDs e STAs, e depois há a interligação e o pacote." Mas é melhor entrar no projeto sabendo, pelo menos, "onde estão os verdadeiros estrangulamentos que determinam o desempenho e o custo do chip". Hoje em dia, esse gargalo é muitas vezes a interconexão."
Do meu ponto de vista, a interconexão na era do chiplet não é um tópico a ser evitado, mas sim uma grande oportunidade de expandir sua carreira. Assim que se compreende a interconexão entre chips, o empacotamento e a sincronização, passa-se a ser uma pessoa que trabalha com chips inteiros. O âmbito do que se pode fazer é muito mais alargado."