한국의 메모리 반도체 비관론은 아래 영상으로 시작된다.
내용을 요약하면, "반도체 수요 증가는 감산으로 의한 착시", "매출 증가는 단가 상승 + 환율", "사이클 종료, 중국의 추격, CAPEX 회수 압박"
위 영상을 보고 느낀점은, 통계적으로는 진짜 말이 되네? 근데 왜 미래 수요에 대한 weight는 안 주신 걸까?
비관론 Weight 항목 (통계)
- DRAM cycle 이력
- 메모리 capex 의 과잉
- 중국 본토 capacity 증설
- Hyperscaler 자체 ASIC 의 위협
낙관론 Weight 항목 (미래)

- AI inference scaling (Long context · agentic workflow)
- Hyperscaler capex 구조
- HBM base die 의 logic 통합
위와 같은 낙관론 변수를 통해 비관론의 보완 지점을 짚는다.
1. 비관론의 근거
구글에 메모리 비관론, 메모리 버블을 검색하면 아래와 같은 동영상들이 위에 노출된다.
- "2026년 시장의 진짜 리스크 — 엔비디아가 꺾이면 코스피 3천이다. 반도체 호황의 착각. 수요 없는 성장" (경읽남과 토론합시다, 2025년 12월) [link]
- "출하량은 주는데 매출은 폭발? — 반도체 실적 '착시' 주의보" (삼프로TV, 2026년 1월) [link]
- "AI 버블 논란부터 중국의 무서운 추격까지, 2026년 한국 반도체가 마주할 냉혹한 현실 시나리오" (이주완 인더스트리얼 애널리스트 풀버전) [link]
비관론 thesis 의 핵심 논거는 다음 네 가지로 압축된다.
- 출하량 vs 매출의 괴리.
- 매출 폭증은 ASP (단가) 와 환율 효과로 부풀려졌고, bit shipment 그래프 자체는 비관 thesis 가 보기에 충분히 강하지 않다.
- 단가 인상의 결과를 demand 의 결과로 오독한다는 주장이다.
- 메모리 capex 의 과잉.
- SK하이닉스의 2026 capex 는 약 USD 20.5억(전년 대비 +17%, M15x HBM4 증설 중심), 삼성전자 메모리는 2026년 약 USD 20억(+11%) 가이던스로 추정되며, 양사 합산 KRW 50조 이상의 메모리 capex 가 진행 중이다.
- 비관론은 이 capex 의 사이클적 여진을 우려.
- 중국 본토 capacity 의 구조적 추격.
- CXMT 의 2024-2025 DRAM 월 wafer capacity 가 100k → 290k 로 약 2.9배 확대되었고, UBS 추정으로는 2026 년 중 추가 120-140k wpm 증설이 예상된다.
- CXMT 는 2025 년 매출 약 USD 80억(전년 대비 +130%) 을 기록했다 [KR-Asia] [Tom's Hardware].
- CXMT 는 DDR5-8000, LPDDR5X-10667 까지 시연했고, HBM3 양산을 2026 년 말 목표로 한다는 보도가 있다.
- AI 수요의 구조적 한계 우려.
- 비관론은 hyperscaler capex 의 정점 가능성, 자체 ASIC (TPU·Trainium·MTIA·Maia) 으로의 메모리 수요 분산, 그리고 추론 비용의 sharp 한 효율화 (KV cache offload, quantization) 가 HBM 단가 premium 을 침식할 수 있다고 본다.
- 하나증권은 "AI 서버 수요가 견조하더라도 HBM 가격은 2026년 이후 두 자릿수 조정이 나타날 수 있다"고 분석했다 [한경 매거진].
이 네 가지 fact 는 모두 검증 가능한 실측이거나, 적어도 공개 자료로 추적 가능한 추세다. 본 글은 (a)-(d) 의 통계적 정합성을 부정하지 않는다. 부정 대상은 이 네 가지로부터 도출되는 "한국 메모리는 곧 정점이다" 라는 결론의 부등식이다.
2.반도체에서 미래학적 빈자리 5 개
비관론의 데이터가 모두 정확하다고 가정하자. 그래도 본 글이 보기에는 다섯 개의 미래 변수가 thesis 안에서 충분히 가중되지 않았다.
2-1. AI inference scaling 의 KV cache 폭증
학습(training) 비중이 줄고 추론(inference) 비중이 빠르게 증가하는 국면에서, KV cache 는 모델 가중치보다도 빠르게 메모리를 점유한다.
- Multi-head attention 모델 기준 KV cache 는 token 당 약 1MB 수준에서 시작하고, 시퀀스 길이에 선형 비례한다 [KV cache deeper look].
- 즉, 추론 트래픽이 늘어날수록 — 학습보다 추론이 demand 의 다수가 될수록 — HBM bandwidth 의 한계 효용은 더 커진다.
비관론이 보는 "수요 둔화" 는 학습용 GPU clusters 의 신규 발주 둔화를 가리키는 경우가 많은데, inference 측은 정반대 곡선을 그린다.
2-2. Long context (1M+ token) 의 HBM·CXL 요구
1M token 컨텍스트 1 user 에 약 15GB KV cache 가 필요하다는 추정이 있다 [Introl].
- 동시 사용자 수와 곱하면 데이터센터당 HBM 요구량은 우상향한다.
- CXL DRAM tier 와 host memory offload 가 일부 흡수하지만, hot KV 는 여전히 HBM 에 머물러야 latency 가 유지된다.
- Google Cloud 가 KV cache hot/cold tier 를 분리하기 시작한 것 자체가 HBM 부담의 방증이다 [Softmax].
2-3. Agentic / multi-step reasoning 의 추가 메모리 multiplier
Agent 는 단일 prompt 가 아니라 도구 호출과 다단 reasoning 을 거치며 inference context 의 TTL (time-to-live) 을 분 단위, 시간 단위로 확장한다 [The Register].
- 동시 에이전트 수가 단일 query 사용자 수보다 한 자릿수 이상 늘어나는 시점에서, KV cache 의 라이프사이클 자체가 길어진다.
- NVIDIA 가 Rubin 세대에 Inference Context Memory Storage (ICMS) 라는 별도 storage tier 를 제안한 것 자체가 이 문제의 hardware 측 응답이다.
비관론이 hyperscaler capex 의 정점을 우려할 때, 이 agent 측 demand multiplier 는 보통 thesis 안에 정량적으로 들어가 있지 않다.
2-4. Hyperscaler capex 가 메모리 capex 를 견인하는 구조
- 2026 년 4 대 hyperscaler (Microsoft·Alphabet·Meta·Amazon) 의 capex 합계는 약 USD 700 억 — 전년 대비 +77% 수준으로 추정된다 [Tom's Hardware].
- Microsoft 의 경우 단독 capex 만 USD 190억까지 가이던스가 올라갔고, 그 가운데 USD 25억은 메모리·부품 가격 상승분으로 명시되었다 [CNBC].
- 즉 hyperscaler 들이 본인 입으로 "메모리가 supply-constrained" 라고 말하고 있고, 이 상태에서 메모리 3사 (SK·삼성·Micron) 의 2026 capex 가 이를 단기간에 해소할 수 있는 규모인지가 비관론의 가정에 비해 더 보수적으로 보인다.
- TrendForce 는 의미 있는 신규 capacity 가 빨라야 2027 년 말부터 들어온다고 본다 [TrendForce 2026-01-05].
2-5. HBM4·HBM4E·HBM5 base die 의 logic 통합과 가격 premium 의 확장
HBM3E 까지의 base die 는 메모리 회사 본인 공정으로 찍었지만, HBM4 부터 base die 가 logic 공정 (Samsung Foundry 4nm·TSMC 12nm/3nm) 으로 이동한다 [TrendForce HBM4E].

- 이 변화는 단순 spec bump 가 아니라 메모리 ASP 구조 자체의 시프트다. base die 가 customer-specific logic 을 일부 흡수하면서, HBM 은 commodity 가 아니라 customizable 메모리-컴퓨팅 sub-system 으로 진화한다.
- 비관론이 "HBM 도 결국 commodity cycle 에 수렴" 한다고 보는 부분에서, 이 base die 의 logic 통합은 cycle frame 자체를 변형할 수 있다.
HBM5 부터는 wafer-to-wafer hybrid bonding 이 mainstream 으로 예상되어 진입 장벽이 한 단 더 올라간다.
3. Cycle 정점 vs 구조적 변화의 구분
비관론의 가장 강력한 무기는 메모리 cycle 의 역사다. 2017-2018 호황은 2019 보릿고개로, 2021 호황은 2023 빙하기로 빠졌다.
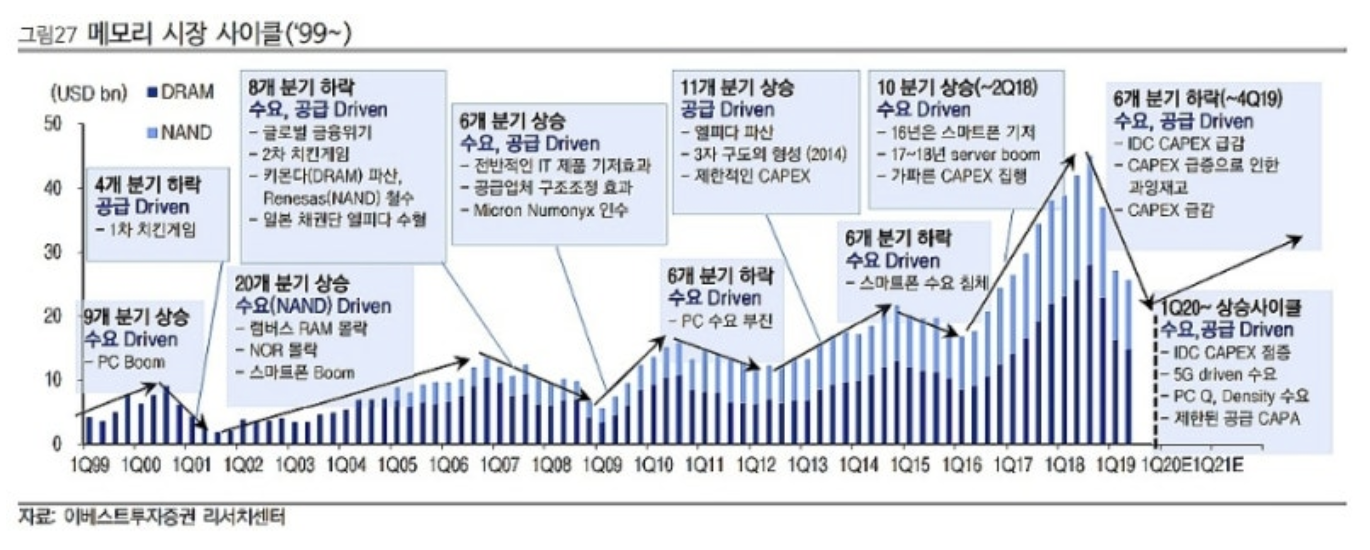
비관론이 "이번 cycle 도 다르지 않다" 고 말할 때, 한국 산업의 trauma 가 그 thesis 를 본능적으로 받아들이게 만든다.
cycle 위에 AI super-cycle 의 overlay 가 얹혔을 때, cycle 의 amplitude 와 duration 이 변형 될 수 있다. 단순 cycle frame 으로는 다음 세 가지를 설명하기 어렵다.
- 2026 1Q DRAM 계약가가 QoQ 90-95% 폭등 — TrendForce 가 측정 사상 최대 — 이 수치는 이전 어느 cycle bottom-to-peak 에서도 찾기 어렵다 [TrendForce 2026-02-02].
- Hyperscaler 들의 long-term agreement (LTA) 가 capacity 의 다수를 사전 계약 — cycle 의 spot 변동성이 LTA 로 흡수.
- HBM 의 base die logic 통합과 customization 이 진행되면서 commodity 가격 cycle 의 적용 범위 자체가 줄어듦.
비관론은 cycle 의 정점을 시간축의 한 점으로 가정하지만, super-cycle overlay 는 그 정점이 plateau 형태로 길어지거나, 정점 후 trough 가 얕아질 가능성을 허용한다. 본 글은 plateau 시나리오를 base case 로 본다.
낙관론이 틀리는 시나리오
- AI inference 수요의 정체.
- 만약 LLM 서비스 가격이 sharp 하게 하락해 inference revenue 가 더 빠르게 하락하면, hyperscaler 들의 메모리 발주는 capex plateau 보다 cliff 에 가깝게 떨어질 수 있다.
- NVFP4 quantization, KV cache offload, model distillation 의 efficiency 곡선이 demand 곡선보다 가파르게 나오면 본 글의 base case 는 무너진다.
- 중국 본토의 leading-edge 진입 가속.
- CXMT 가 현재 leading-edge 대비 약 3 년 격차로 추정되지만 (Samsung·SK·Micron 대비), 이 격차가 2 년·1 년으로 줄어드는 시점이 오면, 본토 수요는 본토 기업이 흡수하고 한국 기업은 해외 시장에서 가격 압박을 받는다.
- Hyperscaler capex 의 동시 정점.
- 4 대 hyperscaler 가 동시에 free cash flow 압박으로 capex 감속에 들어가면, 메모리 측 수요는 short-term 으로 sharp 하게 흔들린다.
- 이미 Amazon 의 free cash flow 가 2026 년 마이너스 진입 가능성이 보도되고 있고, Meta 도 capex 가이던스 상향으로 FCF 가 약 90% 하락 예상이라는 분석이 있다 [CNBC].
- 자본시장이 hyperscaler 의 capex 회수를 강하게 압박하면, 1-2 분기 내 발주 조정이 가능하다.
결론
비관론·낙관론은 같은 fact base 를 다른 weight 로 해석하고 있을 뿐이다. Chase가 보았을 때는 미래 수요의 Weight가 더 강하다.
DRAM 가격 cycle, 중국 capacity, hyperscaler capex 정점 가능성 — 모두 양쪽이 모두 인정하는 실측이다.
차이는 (i) AI inference 수요의 지속성, (ii) HBM 의 commodity / customizable subsystem 사이 위치, (iii) 한국 기업의 진입 장벽 deepening 속도, 이 세 변수의 weight 다. 본인은 이 세 변수를 비관론보다 한 단계 더 무겁게 가중한다.