Раньше слова "сколько нанотехнологий, сколько ядер", казалось, описывали большую часть производительности полупроводников.
Сейчас такие слова, как чиплет, 2,5D, 3D IC и UCIe, - первые, которые приходят на ум.
И это не только потому, что они звучат как "buzzwords".
Стартап опередил Nvidia, но... Ни один другой полупроводник не сможет превзойти Nvidia по производительности + мощности + повсеместности + массовости производства на более широком рынке.
Приведенный ниже график составлен Амиром из riselab.
Черным цветом показан наклон повышения производительности для системных полупроводников > Полупроводники памяти > Интерконнекты > Наклон повышения производительности
figure class="kg-card kg-image-card kg-card-hascaption">
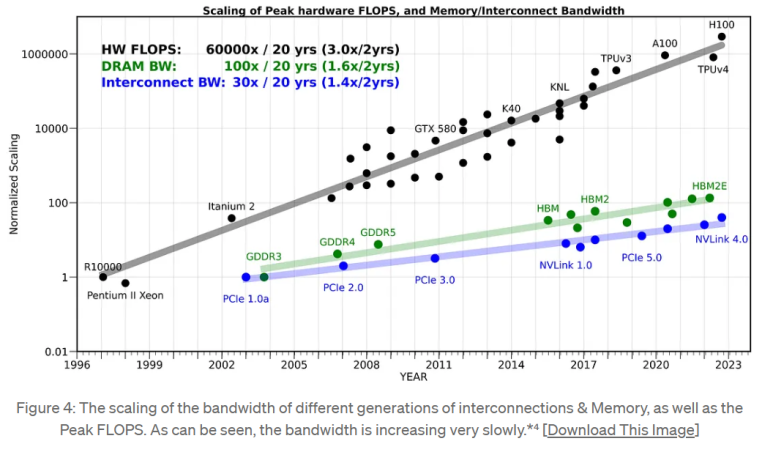
https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
На уровне платы в конечном итоге будут использоваться все три, но какими бы быстрыми ни были GPU, они являются узким местом для других полупроводников из-за своей небольшой пропускной способности.
Таким образом, для полупроводниковых компаний ИИ стало большой проблемой приобрести как можно больше HBM с наибольшей пропускной способностью памяти."
HBM способствовали росту цен на акции SK Hynix (ведущей технологической компании в мире), Samsung Electronics (ведущей производственной компании в мире) и Micron (ведущей компании по производству памяти в США).
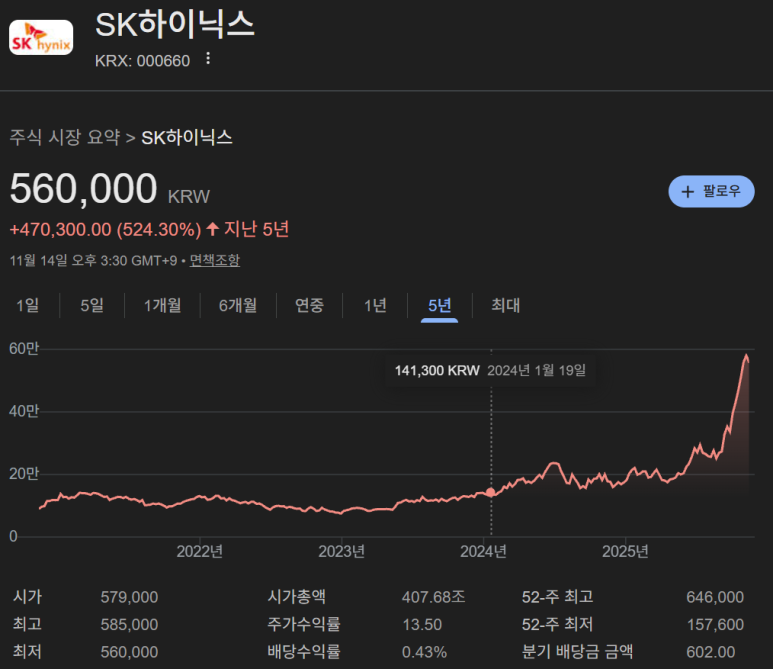
Но... Медленнее, чем память, работает межсоединение.
Раньше я думал, что "чиплет = большой чип, разделенный и склеенный", но чем больше я в это вникаю, тем больше думаю, что следующая полупроводниковая игра будет выиграна или проиграна межсоединением.
Процесс лучше, но зачем разделять чип
Чтобы говорить о Chiplet, нужно начать с вопроса "почему мы отказались от монолитных SoC?".
Во-первых, ограничение размера ретикулы.
Мы рисуем схемную маску с помощью экспонирующей машины (ASML), и существует максимальная площадь, которую эта машина может нарисовать для схемы. Если вы проектируете высокопроизводительный CPU, GPU и ускоритель искусственного интеллекта на одной гигантской матрице, вы будете близки к этому пределу. За этим пределом сама конструкция становится сложнее, а производительность резко падает.
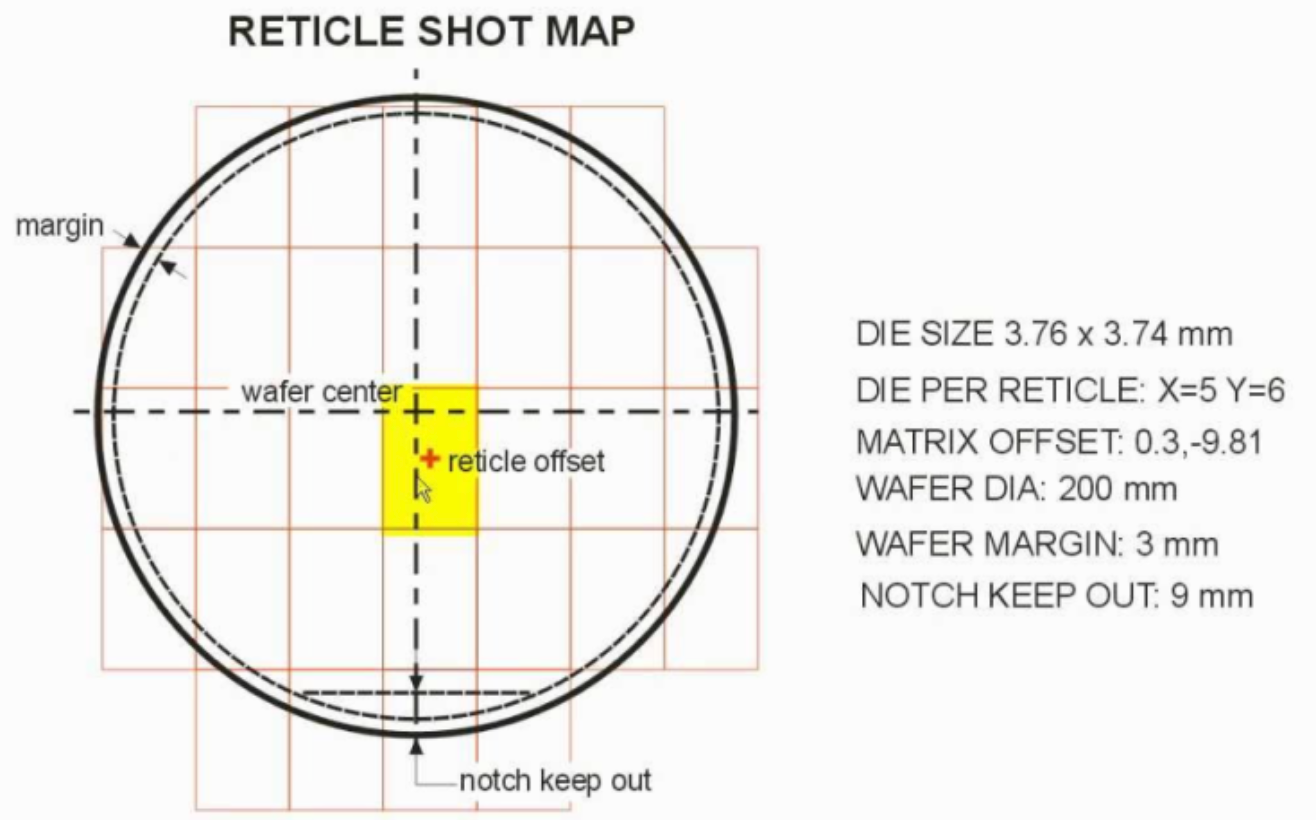
Второе, выход и структура затрат.
Чем больше площадь, тем больше потери от "одного плохого". Если у вас есть матрица площадью 800 мм² и в ней застрял один кусочек пыли, весь чип будет плохим и его придется выбросить, в то время как если у вас есть четыре детали площадью 200 мм², если один кусочек будет плохим, остальные три можно использовать для других комбинаций. Статистически структура чиплета гораздо более благоприятна. Чем тоньше техпроцесс, тем выше цена матрицы, поэтому разница ощущается сильнее.
https://semiengineering.com/designs-beyond-the-reticle-limit/
Третье, гетерогенная интеграция.
Современные SoC содержат CPU, NPU, GPU, высокоскоростные SerDes, DDR/LPDDR/PHY, аналоговые, RF, управление питанием и многое другое. Не всегда лучше реализовать каждый блок в новейшем техпроцессе FinFET/GAA. Цифровая логика выигрывает от передовых техпроцессов, но аналоговые устройства и устройства ввода-вывода надежнее и дешевле на зрелых техпроцессах."
В итоге получается: "Сделайте каждый блок на лучшем техпроцессе, а затем объедините их в пакет". Ключевыми словами здесь являются 2,5D, 3D ИС и чиплеты.
Кроме того, чиплеты - это "структура для обхода ограничений технологического процесса, контроля выхода и стоимости, а также смешивания различных процессов в одном корпусе". Проблема в том, что, разложив все по полочкам, гораздо сложнее понять, как соединить все точки.
Но... Чиплеты выглядят хорошо из-за производительности и структуры затрат,
но процесс производства 2,5D и 3D ИС сложен, поэтому производительность может быть низкой, и вам нужно потратить много денег, чтобы компенсировать это, так что в итоге у вас может оказаться живот больше, чем ваш живот.
Поэтому мы пока не видим массового производства.
On-Die Wire to Die-to-Die Link
В монолитных SoC большая часть данных проходит поверх металлического слоя на кристалле. Даже глобальные провода остаются проводами на кремнии, отправляющими и принимающими сигналы с задержкой от сотен пс до нескольких нс и относительно низкой энергией.
Как бы ни был важен дизайн сети на кристалле (NoC), сама физическая маршрутизация - это скорее проблема "внутри кристалла".
Как только вы добираетесь до структуры чиплета, критические данные выходят из кристалла и входят обратно. Другими словами, путь меняется следующим образом:
ядро → On-Die NoC → край кристалла → Micro Bump → Interposer или RDL → Micro Bump на другом кристалле → On-Die NoC → ядро
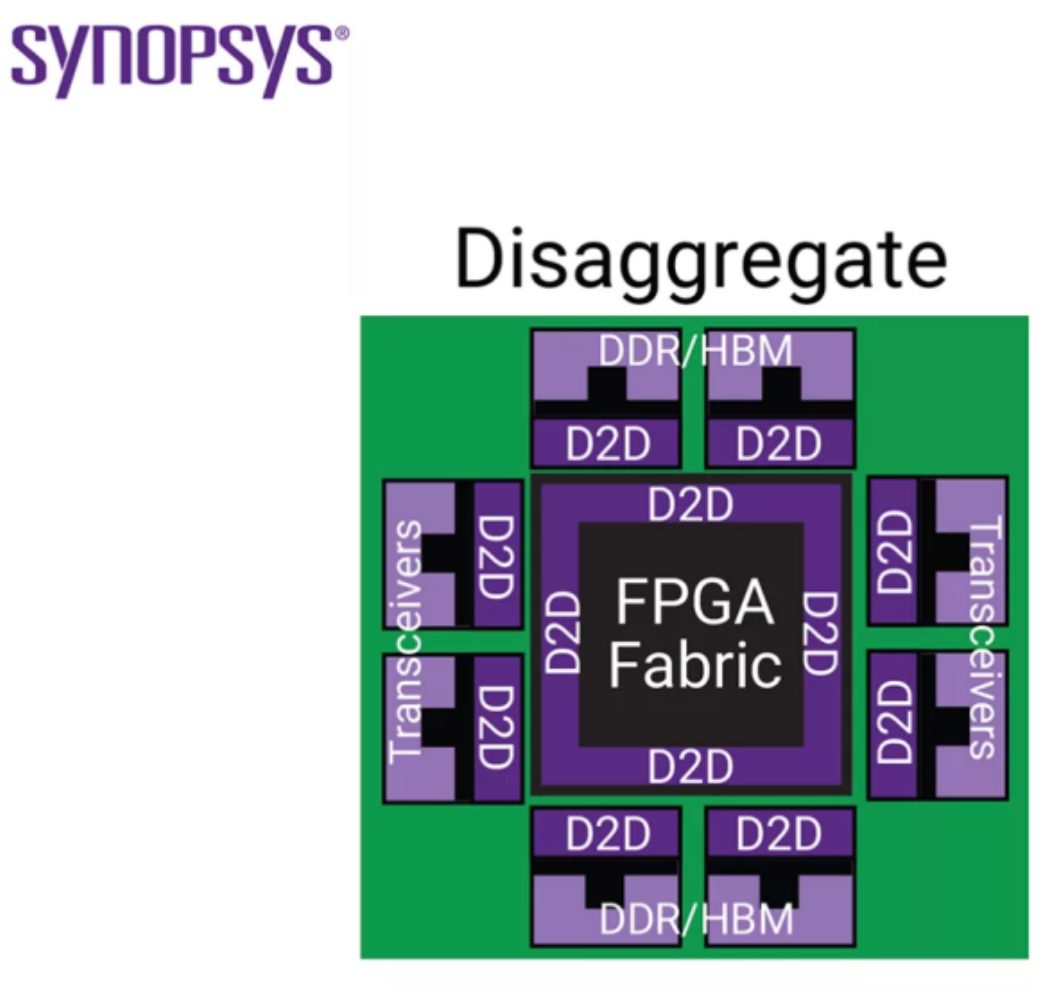
С точки зрения физики, несколько вещей меняется.
Изменяется среда проводки
Сейчас мы имеем дело не просто с металлическим слоем на кремнии, а проходим через различные среды, включая микровыпуклости, TSV, кремниевые интерпозеры, разветвленные RDL и органические подложки.
Изменение длины и среды
Он гораздо длиннее, чем провод на кристалле, и его импеданс более сложен. Возникают проблемы целостности сигнала. Разрушается "стена" между традиционным пакетом SerDes и проводом на кристалле, и в пакет попадают очень продвинутые проблемы уровня проектирования SerDes.
Изменяется цена энергии и площади
Стоимость добавления еще одного провода на кристалле не такая же, как стоимость добавления еще одного соединения между кристаллами. Длина кромки матрицы ограничена, а шаг неровностей ограничен. При увеличении числа связей площадь периметра матрицы, площадь ячейки PHY, маршрутизация и мощность оказывают влияние.
Маршрутизация и мощность
То, что раньше рассматривалось как "мы можем использовать немного больше проводов", теперь рассматривается как "действительно ли эта связь стоит пропускной способности?".
С этого момента межсоединение - это уже не просто физическая проводка, а ключевой ресурс, определяющий архитектуру всей системы Chiplet.
Межсоединение Chiplet с точки зрения PPA
В конце концов, любой дизайн сводится к PPA (мощность, производительность, площадь) и стоимости. Chiplet Interconnect глубоко вовлечена во все четыре составляющие.
Производительность: пропускная способность и задержка
Сейчас между ускорителями ИИ, GPU, высокопроизводительными CPU и памятью с высокой пропускной способностью, например HBM, проходит огромное количество данных. Когда эти данные передаются по каналам связи между кристаллами, а не внутри кристалла, плотность полосы пропускания и задержка при прохождении канала устанавливают верхний предел производительности системы.
Если пропускной способности недостаточно, сколько бы ядер вы ни добавили, вы столкнетесь со "стеной памяти". А если задержка слишком высока, мелкозернистое взаимодействие становится затруднительным, и архитектуру приходится проектировать с крупнозернистой структурой. Например, если кэш-память L3 разделена на микросхемы, а задержка слишком велика, она становится почти как внечиповая память.
Энергопотребление: борьба за пДж/бит
Провода на кристалле могут снизить мощность до десятков фДж/бит, но SerDes на основе пакетов часто стоят несколько пДж/бит. PHY с малым радиусом действия и сверхнизким энергопотреблением для микросхем также стремятся к уровню ниже пДж/бит, но они все равно дороже, чем на кристалле."
В конце концов, как системный архитектор, вы должны спросить себя: "Действительно ли я хочу отправить эти данные через кристалл, или я хочу еще раз вычислить их в кристалле и сжать?"
И ценник мощности межсоединения не одинаков. При изменении стоимости мощности межсоединения меняется и соотношение вычислений и связи.
Area: Die Edge and PHY Area
Chiplet Interconnect "Edge-Centric". Бамп и PHY располагаются по периметру матрицы. Увеличение размера матрицы увеличивает не только площадь ядра, но и длину края, а то, насколько эффективно край распределен для межсоединения, напрямую влияет на PPA.
В частности, при использовании стандартизированного интерфейса "матрица-матрица", такого как UCIe, нельзя игнорировать площадь, занимаемую PHY, контроллером и стеком протоколов. Сокращение занимаемой площади и потребляемой мощности является конкурентным преимуществом микросхем.
Cost: Сочетание процессов и сложность упаковки
При использовании чиплетной структуры можно снизить стоимость единицы матрицы за счет разделения логики на передовые процессы и ввода/вывода на зрелые процессы. Проблема заключается в стоимости упаковки. Кремниевые интерпозеры, RDL высокой плотности и бампы с мелким шагом очень дороги. Чрезмерные требования к межсоединениям усложняют структуру пакета и повышают общую стоимость"
Таким образом, межсоединения становятся метрикой, определяющей, "имеет ли эта архитектура чиплета экономический смысл?
UCIe и стандартизация интерфейсов Die-to-Die
Одним из самых обсуждаемых ключевых слов в настоящее время является UCIe (Universal Chiplet Interconnect Express). Хотя в названии чувствуется оттенок PCIe, на самом деле его цель - обеспечить совместимость с существующими протоколами, такими как PCIe/CXL, а также PHY, специализированными для работы с матрицами.
Причина создания UCIe очевидна. Чиплеты от разных компаний можно объединять
Экосистема чиплетов никогда не будет развиваться, если каждая компания будет придерживаться своего собственного интерфейса между плашками. Только когда появится "стандартный интерфейс, который может комбинировать каждый", можно будет действительно иметь "сборные" конструкции на уровне SoC.
Преимущества стандартизации очевидны: например, одна компания может производить чиплеты CPU, другая - NPU, третья - SerDes/IO, а системная компания может объединить их в пакет. В реальности, конечно, все не так просто из-за проблем с интеллектуальной собственностью, валидацией и ответственностью. Но то, что это "возможный сценарий", уже большое изменение.
EDA и Design Flow очищены
Не нужно каждый раз моделировать новые проприетарные PHY и протоколы, можно использовать модели каналов и связей на основе UCIe в качестве общей основы. Есть общий знаменатель для STA, SI, PD и Package Co-Design Flow.
С другой стороны, наличие стандарта также означает, что "сам интерконнект становится точкой конкуренции". Компания с PHY IP, структурой пакета и технологией совместной оптимизации, которая может обеспечить лучшие показатели мощности/пропускной способности/замедления/площади, выиграет рынок.
Размывание дизайна упаковки и чипа
Еще одна причина, по которой Chiplet Interconnect так важен, заключается в том, что он разрушает "границы дизайна".
В прошлом разделение было примерно следующим:
In-die: логический дизайн, физический дизайн, STA, On-Die SI
Package: дизайн PCB/Package Team отдельно и на гораздо более низких скоростях
В чиплетной структуре эти два компонента полностью неразделимы. Каналы в канале Die-to-Die Link одновременно рассматривают структуры упаковки и края матрицы. Размещение матрицы, сопоставление бампов, маршрутизация межслойных соединений, укладка упаковки и размещение PHY внутри матрицы - все эти вопросы должны решаться одновременно."
В конце концов, все эти вопросы решаются в команде.
На каком расстоянии друг от друга должны располагаться микросхемы A и B
Какая длина канала может быть допустима на интерпозере
В каком порядке должны располагаться бампы на краю матрицы
Где должны быть ограничены NoC на матрице и связь между матрицами
Здесь за один стол садятся инженер по упаковке, инженер PD, инженер SI, системный архитектор и поставщик EDA-инструментов.
По мере распространения микросхем перспективы, требуемые от проектировщиков, будут меняться:
Не просто "понимание нескольких нанослоев процесса"
Способность понимать физический, логический и протокольный уровни межсоединения вместе
Вид на системном уровне NoC на кристалле и ткани вне кристалла как единого целого
Способность анализировать сквозные компромиссы, включая мощность/площадь/стоимость
Эти три вещи будут становиться все более важными.
Возможно, вы подумаете: "Еще многое предстоит сделать с транзисторами, логикой, БП и СТА, а потом еще межсоединения и упаковка". Но лучше приступать к проектированию, зная, по крайней мере, "где находятся реальные узкие места, которые определяют производительность и стоимость чипа". В наши дни таким узким местом очень часто оказывается межсоединение."
С моей точки зрения, межсоединение в эпоху чипсетов - это не тема, которую следует избегать, а скорее отличная возможность расширить свою карьеру. Как только вы поймете, что такое межматричные соединения и упаковка, вы станете специалистом по "целому чипу", вместо того чтобы просто рассматривать синхронизацию и СИ в матрице. Сфера ваших возможностей становится гораздо шире."