在现代半导体设计领域,特别是ASIC(专用集成电路)设计流程中,逻辑综合是将抽象的人类逻辑(RTL或HDL)具体化为物理硅片现实(门级网表)的关键转换过程。
简而言之,
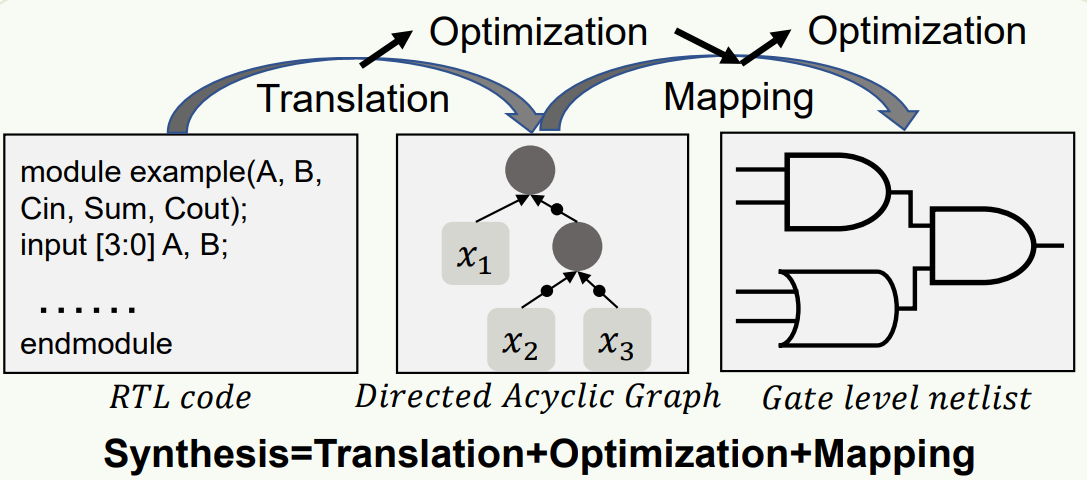
逻辑综合就是将RTL作为输入,生成门级网表作为输出。
- RTL是一种不考虑物理实现、仅包含逻辑结构的设计图。
- 网表基于代工厂提供的单元库, 包含物理信息与逻辑信息的电路设计图。(不含坐标值等参数。)
- 后续在P&R、ECO等阶段,通过向逻辑综合生成的电路输入坐标进行布局、布线,并略微调整单元类型进行修改。
- 对于综合阶段产生的PPA指标,即使希望获得更高PPA,在P&&R阶段难以进一步提升。
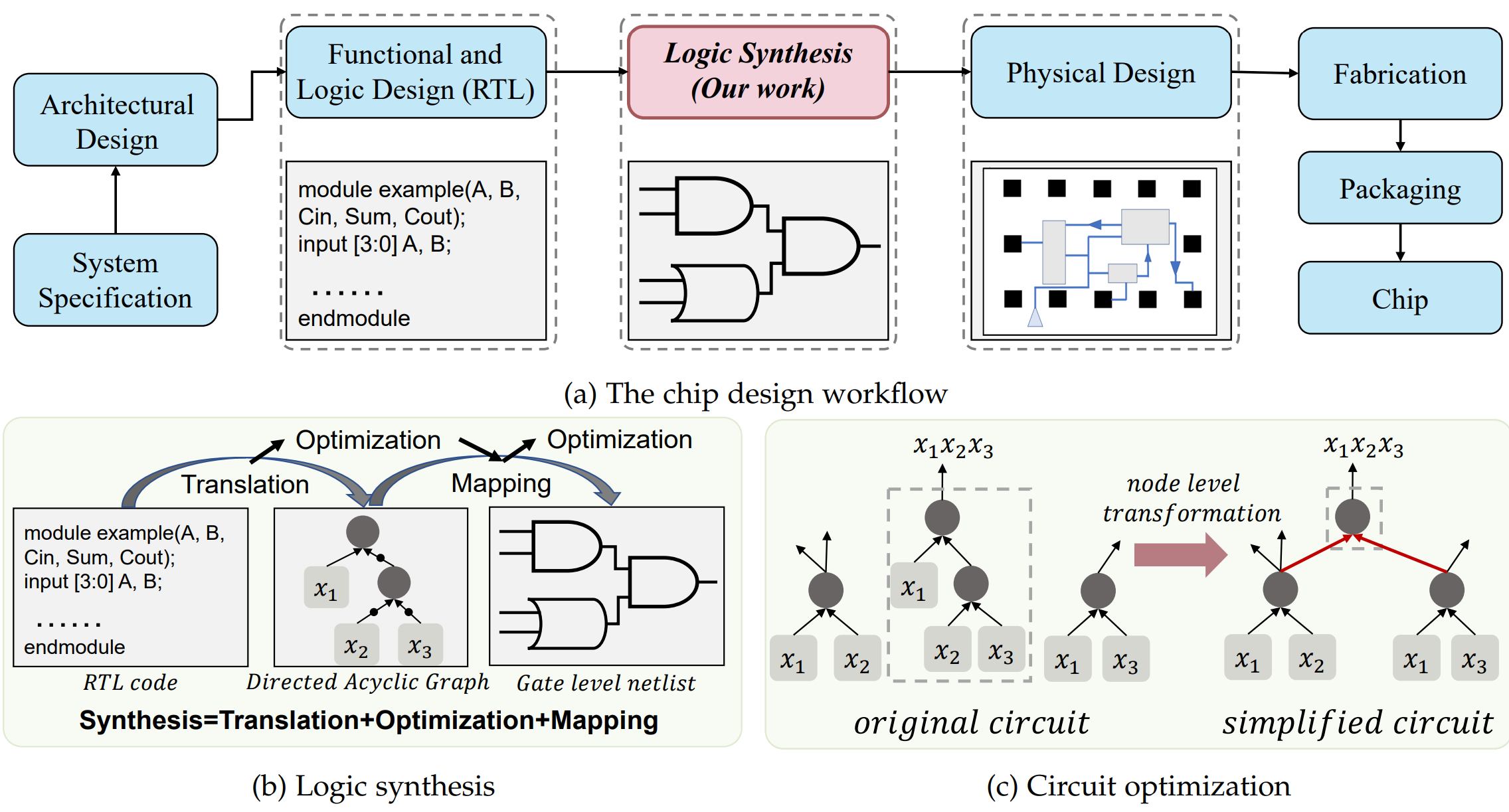
在从RTL到GDSII的完整流程中,综合环节占据绝对主导地位。
该阶段确定的PPA(功耗、性能、面积)初始指标将直接影响后续布局布线阶段的收敛性。若综合阶段设置了错误约束或生成不符合物理现实的结构,将导致后端设计过程中产生大量加班需求。
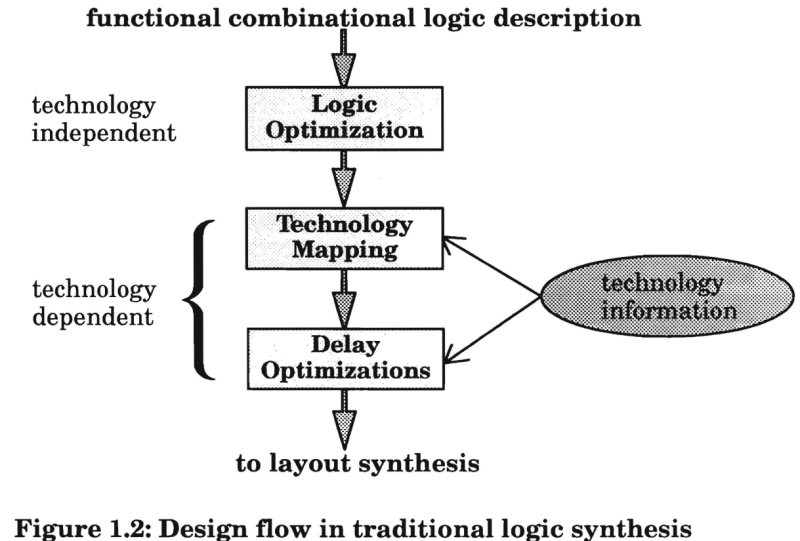
1. 转换的数学:抽象层级的下降与优化的序幕
逻辑综合本质上是在保持功能等价性的同时,解决如何最小化实现成本的多维优化问题。RTL代码是人类易于理解的高层抽象。
逻辑综合由三个阶段构成:
- 翻译(或展开)
- 优化
- 映射
1.1 解析与精化 (Parsing & Elaboration): GTECH的世界
综合的第一步是将HDL(Verilog/VHDL)文本转换为工具可识别的内部数据库结构。此过程称为精化(Elaboration), 此时生成的初始网表采用与特定工艺技术无关的通用技术库(GTECH)。
- 解析与推导阶段:
- 工具会检查代码语法错误,解析
always块和assign语句。此阶段的核心是硬件推导(Hardware Inference)。 - 例如,
if-else语句会被解析为多路复用器(MUX),posedge clk语句则被解析为触发器(Flip-Flop)。 - ference阶段。
- 例如,
if-else语句将转换为多路复用器(MUX),posedge clk语句则转换为触发器(Flip-flop)。
- 工具会检查代码语法错误,解析
- 架构选择阶段:
- RTL中的
+、*等算术运算符属于抽象概念。在Elaboration阶段,工具将确定实现这些运算符的初始架构。
- RTL中的
- 例如在实现加法器时,需权衡采用面积小但速度慢的Ripple Carry方式,还是牺牲面积以实现高速运行的Carry Look-ahead方式。
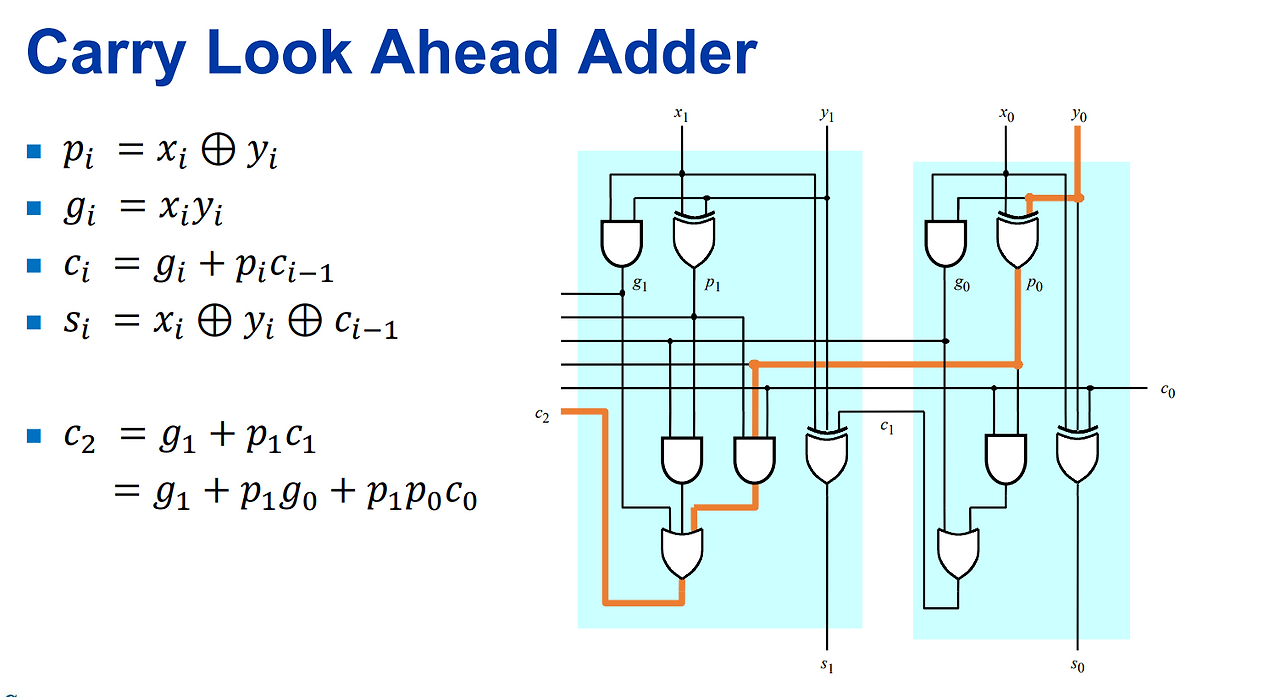
1.2 技术无关优化
GTECH状态的网表通过应用布尔代数原理进行逻辑简化。该步骤与标准单元无关,故称为"技术无关优化"。
1.2.1 布尔优化与冗余消除
最基础的优化是消除冗余逻辑。 例如A & 1可简化为A,A | 0可简化为A。更复杂的操作是识别电路内部存在但不影响输出的冗余连接,将其移除或替换为常量。
这实质上是K-Map原理的算法化扩展, 在大规模电路中会采用Espresso算法等启发式方法。
1.2.2 公共子表达式消除
工具通过分析数据流图来查找重复运算。
当存在F = (A * B) + C与G = (A * B) + D时,
通过结构调整使(A * B)项仅计算一次并共享结果,避免重复计算。此举可减少门数并优化面积。
1.2.3 基于AIG(与反相图)的优化
现代综合工具(特别是ABC、Genus)积极采用AIG(与反相图)结构来表示逻辑。
AIG是一种仅用2输入与门和反相器表示的无向有向图。相较于传统BDD(二进制决策图)存在变量顺序导致内存消耗激增的缺陷,AIG在结构上更具资源效率性。
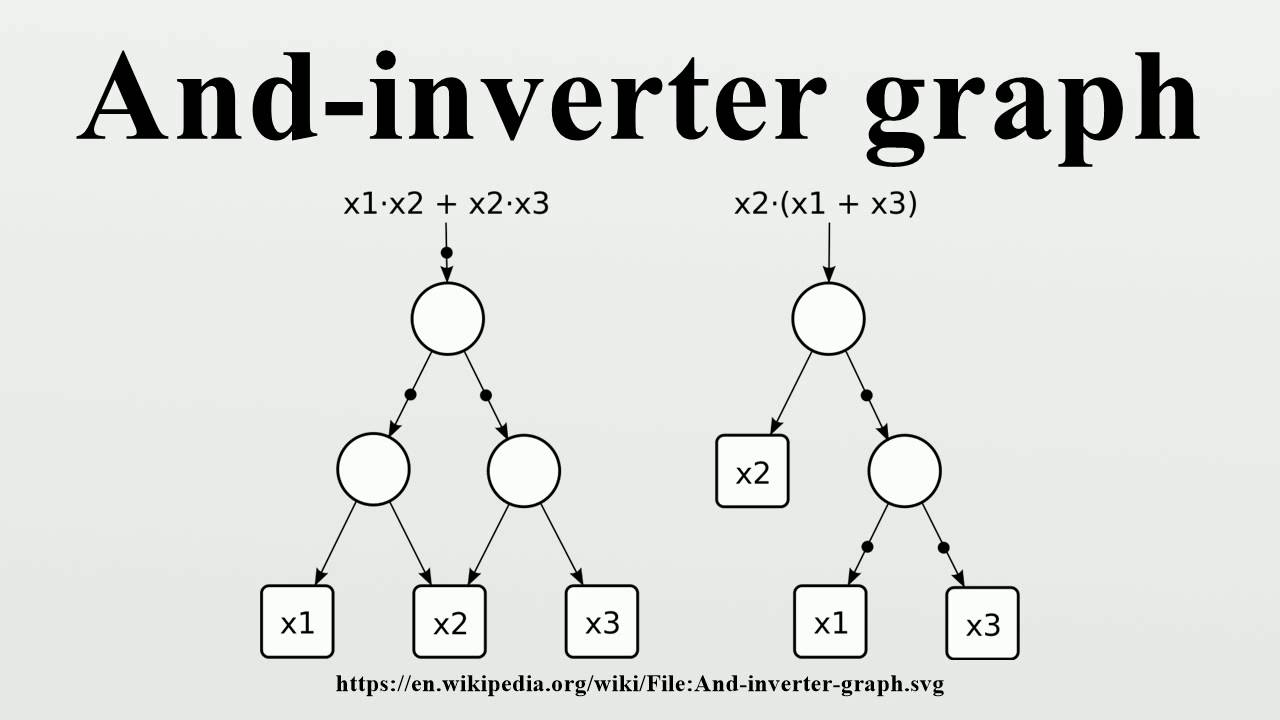
- 结构哈希:在AIG生成过程中,通过避免重复创建具有相同输入和功能的节点,实现内存节约并促进自然逻辑共享。
- AIG重构:通过提取AIG的子图,将其替换为使用更少节点但功能等价的替代结构。这种方法通过反复局部优化,能有效缩减整体图的规模。
2.设计约束(Synopsys Design Constraints, SDC)原理与物理解析
"垃圾输入,垃圾输出。"这是EDA领域最重要的箴言。即便拥有最高效优化引擎的工具,若设计者提供的目标约束值不准确,仍会输出错误结果。
SDC(Synopsys Design Constraints)并非简单的配置文件,而是向工具阐释设计意图与物理环境的标准语言。
2.1 时钟的定义与建模:时间的基准点
所有同步数字电路的基准都是时钟。 create_clock指令定义时钟频率、占空比和相位。但在综合阶段,时钟尚未形成实际物理时钟树,因此被视为"理想"状态。
2.1.1 时钟不确定性的必要性
理想时钟是无偏移无抖动的完美方波,但实际硅片环境并非如此。因此需通过set_clock_uncertainty指令预先为布局后可能产生的波动预留裕度(Margin)进行预留。
- 建立时间不确定性: 设定为时钟抖动(Jitter)与预期时钟偏移(Skew)之和。此举通过缩减时序分析中的有效时钟周期(悲观估计),促使工具进行更严格的优化。
- 保持时间不确定性: 保持时间通常采用零周期检查,故无需考虑相位差。 主要反映预期时钟偏移,作为防止数据过早到达导致违规的裕量。
2.1.2 虚拟时钟与I/O约束
对芯片主端口进行时序约束时,需使用虚拟时钟来建模外部设备的时钟。strong>。该虚拟时钟虽未与芯片内部任何引脚物理连接,但作为set_input_delay或set_output_delay的基准参考点发挥作用。
2.2 I/O时序预算
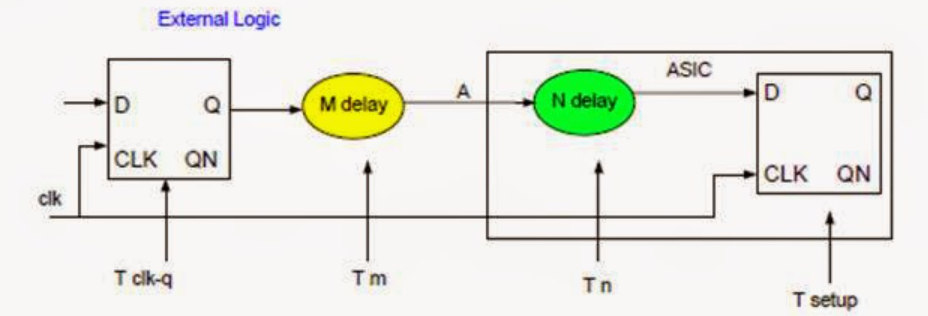
set_input_delay与set_output_delay是告知工具"芯片外部已使用(或将使用)的时间"的指令。工具通过从总时钟周期中扣除该值,计算出芯片内部逻辑可用的时间预算。
- 输入延迟设置:指数据从当前设计外部的时序起点出发,到达当前设计输入引脚所需的时间。
- 输出延迟设置:指数据从当前设计输出引脚发出,到达当前设计时序终点所需的时间。
- 解释: 工具会通过优化布局(如增加高电驱动强度单元)或降低逻辑深度,确保数据到达输出引脚的时间小于
时钟周期 - 输出延迟。
- 解释: 工具会通过优化布局(如增加高电驱动强度单元)或降低逻辑深度,确保数据到达输出引脚的时间小于
2.3 时序例外情况
并非所有路径都必须在1周期或0周期内完成。若未明确标注例外路径,工具可能因优化非必要路径而浪费面积和功耗,或遗漏关键路径的优化。
关键在于,这些方法本质上是"为时序检查预留更多余量",因此必须极其谨慎使用。若不添加这些路径也能实现时序收敛,则不添加更为稳妥。
2.3.1 虚假路径:放弃优化的声明
set_false_path用于标记逻辑上不可达或不需考虑时序的执行路径。
2.3.2 多周期路径:时间扩展
set_multicycle_path是为乘法器或复杂算术运算等难以在1个周期内完成的路径分配N个周期时间的指令。
3. 优化:成本函数与PPA权衡
合成工具并非魔法盒子。它本质上是巨型数学引擎,在众多约束条件中寻找使成本函数最小化的解。该成本函数由性能(Performance)、面积(Area) 功耗这三项相互冲突的要素的加权和来表达。
例如:
- 提高频率可使芯片运行更快。但开关活动增加导致功耗上升。
- 逻辑并行化可提升芯片带宽。 但芯片面积随之增大。
过去,关键指标在于晶圆内能容纳多少芯片(能否实现低成本量产?)。
如今,核心在于能否进一步提升带宽,以及能否提高良率。
3.1 优化绝对优先级 (优化优先级)
当工具无法同时满足所有约束条件时,将遵循以下严格优先级进行操作。理解此顺序对于分析综合结果和调整约束条件至关重要。
- 设计规则约束 (DRC): 逻辑综合所用的库基于以下三项标准进行特性化。若超出这些数值范围,则因涉及晶圆厂未特性化的部分,将导致结果不准确。
- 最小/最大电容转换值
- 最小/最大电容值
- 最大扇出数
- 时序约束(建立时间):性能核心
- WNS(最差负余量):最严重违规路径(关键路径)的延迟裕量值。
- TNS (总负裕量):所有违规路径延迟裕量的总和。
- 保持时间约束 (最小延迟):
- 逻辑综合阶段时钟树处于理想状态,因此完全捕捉保持时间违规既不可能也不高效。
- 过去采用线负载模型(Wire Load Model),根据门数量赋予线延迟;现代方法则是将时钟周期乘以60%,其中40%作为建立时间裕量,而布局布线阶段则专注于保持时间收敛。
- 功耗与面积优化(面积回收):
- 在满足上述条件的前提下,通过缩减具有正时裕度的路径门电路尺寸(Down-sizing),或替换为低功耗高阈值单元(LVT → HVT),从而降低漏电功耗(Leakage Power)与面积。此过程称为面积回收。
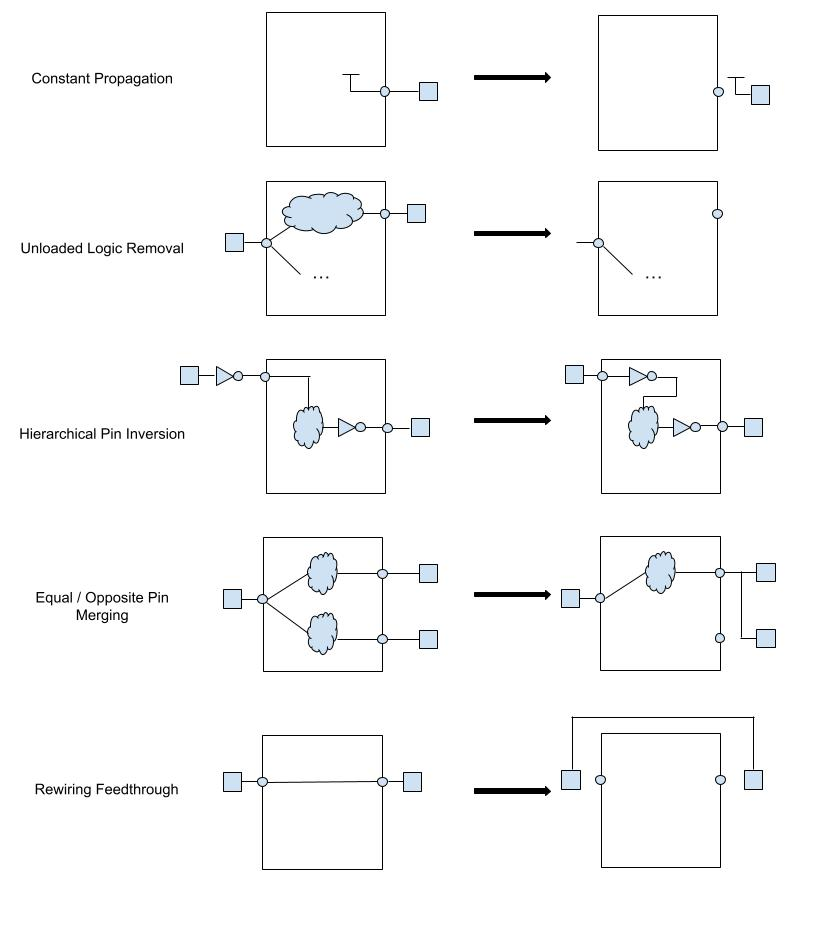
3.2 边界优化与层次结构
综合工具默认以模块为单位进行优化,但使用compile_ultra等高级指令时,可执行跨模块边界的优化操作。
- 作为逻辑综合输入的Verilog文件中包含多种*.v文件。
- 合成工具默认会遍历每个*.v文件,分别执行优化操作。
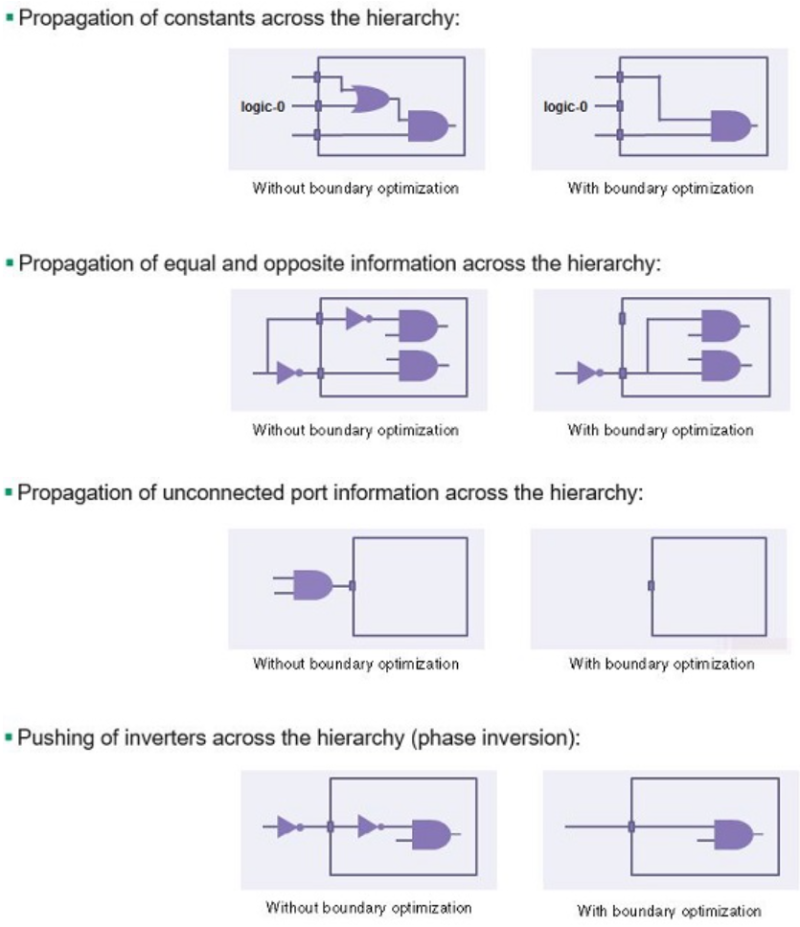
- 高级合成工具会一次性查看所有*.v文件进行整体优化,这种优化称为边界优化(Boundary Optimization)。
- 常量传播(Constant Propagation):若上级模块将下级模块的特定输入引脚固定为
0或1,工具将进入下级模块内部,移除所有与该信号相关的逻辑。 这是减少冗余门电路的有效方法。 - 分层引脚反相:为优化时序性能,将反相器在模块边界内外进行迁移。某些情况下通过反转模块输入引脚的相位(Invert),并依据德摩根定律修改内部逻辑,从而实现更高效的映射。
- 直通优化:若存在仅通过模块的信号,则检测该信号并生成绕行路径或移除端口,以降低布线拥塞度。
- 常量传播(Constant Propagation):若上级模块将下级模块的特定输入引脚固定为
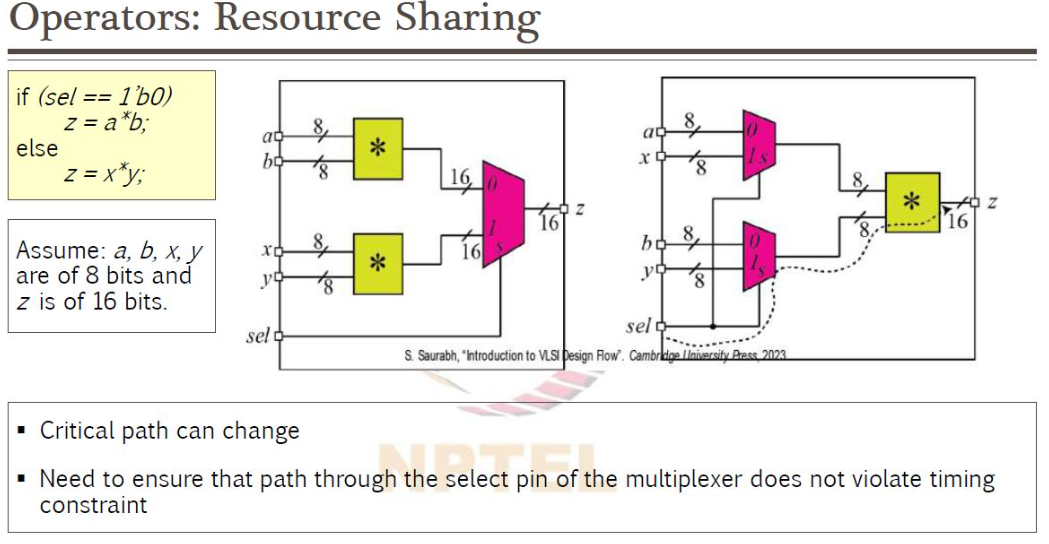
3.3 高级优化技术:重定时与资源共享
- 资源共享:若存在运行时间不同(例如由MUX选择的条件)的高成本运算单元(乘法器、加法器)时,与其制作两个,不如仅制作一个,并在前端配置多路复用器实现共享。 这能显著减少面积,但会增加数据路径前端的逻辑,导致时序恶化,存在权衡取舍。
- 重定时: 通过将流水线寄存器的位置移至组合逻辑之间,实现路径间延迟平衡的技术。例如,当长组合逻辑后接寄存器,再接短组合逻辑时,可将寄存器前移以提升时钟频率。该功能通过
optimize_registers或compile_ultra -retime选项激活。
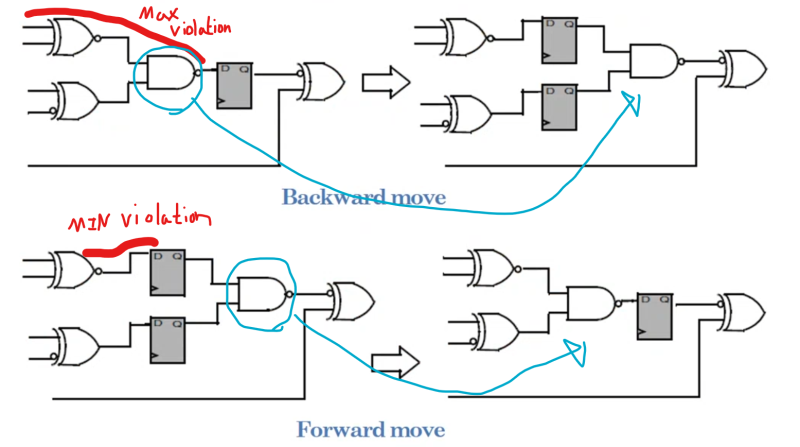
4.技术映射的微观原理
RTL设计者编写的assign y = a & b;代码转化为实际硅片上NAND门与INV门组合的过程,并非简单的1:1映射。这是解决图覆盖这一高度复杂算法问题的过程。
4.1 布尔匹配
工具将优化的布尔网络转换为称为主题图的图结构。同时将.lib文件中的标准单元分别映射为体现其功能的模式图。。技术映射即通过Pattern Graphs对Subject Graph进行无缝覆盖的过程。
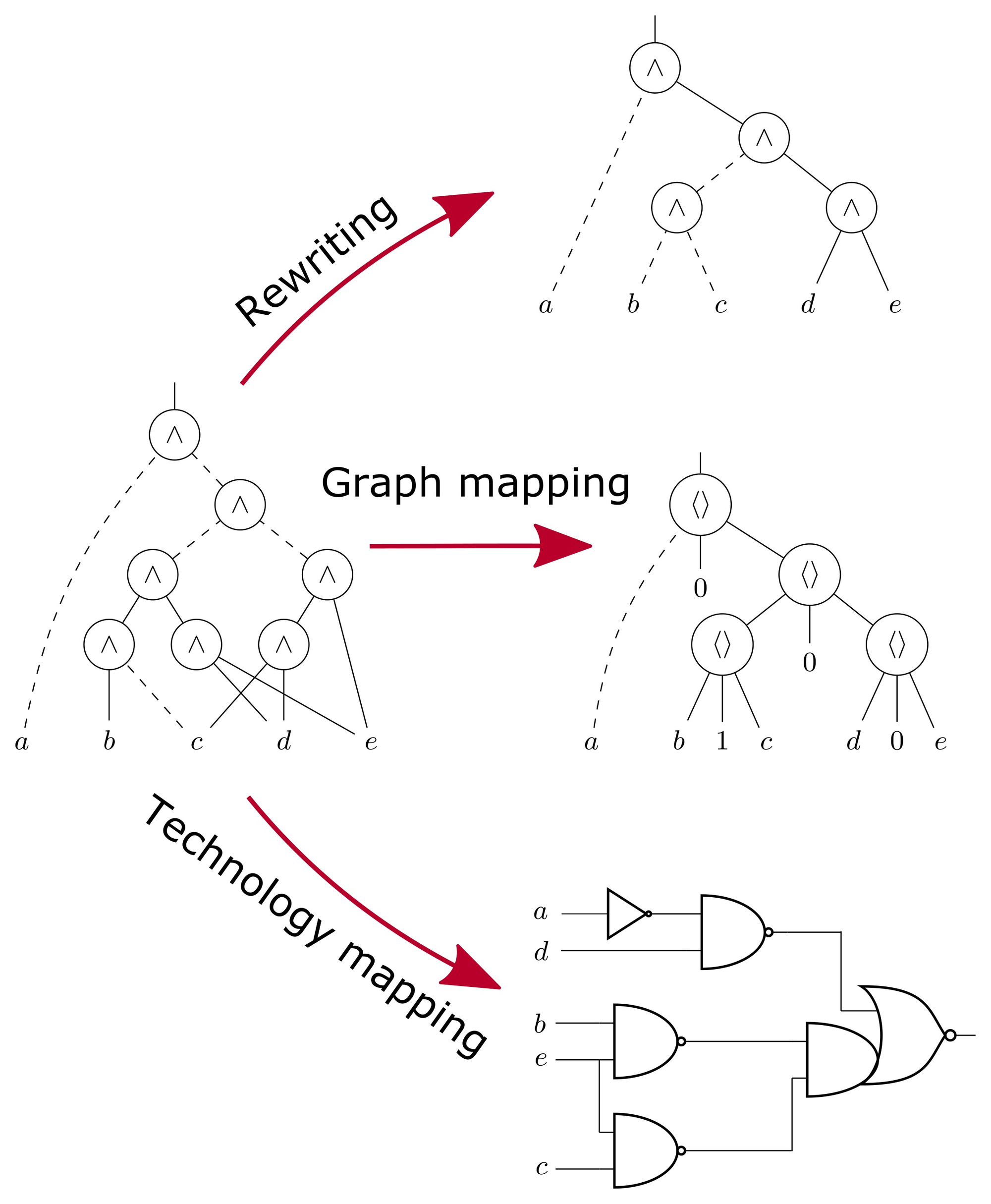
- 裁剪枚举法:在图的特定节点处截断输入(Cut),寻找所有可构成的子图。例如,探索是否能将某个具有4个输入的逻辑单元映射到单个单元格中。 该原理与FPGA综合中的LUT映射类似。
- 基于成本的选择:实现单个逻辑的方法不胜枚举。实现
(A+B)时,既可使用单个OR门,也可采用NOR门与INV门组合。 工具会计算每个模式图(标准单元)固有的成本(PPA),并通过动态规划找到覆盖整个图所需总成本最小的组合方案。
4.2 延迟模型的演进
在映射阶段精确计算成本时,精密的延迟预测至关重要。
- NLDM(非线性延迟模型):采用传统方法,通过以输入转换时间和输出负载电容为坐标轴的二维查找表计算延迟。 该方法在90nm及以上工艺中足够精确,但在更先进工艺中准确度不足。
- 复合电流源模型(CCS)/电容电流源模型(ECSM):针对最新微制程,通过电流源模型模拟晶体管行为,精确反映非线性特性、 Miller效应及低电压工作特性。当前28nm及以下工艺的合成设计均基于CCS/ECSM模型进行。
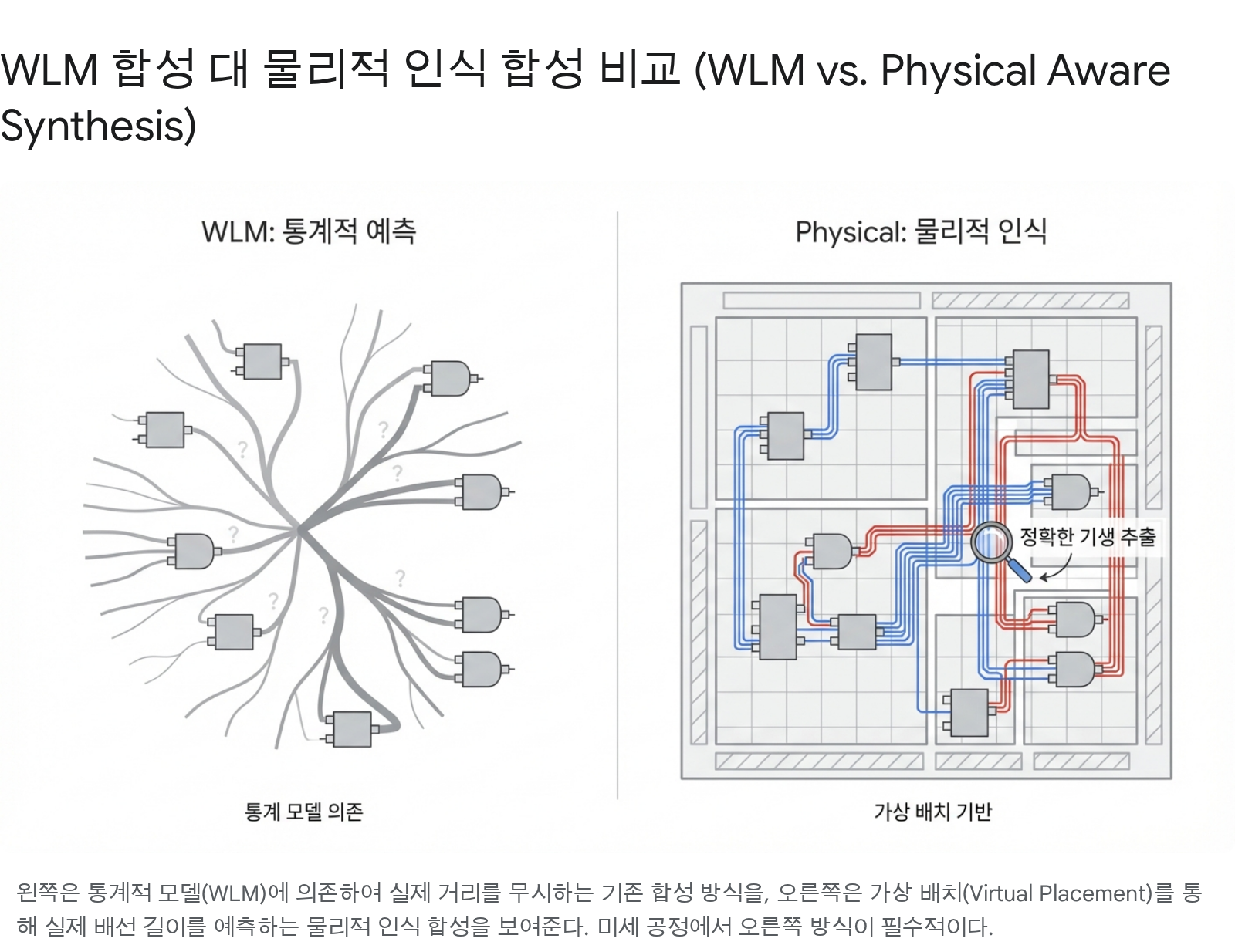
5.1 WLM的局限性与物理综合的兴起
然而,随着工艺节点向65nm、28nm及FinFET过渡,形势发生了逆转。 随着布线宽度缩小,电阻比急剧上升,布线间的耦合电容占比接近总延迟的50%。基于WLM的综合方案在实际P&R后出现严重的时序相关性问题,导致设计迭代陷入无休止循环。
为此,物理感知综合应运而生。新思科技的Design Compiler Graphical/NXT (compile_ultra -spg)或Cadence的Genus iSpatial技术即属此类。这些技术在综合引擎内部调用自家P&R引擎的粗略布局与全局布线API,根据当前DEF标准预估布线方案,并将这些预估值应用于逻辑综合阶段。
5.2 物理综合的核心功能
- 虚拟布局与 布线:采用与实际P&R工具(IC Compiler2、FusionCompiler、Innovus)相同的布局引擎,确定单元的大致位置。基于单元间的实际距离(曼哈顿距离)提取RC寄生参数。
- 拥塞分析与缓解:在综合阶段预先检测因逻辑过度集中导致布线失败的拥塞现象。工具通过分散拥塞区域的逻辑(Spread)或修改结构,提前预防DRC Violation。
6. 结果分析与时序调整策略
合成完成后,工程师需通过分析海量报告与日志来验证结果质量。此阶段是向后续流程移交数据前的最终质量关卡。
6.1 时序报告解读与路径组
时序报告呈现从启动触发器到捕获触发器的完整路径。为提升分析效率,工具会按路径特性将其划分为路径组。
- Reg2Reg: 触发器间路径。芯片性能的核心指标。若合成阶段存在严重违规,P&R阶段后难以显著改善。
- In2Reg / Reg2Out: I/O接口路径。受预设的
set_input_delay/output_delay参数影响。若其他时段存在余量,此处问题通常不大。 - In2Out:若未设置约束条件,此处单元可能被全部删除或需添加大量缓冲区,需特别注意。
6.2 建立/保持时间违规修正指南
合成阶段的时序修正策略与P&R阶段不同。 因为此时布线尚未确定。
建立时间违规 (最大路径) 解决策略
建立时间违规源于数据到达过晚。
- RTL修改: 效果最显著。可通过添加流水线寄存器,或将复杂的
if-else链转换为并行case语句实现。 - 利用LVT单元: 在
compile_ultra选项中提高低阈值电压(LVT) (LVT)单元。需注意此举将伴随功耗增加。 - 路径组权重:通过
group_path -weight指令为特定路径组赋予更高优先级,强制工具即使牺牲面积也要优化该路径。 - 也可通过逻辑克隆、重定时、边界优化等手段缩减。这些操作对P&R工具而言难以自动完成,即便实现也极其复杂。
- 建议将综合(Synthesis)视为逻辑设计的最终调整环节。若在后续ECO阶段尝试通过ICG克隆等方法修正时序违规问题...
保持时间违规(最小路径)解决策略
保持违规源于数据到达过快。
- 原则:综合阶段中保持时序的可靠性通常较低。若在无实际布线延迟的情况下添加缓冲器,P&R阶段被移除或产生误差的概率较高。
- 但仍需在综合阶段控制较大的Hold violation值(具体阈值因设计而异),以减轻P&R工具的处理负担。
7. 最新工具趋势:Design Compiler vs Genus
当前市场由新思科技的Design Compiler(DC)与Cadence的Genus双雄并立,二者各具优势。
- 新思科技Design Compiler: 长期作为综合设计的行业标准(De facto standard)占据主导地位。其优势在于强大的生态系统和稳定性,并通过Fusion Compiler平台强化了与布局布线的集成。
- Cadence Genus: 虽是综合领域的新晋选手,但其布局布线工具Innovus在物理设计工程师中广受欢迎,正迅速提升市场影响力。
观察我身边的PD工程师们, 多数倾向于采用DesignCompiler与Innovus的组合方案。关键在于,长期使用单一工具会形成依赖性,导致切换其他工具时面临困难。毕竟工具终究只是工具。
结论:必须成为掌控工具的工程师
逻辑综合并非将RTL转换为门级电路的翻译器。
- 操作员: 这类人员会反复尝试各种方案直至设计链接成功,链接完成后进行编译,生成网表后转交给布局布线工程师。
- 专家型:他们负责从RTL代码审查到与布局布线工程师的会议,乃至向EDA厂商提出新功能开发需求等所有接口工作,并研究如何实现最佳功耗、性能与面积(PPA)。
逻辑综合是在物理与逻辑约束条件下,求解数千万变量方程的高级工程过程。
工具并非完美。 唯有通过SDC向工具传递精确的"意图",通过日志和报告解读工具的"思维",理解物理现象并懂得"优化"RTL结构的工程师,才能获得最佳PPA结果。
初级工程师不应止步于按工具按钮的操作员,而应不断追问:
"该约束条件如何影响工具的成本函数?"
"这种RTL结构会被映射算法识别成什么模式?"
"这次SNUG会议有哪些合成相关的论文? 其他公司又在做什么?"
这些问题必须不断追问。当答案逐渐积累时,才能真正蜕变为名副其实的'架构师'。